



빅데이터 분석 환경에서의 비정형 데이터 활용 가치 극대화
[컴퓨터월드] 빅데이터 중 80% 이상을 차지하는 비정형 문서에서 필요한 정보를 찾기 위한 기업들의 요구는 날로 증가하고 있다. 또한 범람하는 문서에서 개인정보 보호를 규제하는 움직임 또한 활발하다. 빅데이터에서 주요 정보를 추출하고 이를 선별하는 이슈에 대한 요구가 높아가고 있는 것이다. 데이터 중심 비즈니스의 성과를 높이고자 하는 기업들은 위의 두 가지 측면에 대한 기능과 성능을 지원하는 솔루션에 주목하고 있다.
데이타솔루션의 ‘에이너(AI.NER)’는 모든 유형의 데이터에서 필요한 정보의 추출과 선별 및 이에 대한 개인정보 비식별화를 지원하는 솔루션이다. 인공지능 기술이 접목된 에이너(AI.NER : Artificial Intelligence . Named Entity Recognition)는 텍스트 데이터의 주요 정보 처리과정에 사전 및 패턴처리가 활용되던 기존 방식에 언어처리 기술에 대한 기계학습모델을 강화시킨 지능형 비식별화 솔루션이다.
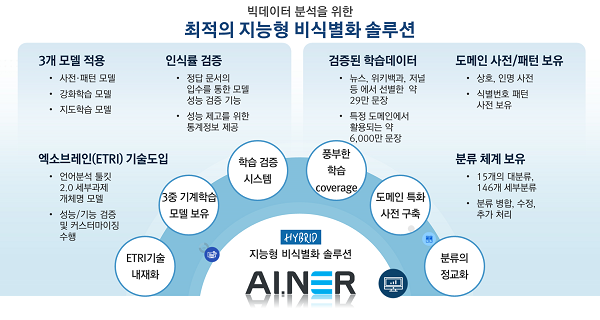
‘에이너’는 사전〮패턴 모델외에 기계학습(지도 및 강화학습)모델 중심의 하이브리드 모델을 적용했으며, 엑소브레인(ETRI) 기술 도입과 함께 추출된 키워드의 분류체계를 정교화 했다. 또한 기계학습을 위해 뉴스, 위키백과, 저널 등에서 선별한 약 29만 문장을 학습데이터로 활용했으며 검증 및 성능 제고를 위한 재학습과 인식률 검증 기능을 갖고 있다.
특히 비식별 처리와 관련, 기존 제품들은 이미 정의된 필드 혹은 구조화 되어있는 데이터의 비식별 처리 방식에만 초점을 두었으나, ‘에이너’는 정형화 되어 있지 않은 데이터(일반 문서, 보고서 파일 등)에서도 비식별화 할 대상을 찾아 처리함으로써 적용 대상 범위가 매우 넓다.
1. 에이너(AI.NER)의 기본 구성
1) 데이터 입수 단계
데이터의 종류 및 특성에 따라 구조화된 형태의 데이터로 가공하는 과정이다. DB, 전자문서, HTML, XML 등 모든 형태의 데이터가 여기에 포함된다. 만약 입수된 문서가 학습이 가능한 형태의 데이터라면 학습모델 생성기와 연계해 신규로 학습모델을 생성하거나 기존 학습모델에 추가해 재학습을 수행한다.
