



정윤진 피보탈 프린시플 테크놀로지스트

[컴퓨터월드] MPP 데이터베이스란
마이크로서비스가 발달하면서 각 마이크로서비스에 할당된 문제의 해결을 위해 그 목적에 맞는 데이터 저장소의 선택이 매우 중요해졌다. 필요에 따라 적절한 데이터 저장소를 선택하고, 각 마이크로 서비스가 API 또는 메시지 버스를 사용해서 필요한 데이터를 주고받는 형태의 ‘플로우’ 구현은 점점 중요한 부분이 되어가고 있다.
MPP 데이터베이스(Massively Parallel Processing Database)는 보통 ‘데이터 웨어하우징’으로 알려진 워크로드를 처리하기 위해 자주 사용된다. 즉 수개월 또는 수년, 수십 년에 이르는 대규모의 데이터를 저장하고 일반적으로 SQL을 사용해 원하는 결과를 조회하는데 사용하곤 한다. 그리고 이 조회를 바탕으로 발견된 패턴을 모델화해서 실시간으로 유입되는 데이터에 반영하곤 한다. 대량의 과거 데이터에서 패턴을 찾아 현재 유입되는 데이터에 실시간으로 모델을 적용하는 방법을 보통 머신 러닝이라고 부르며, 따라서 MPP 데이터베이스에 저장된 데이터에 더 많은 쿼리를 수행할수록 의미 있는 모델을 찾을 확률이 더 높아진다고 할 수 있겠다.
MPP 데이터베이스의 특징은 여러 가지가 있지만, 아래와 같이 몇 가지 주요 사항을 정리해 보자.
■ 데이터를 저장할 때 디스크에 컬럼 기반으로 저장한다.
■ 일반적으로 ‘마스터’라 불리는 노드와 ‘컴퓨트’ 노드가 있다. 쿼리는 마스터에 의해 분산되어 각 컴퓨트 노드에서 실행된다.
■ 대량의 데이터 저장에 사용하므로 분산 저장 방식 및 압축 관련 성능 지표가 중요하다.
■ 데이터를 컴퓨트 노드에 나누어 저장하는데, 이 분산 저장 방법에 따라 성능이 좌우된다.
■ S3와 같이 raw 데이터를 저장할 수 있는 도구들과 연동이 가능하다.
■ 머신 러닝 또는 분석 도구와 연동이 가능하다.
데이터를 저장할 때 디스크에 컬럼 기반으로 저장한다는 것은, 일반적인 OLTP 데이터베이스와는 다른 것이다. 보통 이런 분석 기반의 데이터베이스의 경우 대량의 데이터를 다루기 때문에 데이터의 저장 효율과 분석을 위해 한꺼번에 많은 데이터를 불러오기에는 컬럼 기반의 방식이 유리하다.
온라인 트랜잭션에서는 한꺼번에 많은 데이터 보다는 특정 데이터를 빠르게 가져오는 것이 중요하기 때문에, 열(row)기반으로 데이터를 저장하는 것이 유리하다. 또한 OLTP 데이터베이스의 경우 비교적 적은 양의 데이터에 대한 입력과 수정 삭제 등이 빈번하게 발생하지만, 분석을 위한 데이터베이스의 경우 지속적인 데이터의 유입을 통해 저장된 대량의 데이터를 다루기 때문에 컬럼 기반의 저장 방식이 디스크 사용등의 측면에서 매우 유리하다.
MPP의 방식에서는 '공유 스토리지 모델'을 사용하지 않는 것이 매우 큰 차이점이다. 세월이 지나며 데이터 웨어하우징에 요구되는 규모는 테라바이트 규모에서 페타바이트를 넘어 제타바이트에 이르게 된다. 서비스에서 발생하는 이런 대규모의 데이터를 저장하기 위해서는 처음부터 수 페타바이트의 스토리지를 준비하는 것이 아니라, 데이터의 증분에 따라 함께 스토리지와 서버를 추가하는 방식이 투자 위험을 낮추는 방법이며, 훨씬 경제적이다.
