



가명처리 등 비식별 조치 명시화…비식별화 솔루션 수요 확대
[컴퓨터월드] 지난 1월 국회에서 데이터 3법이 통과됨에 따라 데이터 산업이 활성화될 것으로 기대되고 있다. 특히 비식별 조치가 된 개인정보를 산업적 통계 등 연구 목적으로 명시적 동의 없이 활용할 수 있게 되면서 데이터의 활용도가 높아질 것이 확실시된다. 또한 비식별 조치 중 가명정보가 명시됨으로써 활용되는 데이터의 품질도 크게 향상될 것으로 보인다.
데이터 3법에서 주목해야 할 점은 개인의 명시적 동의 없이 연구 목적으로 사용하기 위해서는 비식별 조치가 이뤄져야 한다는 것이다. 이런 이유로 비식별화 시장 역시 급성장할 것으로 기대된다. 오는 8월 데이터 3법이 시행되면, 국내에서도 데이터 활용을 위한 비식별 조치가 활성화될 것이라는 전망이다. 데이터 3법으로 인한 개인정보 비식별화 시장에 대해 전망해본다.
데이터 활용 위한 비식별 조치 법제화
지난 1월 데이터 업계의 숙원이었던 데이터 3법(개인정보보호법 개정안, 신용정보법 개정안, 방송통신망법 개정안)이 국회에서 통과됐다. 데이터 3법 개정안에서는 데이터 활용을 위한 가명정보 개념 도입, 비식별 조치 후 산업적 통계 등 연구 목적 활용, 개인정보보호위원회 격상 등이 법제화됐다.
사실 국내에서 데이터 활용을 위한 움직임은 2016년에도 있었다. 2016년 6월 국무조정실, 행정자치부(現 행정안전부), 방송통신위원회, 금융위원회, 미래창조과학부(現 과학기술정보통신부), 보건복지부 등 관계부처가 합동으로 당시 개인정보보호 법령 내에서 빅데이터를 안전하게 활용할 수 있도록 비식별 조치 기준, 활용범위 등을 포함한 ‘개인정보 비식별 조치 가이드라인’을 만든 바 있다.
이 가이드라인을 기반으로 개인정보를 활용하려는 움직임도 나타났다. 실제로 2017년 수십 건의 데이터 결합이 이종 기업 간 발생하는 성과도 있었다. 하지만 이런 개인정보를 활용하려는 이러한 움직임은 참여연대를 비롯한 12개 시민단체가 데이터 사업을 시작한 한국인터넷진흥원(KISA) 등 4개 기관과 현대자동차, SK텔레콤, 삼성생명 등 기업 20곳을 개인정보보호법 위반 혐의로 검찰에 고발하면서 활성화되지 못했다. 당시 검찰 고발 건은 무혐의로 결론 났지만, 기업들의 움직임은 소극적으로 변할 수밖에 없었다.
업계 관계자들은 ‘가이드라인’ 수준에 그쳤던 것이 문제였다고 지적한다. 법제화된 것이 아닌 ‘가이드라인’이었기 때문에 한계가 있었다는 것이다. 윤덕상 파수닷컴 전략사업본부장은 “데이터 3법이 개정되기 이전에는 데이터 활용이 사실상 불가능했다. 그나마 돌파구를 찾아보고자 시도한 것이 가이드라인이었다. 고발 건에 대해서는 무혐의 처분이 났지만, 그럼에도 기업들이 소극적으로 변한 것은 불필요한 이슈를 만들지 않기 위한 것으로 보인다”고 설명했다.
이런 관점에서 이번 데이터 3법 개정안 통과는 의미가 깊다. 가이드라인의 한계를 해결함으로써 데이터 활용의 기반을 마련했다는 평가다. 다만 본격적인 데이터 활용은 시행령 및 가이드라인 등 구체적인 제도가 마련돼야 가능할 것이라는 전망이다.
박세경 펜타시스템테크놀로지 CTO는 “이번 데이터 3법 개정안의 통과는 데이터를 활용할 수 있는 법제적 기반을 마련하고, 개인정보보호위원회를 전담기구로 격상하는 등 긍정적인 평가도 있지만, 가명정보와 익명정보에 대한 해석이 각기 다른 만큼 시행령과 가이드라인에서 정확히 규정할 필요성이 있다”고 강조했다.