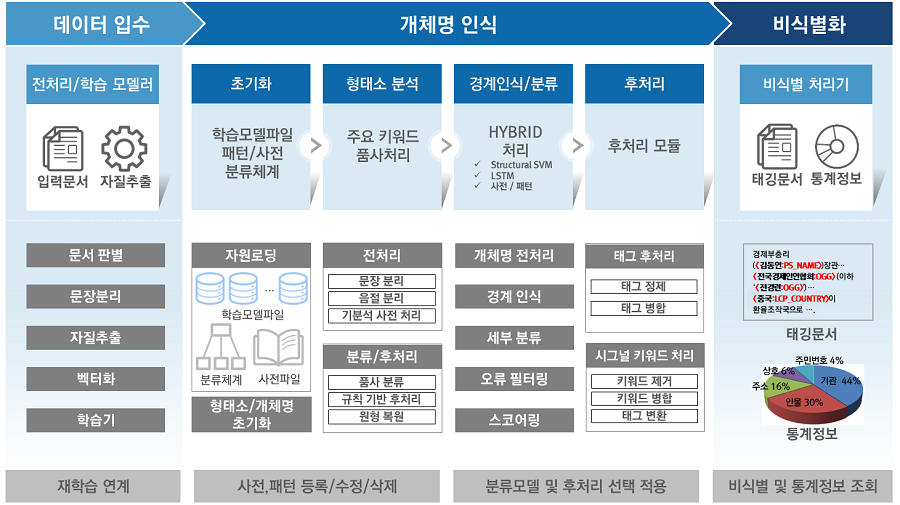
2) 정보 추출 및 선별 단계
기계학습모델 기반의 언어처리 기술을 중심으로 주요정보를 추출 및 선별하는 과정이다. 학습모델파일, 분류체계, 사전〮패턴 등의 자원을 기반으로 전처리 및 언어처리(형태소 분석, 개체명 인식)를 통해 주요정보를 추출한 후 하이브리딩 및 스코어링 과정을 거처 정보를 최종 선별한다. 선별된 키워드 정보는 분류태그, 키워드 명, 위치 등 통계 자료를 포함하는데 태그 정제, 병합 및 선별된 키워드의 전/후 시그널 키워드 처리 등 후처리 모듈을 통해 최종 처리된다.
3) 비식별화 처리 단계
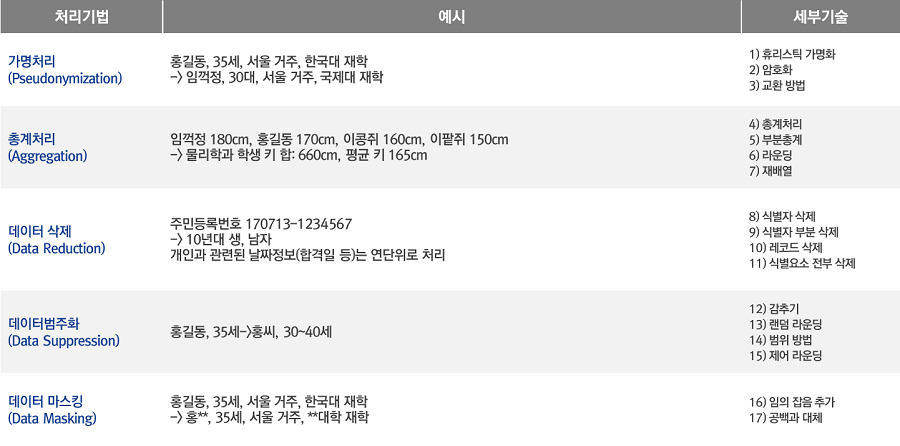
최종 선별된 분류 태그와 키워드 정보를 바탕으로 비식별화 대상이 되는 주요 정보를 비식별처리하는 단계이다. 일반적으로 비식별화 대상이 되는 정보는 개인으로 식별될 수 있는 직간접적인 정보를 말하는데 이름, 소속기관, 지역 정보부터 식별 가능한 번호(주민번호, 계좌번호, 카드, 전화번호 등)를 가명처리(Pseudonymization), 총계처리(Aggregation), 데이터 삭제(Data Reduction), 데이터 범주화(Data Suppression), 데이터 마스킹(Data Masking) 처리를 수행한다.
2. 기술적 특장점
‘에이너’는 기계학습기반의 분석모듈을 탑재하고 있어 기존 모델에 비해 성능이 향상됐다. 또한 정교한 분류 체계 및 모듈 단위 재사용으로 다양한 텍스트 분석 환경에서 활용이 가능하다.