여러대의 서버가 스토리지를 공유하는 모델에도 여러가지 장점이 있지만, MPP 데이터베이스에서는 이런 공유 형태보다 서버와 이 서버에 연결된 스토리지를 함께 확장하는 방식으로 클러스터의 규모를 늘려나갈 수 있다. 이런 형태의 확장을 수행하려면 '아무것도 공유하지 않는' 형태의 클러스터링 기술이 필요하다.
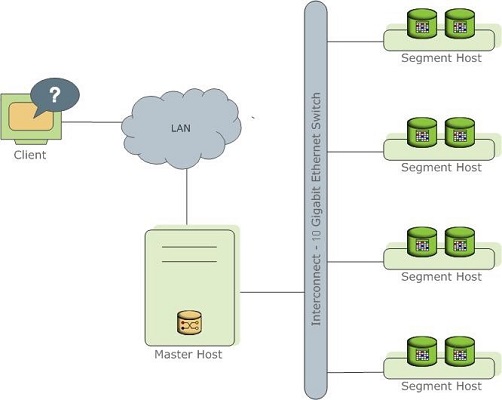
대량의 데이터를 컴퓨트 노드(또는 세그먼트 노드)에 분리해서 저장할 수 있다. 예를 들어 100만개의 데이터가 있다면, 10개의 컴퓨트 노드로 구성된 MPP 데이터베이스에서는 10만 개씩 나누어 저장하는 방식을 취할 수 있다. 이때 분석을 위한 쿼리가 마스터 노드로 유입되면, 마스터 노드는 이 쿼리의 실행을 10개의 컴퓨트 노드에 분산해서 실행하고, 그 결과를 취합해서 클라이언트에 전달하는 방식을 사용한다. 따라서 한대의 데이터베이스에서 대량의 데이터를 처리하는 대신, 10개 컴퓨터의 자원을 더 작은 수의 데이터세트에 적용하므로 훨씬 빠른 결과를 얻을 수 있는 방식이다.
하지만 이렇게 데이터를 분산해서 저장하는 방식을 취하기 때문에 주의가 필요한 부분도 있다. 특히 조인을 사용하는 경우, 데이터 저장의 분산으로 인해 필요한 데이터가 다른 컴퓨트 노드에 저장되어 있는 경우에 이 데이터 연산을 위한 복제가 발생한다. 이때 필요한 복제의 양에 따라 컴퓨트 노드간 네트워크 트래픽을 통한 IO가 발생하기 때문에 병목이 될 수 있다.
따라서 MPP 데이터베이스들은 테이블을 생성하는 경우 이 테이블에 적용할 분산 저장 방식을 제공한다. 보통 분산 키(Distribution Key)를 지정하거나, 분산 저장 방식에 ‘모든 노드에 저장’ 또는 ‘랜덤 노드에 저장’ 그리고 ‘동일하게 나누어 저장’과 같은 방식을 제공한다. 이 저장 방식에 따라 성능이 크게 좌우 되며, 디스크 사용 효율에 중요한 영향을 미치므로 스키마 설계 단계에서 주의를 기울여야 하며, 필요한 경우 테이블을 재구성 하는 등의 방식으로 지속적으로 성능을 개선해야 할 필요가 있다. 여느 분산 데이터베이스가 그렇듯, 분산 키의 지정에 따라 데이터 저장의 편차가 발생하기 마련이며, 이 편차를 줄이기 위한 키 선택을 잘 하는 것이 중요하겠다.
최근 데이터를 다루는 방법은 크게 생성과 취합, 저장과 분석의 흐름을 어떻게 구성하는가에 따라 할 수 있는 것이 매우 달라진다고 볼 수 있다. 이 데이터 흐름의 연결, 즉 파이프라인을 어떻게 구성하는가에 따라 다양한 데이터 활용이 가능하다. 자주 보이는 패턴중 하나는, 데이터가 생성되는 소스로 부터 카프카와 같은 스트림 도구로 데이터를 받아 필요한 애플리케이션에서 이 데이터를 카프카로부터 가져다가 목적에 따라 사용하는 구성을 취하는 것이다.
