



티베로 ‘InfiniData’
[아이티데일리]인터넷 이후 사람들에게 가장 큰 영향을 미칠 것으로 기대되는 것은 빅데이터다. IDC 자료에 따르면 2011년 기준 1.8 제타바이트인 디지털 데이터가 2020년에는 35 제타바이트가 될 것이라고 예상하고 있다. 10년동안 무려 20배 가까운 데이터가 폭증한다는 전망이다. 이러한 전망은 기존 DBMS 환경으로는 처리하기 힘든 데이터들이 넘쳐나게 될 것이라는 예견하고 있다. 빅데이터의 등장으로 지금까지 몇 대 규모의 분산 RDBMS 기술로 버티던 데이터베이스 시장은 거대한 구멍들을 만들었고 이러한 거대한 구멍들은 기존 DBMS가 아닌 Hadoop, Dynamo, MongoDB, Voldemort와 같은 NoSQL 솔루션들이 채울 수 있는 것처럼 보이고 있다.
이런 NoSQL 솔루션들은 드라마틱한 수평적 확장성과 싼 가격으로 빅데이터를 해결할 수 있는 유일한 대안처럼 이야기되고 있지만, 빅데이터는 그냥 단순하게 확장성만으로(물론 가장 중요한 요소이지만) 해결 가능한 것은 아니다.
이런 상황에서 국산 DBMS 전문기업인 티베로는 ‘인피니데이타’라는 대용량 데이터 처리 및 실시간 분석처리가 동시에 가능한 제품을 출시했다. 티베로 인피니데이타에 대해 살펴본다.
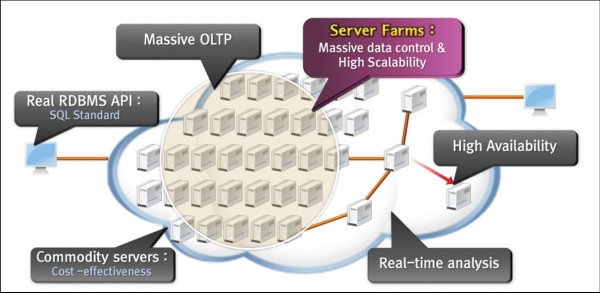
티베로 인피니데이타(Tibero InfiniData, 이하 TID)는 초기 제품 콘셉트 단계에서 빅데이터 시장의 확장성이 보장되는 정형 데이터 대응을 위한 솔루션으로 아키텍처를 설계했다. 따라서 TID의 아키텍처는 수평적 확장성을 기본으로 다양한 기능들을 보유하고 있다.
수십~수백 대의 비공유(Shared Nothing) 기반 서버팜(Server Farm)을 구성하여 누구나 쉽고 빠르게 사용 할 수 있다. 또한 준 실시간 OLTP 처리 성능 보장을 통해 엄청나게 큰 데이터 처리 시스템 구성도 대응이 가능하다.
확장성이 보장된 빅데이터 처리 기술
대량의 데이터 고속 적재 기술
TID는 외부테이블(External Table)을 이용하여 대용량 데이터 로딩 기술을 지원한다. 다양한 벤더들이 External Table을 이용하여 쉽게 로딩하는 방법을 제공하고 있는데, TID의 데이터 로딩 기술은 External Table에는 다수의 데이터가 담긴 파일 을 지정할 수 있고, 해당 파일의 PATH에 TID내부 장비 이름을 지정할 수 있다. 즉, TID 시스템 내부에 데이터 파일을 분산하여 올려놓고, 이를 이용하여 로딩할 수 있다. 뿐만 아니라 일회성 분석을 위하여 로딩을 하지 않고 일반 테이블처럼 접근하여 사용할 수 있는 기능도 제공하고 있다.
MPP(Massively Parallel Processing) 처리 기술
이미 티베로 DBMS에서 보유중인 병렬쿼리(Parallel Query) 기술을 분산된 각 노드 단위로 확장한 개념이다. 사용자는 TID 임의의 노드에 접속하여 SQL 수행을 요청할 수 있
다. 만약 임의의 노드가 SQL 요청을 받게 되면 Global Table에 대한 스키마 정보를 담고 있는 스키마 마스터 노드에 수행 계획을 요청하게 되고, 마스터 노드는 SQL 대해 TID 쿼리옵티마이저(Query Optimizer)를 이용하여 전체 수행계획을 만들게 된다.
<이하 상세 내용은 컴퓨터월드 7월 호 참조>