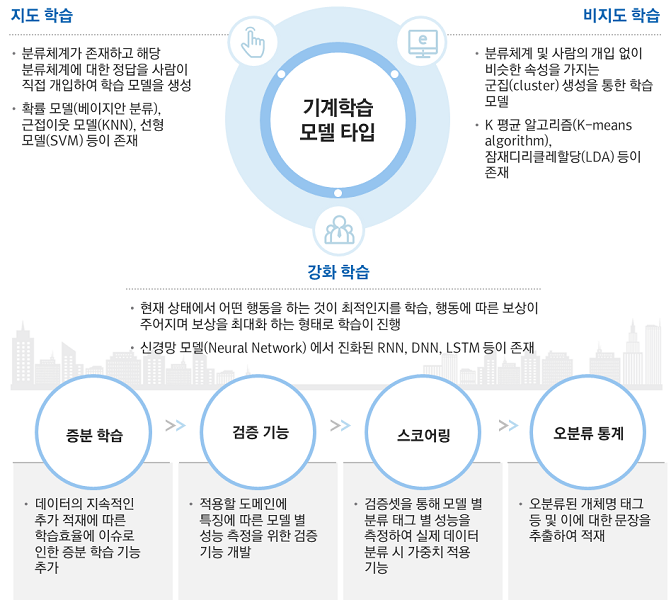
1) 하이브리드 처리를 위한 기계학습 모델
기계학습은 딥러닝 모델에 이르기까지 기술이 진화했으며 언어처리에 특화된 모델도 등장했다. ‘에이너’는 Structural SVMs(선형학습모델: 지도학습), Bidirectional LSTM(딥러닝학습모델 : 강화학습) 두 가지 모델이 적용됐으며, 모델 검증기능을 통해 선택적으로 사용하거나 두 모델을 사용하는 하이브리드 처리가 가능하다.
1
2) 정교한 분류체계 및 학습데이터
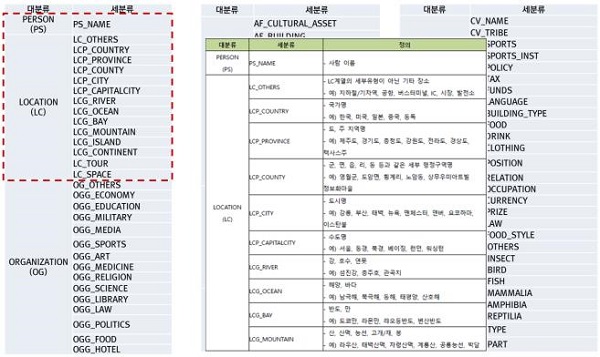
‘에이너’에는 키워드를 분류하기 위한 다양한 분류체계를 지원한다. 15개의 대분류(인명, 지역명, 기관명, 학문, 이벤트 등)와 각 대분류 별 총 146개의 세부 분류가 가능해 추출된 키워드에 대한 분류 명칭을 통해 다양한 분석 활용이 가능하다.
1
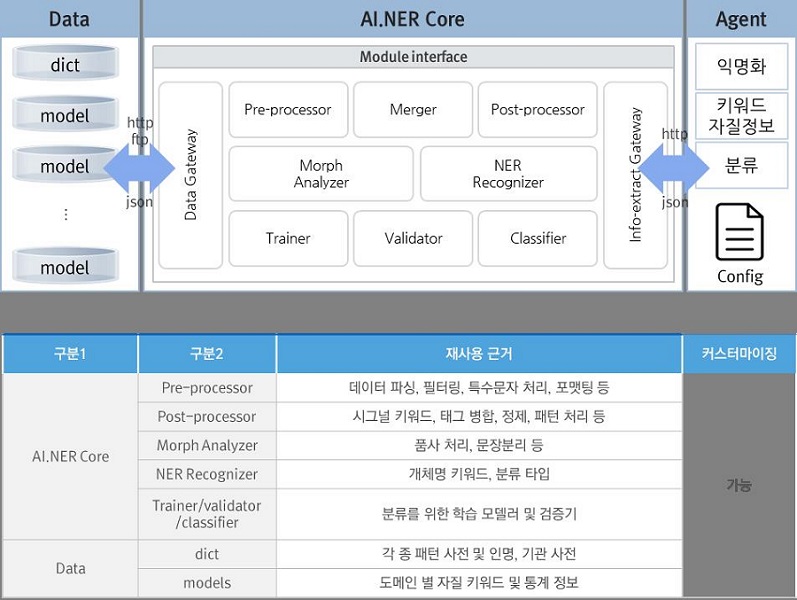
3) 모듈 단위 재사용 구조
데이터의 입수, 정보 추출 그리고 선별, 비식별화 등 각 단계별로 모듈 단위로 구성돼 있다. 텍스트 데이터의 전처리 모듈, 분류 및 검증 모듈, 언어처리 모듈 등 텍스트 분석에 필요한 기반 모듈들이 API 형태로 제공된다.
4) 관리기능 탑재
‘에이너’는 관리도구를 통해 비식별 테스트, 사전〮패턴 관리 및 통계 정보를 제공한다.