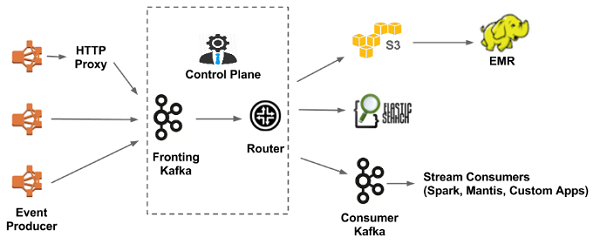
카프카와 같은 도구를 사용하는 것의 장점은, 하나의 데이터 소스로 부터 받은 스트림 데이터를 다양한 애플리케이션에서 가져다 사용할 수 있다는 것이다. 예를 들어 웹서버에서 생성되는 로그 스트림을 카프카에 넣게 되면, 여기에 대시보드 애플리케이션, 실시간 분석, 필터 적용, 또는 스트림 데이터를 모아서 오브젝트 스토리지나 데이터 웨어하우징 데이터베이스에 저장할 수 있는 일을 동시에 처리할 수 있는 것이다.
위의 그림에서도 볼 수 있듯, 넷플릭스에서는 이런 형태의 데이터 파이프라인 구현을 통해 다양한 목적으로 데이터를 활용한다. 심지어 카프카에 들어온 데이터를 다시 다른 카프카 클러스터에 연결해서 사용하는 구성 방식을 취하기도 한다.
MPP 데이터베이스에 데이터를 저장할 때는, OLTP와 같이 스트림으로 들어오는 튜플(tuple), 즉 데이터를 한건씩 저장하는 방식을 취하는 것이 매우 비효율 적이다. 따라서 일종의 쓰기 버퍼와 같은 역할을 해주는 도구가 함께 사용되는 것이 좋은데, 유입되는 데이터를 잃지 않으면서도 높은 성능으로 처리할 수 있는 방법이 바로 이 카프카와 오프젝트 스토리지 또는 HDFS를 함께 사용하는 방식이다. 클라우드 환경을 사용한다면 다양한 오브젝트 스토리지를 선택할 수 있는데, 신뢰성이 높다고 알려진 S3와 연동을 제공하는 MPP 데이터베이스가 많다.
웹서버에서 생성된 로그 스트림은 카프카 어펜더(kafka appender)를 통해 카프카에 전달한다. 여기에 다른 대시보드 또는 실시간 분석용 애플리케이션을 컨슈머로 붙일 수도 있겠지만, 이후 데이터 분석을 위해 유입된 데이터를 S3로 저장할 수 있다. 이렇게 저장된 데이터는 MPP 데이터베이스의 컴퓨트 노드들에서 직접 접근해 병렬로, 또한 고속으로 데이터를 적재할 수 있다. 적재 뿐만 아니라 MPP 데이터베이스에 저장된 데이터를 다시 S3로 내릴 수도 있으며, 반드시 적재가 필요하지 않은 경우에는 ‘외부 테이블’ 로 명시해서 사용하는 방법도 제공한다.
클라우드 환경을 사용할 수 없는 경우에는 하둡이나 파일 시스템으로 부터의 데이터 로드를 지원한다. 역시 각 컴퓨트 노드가 병렬로 원본 데이터 소스에 접근할 수 있다면, 매우 고속으로 데이터 적재를 수행할 수 있다.
다양한 사용 사례에서, 데이터 레이크(Data lake)의 구현을 생각해 볼 수도 있다. 데이터의 생성과 수집 부분을 지나, 저장에 있어 하둡이나 S3를 사용한다. 그리고 필요에 따라 MPP 데이터베이스 클러스터를 다양한 목적으로 만들어서 데이터를 적재한다.