‘가명정보’ 명시…활용되는 데이터 품질 높인다
이번 데이터 3법의 주요 내용 중 하나는 역시 ‘가명정보’의 개념을 도입하고 이를 명시화했다는 것이다. 이전에는 익명정보의 개념만 도입했기 때문에, 데이터 활용 측면에서 의미 있는 결과를 도출하기 어려웠다. 하지만 이번 데이터 3법에 가명정보 개념이 도입됨에 따라 데이터 품질이 높아질 것으로 기대되고 있다.
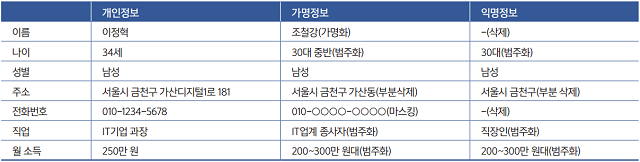
그렇다면 개인정보, 가명정보, 익명정보의 차이는 무엇일까. 먼저 개인정보는 살아있는 개인에 관한 정보로, ▲성명·주민등록번호·영상 등을 통해 개인을 알아볼 수 있는 정보 ▲해당 정보만으로 특정 개인을 알아볼 수 없더라도 다른 정보와 쉽게 결합해 알아볼 수 있는 정보 등을 포함한다. 더불어 이번 개정안에서는 ▲개인정보를 가명처리함으로써 원래의 상태로 복원하기 위한 추가정보의 사용·결합 없이는 특정 개인을 알아볼 수 없는 정보(가명정보)도 개인정보의 정의에 포함됐다.
가명정보는 개인정보의 일부를 삭제하거나, 일부 또는 전부를 대체하는 등의 방법으로 추가정보 없이는 특정 개인을 알아볼 수 없도록 처리하는 것을 의미한다. 신용정보법 개정안에서는 ‘가명처리’를 추가정보를 사용하지 않고는 특정 개인인 신용정보주체를 알아볼 수 없도록 개인신용정보를 처리하는 것을 의미한다고 명시돼 있다.
익명정보는 특정 개인인 신용정보주체를 알아볼 수 없도록 개인신용정보를 처리하는 것을 의미한다. 익명정보는 추가적인 정보와 결합해도 재식별이 불가능한 정보로, 개인정보보호법의 적용을 받지 않는다.
즉 개인정보는 성명, 주민등록번호 등 개인을 식별할 수 있는 정보며, 가명정보는 개인정보의 일부를 삭제하거나 대체하는 등의 조치로 추가정보 없이는 식별할 수 없도록 처리하는 것을 의미한다. 익명정보는 가명정보에서 더 나아가 추가정보와 결합하더라도 식별이 불가능하도록 처리한 것이다.
예를 들어 서울시 금천구 가산디지털1로 181에 살고 IT기업 과장인 34세 남성 이정혁이 있다고 가정해보자. 이를 가명처리하면 서울시 금천구에 살고 IT업계 종사자인 30대 중반 조철강이 돼 이정혁이라는 특정 개인을 식별할 수 없게 된다. 더불어 익명처리까지 한다면 서울시 금천구에 거주 중인 30대 직장인 남성으로 치환할 수 있다.
앞서 말했듯이 익명정보는 추가 정보와 결합하더라도 개인을 식별할 수 없는 정보이기 때문에 개인정보보호법 개정안 제58조 2에 따라 법의 적용을 받지 않는다. 익명정보는 개인정보가 아니기 때문에 더 자유로운 활용이 가능하다는 것이다. 하지만 익명정보를 활용할 경우 재식별 가능성에 대한 철저한 검증이 필요하다는 지적이다.
가명정보는 개인정보보호법에 따라 개인정보의 일종으로 취급되기 때문에 개인정보보호법을 준수해야 한다.