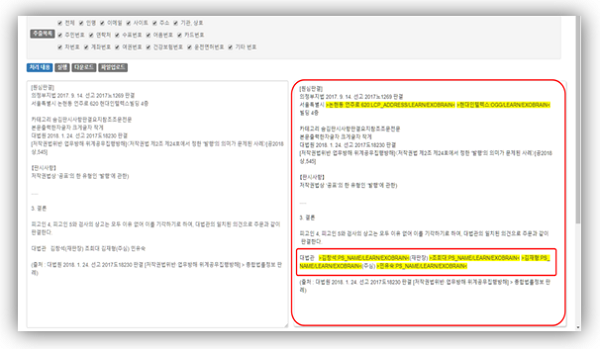
테스트하고자 하는 문서를 입력해 변환된 문서를 확인할 수 있다. 추출하려는 명칭과 학습모델 선택 등으로 의도하는 문서를 볼 수 있으며, 정보를 다운로드할 수도 있다.
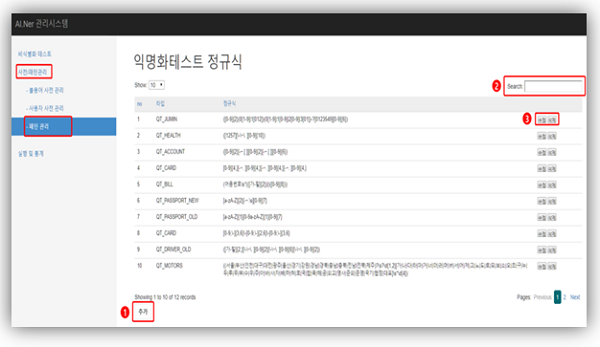
신조어, 신규패턴 등 누락된 정보를 즉시 반영할 수 있도록 각 명칭 별 사전 및 패턴 처리가 가능하도록 구성돼 있다. 또한 관리도구에서 수정/등록/삭제하거나 형식에 맞게 파일을 export할 수 있다.
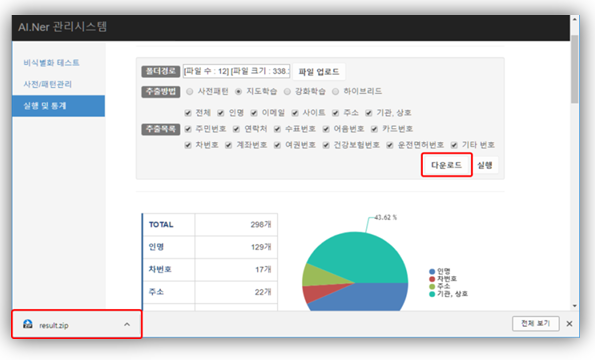
입수된 문서들에서 추출된 명칭들에 대한 통계확인이 가능하다. 정답문서를 기반으로 사전〮패턴과 학습모델 별로 정확률을 확인하여 수정 보완할 수 있는 검증 관리기능을 갖고 있다.
3. 제품의 활용 분야 및 적용 효과
직접적으로 개인을 식별할 수 있는 식별자, 다른 정보화 결합하여 개인을 식별할 수 있는 준식별자 그리고 개인의 사생활을 드러낼 수 있는 민감정보 등이 포함된 데이터를 다루는 모든 영역에서 활용할 수 있다. 또한 선별된 정보의 추출 기술이 기반이 되는 텍스트 분석 영역, 대화형 커뮤니케이션 자동화 등의 영역에서도 활용 가능하다.
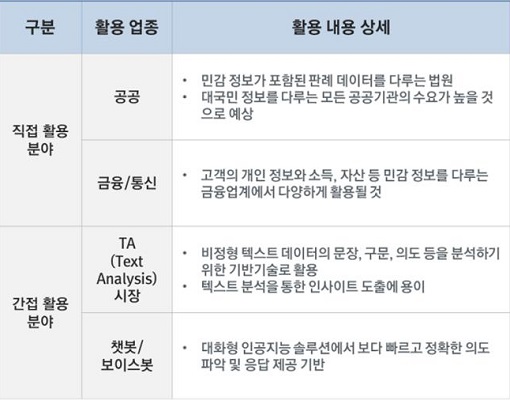
‘에이너’는 실제 대법원 판결의 공개 시스템에 도입돼 서비스되고 있다. 데이타솔루션은 ‘에이너’와 관련, 공공뿐만 아니라 민간기업에서 필요한 모듈을 더욱 고도화해 공급할 계획이며, 이를 기반으로 지능형 기업보고서 자동생성 솔루션도 개발한다는 방침이다.