이렇게 MPP 데이터베이스에 저장된 데이터는 다양한 목적으로 분석에 활용된다. 금융분야에서는 사용자의 금융 거래 패턴이나 부정 사용 패턴등을 살펴볼 수 있다. 제조분야에서는 생산 과정에서 발생한 다양한 데이터를 통해 공정 효율 개선이나 장비 불량의 예측 모델을 만드는데 사용하기도 한다. 즉, 단순히 BI 레포트를 위해 사용하는 것에 그치지 않고 이를 바탕으로 머신 러닝 모델을 만든다. 따라서 최근의 MPP 데이터베이스들은 머신 러닝 도구와 연동할 수 있는 능력을 함께 제공한다.
맵-리듀스 라고 알려진 데이터의 분석 방법은 전혀 새로운 것이 아니다. 배치 프로세싱을 통해 수행해 왔던 다양한 작업들은 오래 전부터 활용되어 왔던 것들이다. 그리고 이런 분산 처리에는 언제나 큐(queue), 마스터, 컴퓨트와 같은 개념들이 존재한다. MPICH를 활용한 수퍼 컴퓨팅이나, 전 세계의 놀고있는 컴퓨터 자원을 활용할 수 있도록 디자인된 BOINC와 같은 도구들이 개념적으로는 다 유사하다고 볼 수 있다.
MPP 데이터베이스는 이런 방식으로 SQL을 사용할 수 있으며, 대량의 데이터를 압축 저장하고 필요에 따라 클러스터 규모를 늘려갈 수 있는 형태의 데이터베이스다. 여기에는 잘 알려진 데이터베이스들이 있지만, 본 기고문에서 언급한 기능성을 제공하는 것은 크게 아마존 레드시프트(Amazon Redshift)와 피보탈의 그린플럼(Pivotal Greenplum)이다.
아마존 레드시프트는 관리형 서비스이므로, 관심이 있는 사람은 아마존 웹 서비스를 통해 원하는 규모의 클러스터를 즉시 만들어 사용해 볼 수 있겠다. 피보탈 그린플럼은 베어메탈 서버, 가상 머신, 심지어 컨테이너로도 제공되므로, MPP 데이터베이스를 로컬호스트나 워크스테이션, 아마존 웹 서비스 또는 쿠버네티스 클러스터에서도 사용이 가능하다. 또한 오픈 소스로 공개되고 있으므로 동작 방식에 대한 연구나 테스트, 옵티마이저의 구동 방식 등이 궁금하다면 언제나 코드를 참조할 수 있다.
오픈소스 MPP, 그린플럼
그린플럼(Greenplum)은 이 분야에 있어서 아마도 가장 접근이 쉬운 데이터 웨어하우징 도구가 아닐까 한다. PostgreSQL 기반의 데이터 웨어하우징을 위한 데이터베이스로서, 몇 년 전에 오픈소스로 전환되었다. 그린플럼 홈페이지(https://greenplum.org/)에서는 오픈소스 그린플럼이 아파치2 라이센스로 제공된다고 밝히고 있다.
일반적인 MPP 데이터베이스가 제공하는 장점들에 더하여, 그린플럼은 몇 가지 추가적인 (하지만 한국에서는 잘 알려지지 않은) 기능을 제공한다. 그중 강력한 두 가지는 PivotalR과 Apache MADlib이다.
이 글에 관심이 있는 분이라면 아마도 R을 익히 들어보셨을 것 같다. 분석에 자주 사용되는 R은 수많은 데이터 전문가들에게 사랑받아 왔다. 하지만 가장 큰 한계를 하나 꼽아 보면, 처리해야 하는 데이터 세트의 양이 많아질수록 언젠가는 메모리 한계에 도달한다는 점이다. PivotalR 은 정확히 이 문제를 해결한다. 데이터를 GPDB에 저장하고 있다면, PivotalR은 R을 SQL로 변환한다. 이 SQL을 받은 GPDB는 저장된 대규모의 데이터에 대해 병렬로 SQL을 수행한다.

R 코드 처리를 위해 별도의 데이터 이동이 전혀 필요하지 않으며, 동시에 분산으로 처리해서 수행되기 때문에 상당히 높은 성능을 기대할 수 있다. 다양한 데이터 분석 프로젝트들이 단순히 데이터를 GPDB에 적재하는 것 만으로도 큰 효과를 볼 수 있다. 즉 R에 익숙한 사용자라면 즉시 그린플럼에 저장된 데이터를 R클라이언트를 통해 사용할 수 있다는 것이다.
아파치 매드립(Apache MADlib)은 데이터베이스에 머신 러닝을 위한 기능을 추가할 수 있는 오픈 소스 라이브러리다. PivotalR과 함께 그린플럼에 강력한 확장성을 제공한다. 홈페이지는 http://madlib.apache.org/ 이며, 주피터 노트북(Jupyter Notebooks)를 사용한 ‘시작해 보기’를 통해 사용 방법을 확인해 볼 수 있다.
수학, 통계, 머신 러닝, 그래프 분석, 데이터 변환 등을 아우르는 굉장히 풍부한 분석 방법을 제공한다. PivotalR과 함께 그린플럼에서 사용하게 되면 이를 대량의 데이터에 대해 병렬로 사용할 수 있는, 그야말로 환상적인 성능을 보여준다.
그린플럼 사용해 보기
클라우드, 그리고 가상화와 컨테이너가 제공하는 최근의 환경은 지난 세월에 비추어 보면 정말 놀랍다고 할 수 있다. 별도의 서버나 컴퓨터 자원 없이 다양한 도구들을 정말 순식간에 준비해서 사용하는 것이 가능하기 때문이다. MPP 데이터베이스를 개발자나 데이터과학자의 로컬 머신에서 (인터넷만 연결되어 있다면) 즉시 준비하고, 바로 클라이언트 도구와 연결해서 사용하는 것이 가능하다.
그린플럼은 일반적으로 GPDB 라는 약어로 자주 사용된다. 오픈 소스인 GPDB는 깃헙에 코드가 존재한다. 다음의 링크에 방문하면 GPDB의 코드를 살펴볼 수 있다.
■ https://github.com/greenplum-db/gpdb
또한 GPDB는 그린플럼 공식 웹페이지를 통해 다운로드 받거나, 우분투의 경우 apt 명령어를 통해 설치할 수 있다. 아래의 링크에서는 아파치 빅탑(Apache Bigtop), 우분투, 도커 이미지의 위치와 사용 방법을 참고해 볼 수 있다.
■ https://greenplum.org/download/
아마존 마켓플레이스를 사용하는 방법도 있다. 아래의 링크에서는 오픈소스 버전의 그린플럼을 즉시 사용해 볼 수 있는 아마존 마켓플레이스를 살펴볼 수 있다. 애석하게도 서울 리전이 지원되지 않는데, 이 경우에는 우분투 머신을 EC2로 준비해서 위의 설치 방법에 따라 사용해 볼 수 있을 것이다.
■ https://aws.amazon.com/marketplace/pp/B01LFMOXUE/ref=mkt_ste_catgtm_dblp
아래에 소개되는 컨테이너 방식이 마음에 들지 않는다면, 가상 머신을 사용할 수도 있다. 가상 머신에 직접 그린플럼을 준비할 수도 있으며, 경우에 따라서는 다음 링크의 그린플럼 샌드박스를 직접 사용할 수도 있다. 링크에서는 샌드박스용 이미지 뿐만 아니라 그린플럼의 기본 사용 튜토리얼도 함께 제공하고 있다. 해당 페이지 하단의 ‘튜토리얼 메뉴’ 드롭다운 버튼을 누르면 메뉴가 확장된다.
■ https://greenplum.org/gpdb-sandbox-tutorials/
또한 그린플럼 도커 이미지를 바탕으로 즉시 실행해 볼 수 있다. 아래의 링크에서 도커 환경을 다운로드 받을 수 있다. 도커 에지 릴리즈(Docker Edge Release)를 다운로드 받으면 별도의 설치 없이 쿠버네티스 환경을 구성하는 것도 가능하다.
■ https://www.docker.com/get-docker
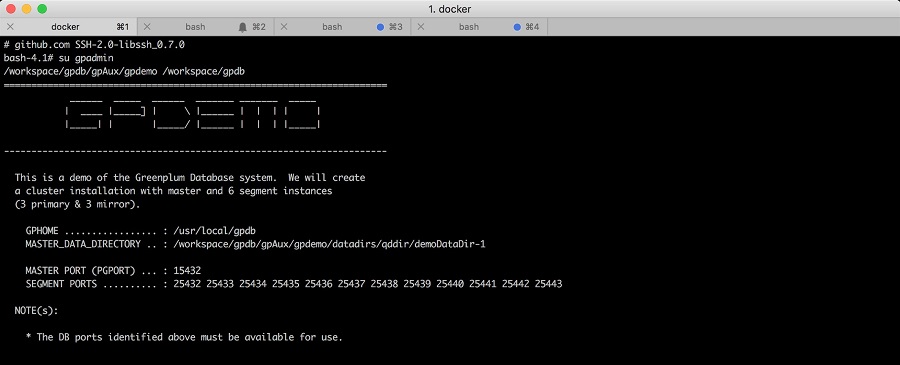
이미 도커 환경이 설치되어 있다면, 아래의 커맨드로 그린플럼을 즉시 구동할 수 있다. 만약 버추얼 머신이 대상 시스템에 준비되어 있다면, docker-machine을 사용해서 버추얼 박스 환경에서 아래의 예제를 사용해 볼 수 있겠다. 버추얼 박스가 없다 하더라도 시스템에 도커 환경이 준비되어 있다면 바로 docker run 커맨드를 사용하면 되겠다.
| 버추얼 머신 생성 - 너무 많은 자원을 할당하지 않도록 주의하자 $ docker-machine create -d virtualbox --virtualbox-cpu-count 2 --virtualbox-disk-size 50000 --virtualbox-memory 4096 gpdb 생성된 환경 확인 도커를 위한 시스템 환경 변수 설정 gpdb-devel 도커 이미지 구동 클러스터 생성 - gpadmin 계정을 활성화 하는 순간, 설치 확인 // 꽤 오래 걸리므로 반드시 수행할 필요는 없다. 데이터베이스 생성과 접속 |
위의 명령어들이 문제 없이 실행되었다면 그린플럼이 컨테이너 환경에 준비된 것이다. 기본적으로 도커 환경이므로 쿠버네티스 환경에 배포해 볼 수도 있다. 실 서비스 수준의 쿠버네티스 환경을 보유하고 있다면, 다수의 노드로 구성된 고가용을 지원하는 그린플럼을 사용할 수도 있다.
| 데이터베이스 생성 $ createdb creditcard PL/Python 지원 활성화 그린플럼의 creditcard 데이터베이스에 접속 (데몬을 사용한다면 psql 클라이언트를 사용하면 된다) |
데이터베이스 이름 = # 기호가 나타난다면 데이터베이스에 접속한 상태다. 기본적으로 dt 와 같은 PostgreSQL 명령어를 사용할 수 있으며, 접속 해제는 q 커맨드를 사용하면 된다. PL/Python 지원을 활성화 했기 때문에 아래와 같이 사용자 정의 함수를 만들어 사용하는 것도 가능하다.
| creditcard=# CREATE FUNCTION return_py_int_array() RETURNS int[] AS $$ return [1, 11, 21, 31] $$ LANGUAGE plpythonu; CREATE FUNCTION creditcard=# SELECT return_py_int_array(); |
피보탈 엔지니어링 블로그(http://engineering.pivoal.io)에는 그린플럼과 관련된 다양한 데이터 사이언스 예제를 찾아볼 수 있는데, 아래 링크에는 그린플럼에서 케라스와 텐서플로우를 사용해서 대규모로 확장 가능한 스코어링 방법을 살펴볼 수 있다.
■ http://engineering.pivotal.io/post/scoring-at-scale-with-keras-and-tensorflow-on-pivotal-greenplum/
전체 내용을 소개하는 것은 본 기고문의 범위를 넘어가는 것이므로 더 깊게 들어가지는 않겠으나, 이 부분에 관심이 있는 분들이라면 간단한 딥러닝 처리를 위해 MPP 데이터베이스의 컴퓨트 노드에서 케라스와 텐서플로우가 어떻게 연동할 수 있는지에 대한 아이디어를 얻을 수 있을 것이다. 이 포스트의 모든 내용을 그대로 사용해 보기 위해서는 도커 이미지의 python 버전을 업그레이드 해야 하는 등의 추가 작업이 필요하다는 점을 알아두도록 하자.
위의 블로그 포스트에 소개된 샘플 데이터는 아래의 링크에서 구할 수 있다. Kaggle 페이지에서 데이터를 받기 위해서는 로그인이 필요할 수 있다.
■ https://www.kaggle.com/mlg-ulb/creditcardfraud
creditcard.csv 파일을 성공적으로 내려 받았다면, 아래와 같이 테이블을 만들고 CSV 데이터를 로드할 수 있다. 아래의 CREATE TABLE 구문을 실행한다.
| CREATE TABLE credit_card( Time NUMERIC, -- seconds elapsed between each transaction V1 NUMERIC, -- first principal component V2 NUMERIC, -- second principal component V3 NUMERIC, -- third principal component V4 NUMERIC, V5 NUMERIC, V6 NUMERIC, V7 NUMERIC, V8 NUMERIC, V9 NUMERIC, V10 NUMERIC, V11 NUMERIC, V12 NUMERIC, V13 NUMERIC, V14 NUMERIC, V15 NUMERIC, V16 NUMERIC, V17 NUMERIC, V18 NUMERIC, V19 NUMERIC, V20 NUMERIC, V21 NUMERIC, V22 NUMERIC, V23 NUMERIC, V24 NUMERIC, V25 NUMERIC, V26 NUMERIC, V27 NUMERIC, V28 NUMERIC, -- twenty-eighth principal component Amount NUMERIC, -- transaction amount Class NUMERIC -- the actual classification classes ) WITH ( APPENDONLY=TRUE, COMPRESSTYPE=zlib, COMPRESSLEVEL=5 ) DISTRIBUTED RANDOMLY; CREATE TABLE |
테이블이 성공적으로 만들어졌다면, 다운로드 받은 CSV 파일을 테이블에 적재해 보자.
현재 그린플럼 도커 컨테이너의 gpadmin 계정으로 작업하고 있다는 사실을 잊지 말고, 다운로드 받은 파일을 해당 계정이 접근할 수 있는 위치에 넣어야 한다. 여기에서는 /tmp 디렉토리를 사용했다.
| creditcard# COPY credit_card FROM '/tmp/creditcard.csv' CSV HEADER; COPY 284807 |
데이터가 테이블에 적재 되었다면 성공이다. 아래는 PL/Python stack_rows 함수를 생성한다.
| CREATE FUNCTION stack_rows( key text, header text[], -- name of the features column features float8[] -- independent variables (as array) ) RETURNS text AS $$ if 'header' not in GD: GD['header'] = header if not key: gd_key = 'stack_rows' GD[gd_key] = [features] return gd_key else: GD[key].append(features) return key $$ LANGUAGE plpythonu; CREATE FUNCTION # 커스텀 에그리게이션을 생성한다. CREATE ORDERED AGGREGATE stack_rows(
|
케라스와 텐서플로우, h5py(모델을 로드하기 위해 필요)가 모두 그린플럼 세그먼트(그린플럼에서의 컴퓨트 노드)에 설치되어 있는 경우에는 아래와 같이 score_keras() 함수를 만들어 그린플럼의 각 노드에서 딥러닝을 위한 분산처리가 동작하는 모습을 확인할 수 있을 것이다.
텐서플로우 설치, pip install keras, pip install h5py 를 사용해 그린플럼의 각 노드가 준비된 경우, 아래와 같이 텐서플로우를 사용하는 score_keras 함수를 만들 수 있다.
| CREATE OR REPLACE FUNCTION score_keras( _model text, _data_key text ) RETURNS SETOF INTEGER[] AS $$ # Begin: Workaround to import TensorFlow import sys sys.argv = {0: ""} if 'model' not in SD: result = None return result
|
이렇게 만들어진 함수는 아래와 같은 쿼리를 통해 호출해서 사용할 수 있다.
| WITH cached_data AS ( SELECT gp_segment_id, stack_rows( ARRAY['features'], -- header or names of input fields ARRAY[v1, v2, v3, v4, v5, v6, v7, v8, v9, v10, v11, v12, v13, v14, v15, v16, v17, v18, v19, v20, v21, v22, v23, v24, v25, v26, v27, v28] -- feature vector ) AS stacked_input_key FROM credit_card GROUP BY gp_segment_id ) SELECT
|
텐서플로우 테스트가 가능한 그린플럼 도커 이미지를 직접 만들어 배포하고자 했으나, 도커 이미지 작업에 생각보다 오랜 시간이 걸려 마감 시한을 놓치게 되었다. 가상 머신 기반으로 그린플럼 환경을 구축한다면 위의 테스트를 보다 쉽게 진행할 수 있으리라 생각한다. 아울러 컴퓨터월드의 독자 분들을 위해 다음번에는 소개된 데모에 대해 더 깊게 살펴보도록 하겠다.
마치며
딥러닝, 머신러닝과 관련해서 다양한 분석 도구가 존재한다. 필요에 따라서, 그리고 데이터의 처리 형태에 따라서 적절한 도구를 선택하는 것이 어느 때보다 중요한 시대다. 그리고 만약 데이터 도구를 처음에 잘못 선택했더라도, 경험을 바탕으로 올바른 도구로 다시 바꾸거나 실험할 수 있는 환경을 조성하는 것이 매우 중요하다. 이런 측면에서, 카프카와 같은 도구의 존재는 단비와 같다.
데이터가 발생하는 소스에 카프카를 연결할 수 있는 상태가 되면, 그 뒤에는 다양한 확장이 가능하다. 각 서버에서 떨어지는 수많은 데이터 또는 다양한 IoT 기기에서 발생하는 데이터를 모아서 오브젝트 스토리지에 저장하거나, 스파크와 같은 실시간 분석 도구를 연결하거나, 실시간 대시보드를 연결할 수도 있다. 이는 카프카가 제공하는 기능으로, 하나의 데이터 소스에서 만들어진 데이터를 다수의 애플리케이션이 사용할 수 있도록 한다.
이런 ‘데이터 플랫폼’을 일단 확보했다면, 이후에는 데이터의 분석과 처리 용도에 맞는 도구의 선택이 가능하다. 여기에 이 오픈소스 데이터 웨어하우징 도구를 사용할 수 있으며, 이는 보통 ‘오랜 기간에 걸친 서비스의 트렌드 분석’과 같은 곳에 사용할 수 있다. 10년 동안의 사용자별 은행 계좌 이용 패턴을 찾아내고, 모델을 만드는데 사용할 수 있을 것이다. 각각의 모델은 더 많은 데이터가 존재할수록 더 정교해지고, 이 모델은 다시 실시간으로 유입되는 데이터와의 비교에 사용할 수도 있을 것이다.
로컬에서 사용해 볼 수 있는 데이터 웨어하우징 도구는, 다양한 쿼리의 학습과 동작 방식을 확인하는데도 유리할 것이다. 또한 데이터베이스를 대상으로 테스트를 구현하는 경우에도 도커 이미지를 가져다가 손쉽게 사용할 수도 있을 것이다. 오픈소스로, 그리고 가상머신이나 도커를 사용해서 DW를 사용하는 방법에 대해 소개하고, 아울러 매트립이나 PivotalR 과 같은 도구의 소개를 통해 다양한 데이터 분석의 환경을 실험해 볼 수 있기를 바란다.