이번 개정안을 통해 개인정보처리자는 통계작성 및 과학적 연구, 공익적 기록보존 등의 목적 내에서만 정보 주체의 동의 없이 가명정보를 처리할 수 있게 됐다. 또한 이런 목적을 위해 서로 다른 개인정보처리자 간의 가명정보를 결합할 땐 개인정보보호위원회 또는 전문기관에 의뢰해야 한다. 개인정보처리자는 가명정보를 처리할 때 원래 상태로 복원하기 위한 추가정보를 별도로 분리해 관리해야 하며, 관련 법령에 따른 보호조치를 적용하지 않는다면 처벌받을 수도 있다.
이번 개정안에 따르면 적절하게 가명정보를 처리하지 않았을 경우에는 전체 매출액의 3% 이하 또는 4억 원의 과징금, 5년 이하의 징역 또는 5천만 원 이하의 벌금에 처해질 수 있다.
윤덕상 파수닷컴 본부장은 “이번 데이터 3법 개정의 핵심 내용 중 하나는 수집 동의를 받지 않아도 통계작성 및 과학적 연구, 공익적 기록보존 등의 목적으로 활용이 가능하다는 점이다. 하지만 무조건 활용이 가능한 것은 아니며, 가명처리 등 비식별 처리가 필요하다. 이에 데이터를 분석하는 기업들의 비식별화 솔루션 수요가 급증할 것이라고 생각된다”고 설명했다.
데이터 활용의 기본, 비식별화
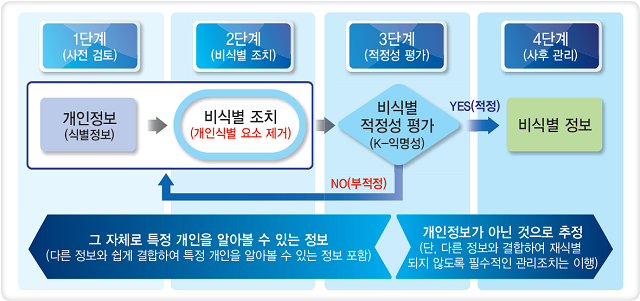
데이터 3법 개정안에 따라 민감 데이터를 활용하기 위해서는 먼저 비식별 조치를 취해야 한다. 비식별 조치는 데이터 셋에서 개인을 식별할 수 있는 요소 전부 또는 일부를 삭제하거나 대체하는 방법을 활용, 개인을 알아볼 수 없도록 하는 조치다. 이와 더불어 다른 정보와 쉽게 결합해 개인을 식별할 수 있는지를 검사하는 ‘비식별 조치 적정성 평가’를 함께 진행해야 한다.
먼저 사전 검토 단계를 통해 빅데이터 분석을 위한 정보가 개인정보인지 판단해야 한다. 해당 정보가 개인정보에 해당하지 않는 것이 명백한 경우에만 별도 조치 없이 빅데이터 분석 등에 활용할 수 있다.
비식별 조치에 있어서 가장 중요한 개념은 ▲식별자(Identifiers)와 ▲속성자(Attribute value) 2가지다.
‘식별자’는 단일 또는 조합을 통해 개인을 직접 식별할 수 있는 속성이며, ▲고유식별정보(주민등록번호, 여권번호, 운전면허번호 등) ▲성명 ▲상세주소 ▲날짜 정보(생일, 기념일 등) ▲전화번호 ▲의료기록번호 ▲계좌 및 신용카드 번호 ▲자동차 및 각종 기기의 등록 번호 ▲사진 ▲신체 식별정보 ▲이메일 및 IP, MAC 주소 ▲식별코드(아이디, 사원번호, 고객번호 등) 등이 해당된다.
2016년 ‘개인정보 비식별 조치 가이드라인’에서는 데이터에 포함된 식별자는 원칙적으로 삭제 조치해야 한다고 명시하고 있다. 다만 데이터 이용 목적상 반드시 필요한 식별자는 비식별 조치 이후 사용해야 한다고 권고하고 있다.
‘속성자’는 자체로는 식별자가 아니지만, 다른 데이터와 조합을 통해 특정 개인을 추론할 수 있는 데이터로, ▲개인 특성 ▲신체특성 ▲신용 특성 ▲경력 특성 ▲전자적 특성 ▲가족 특성 등이 포함된다.
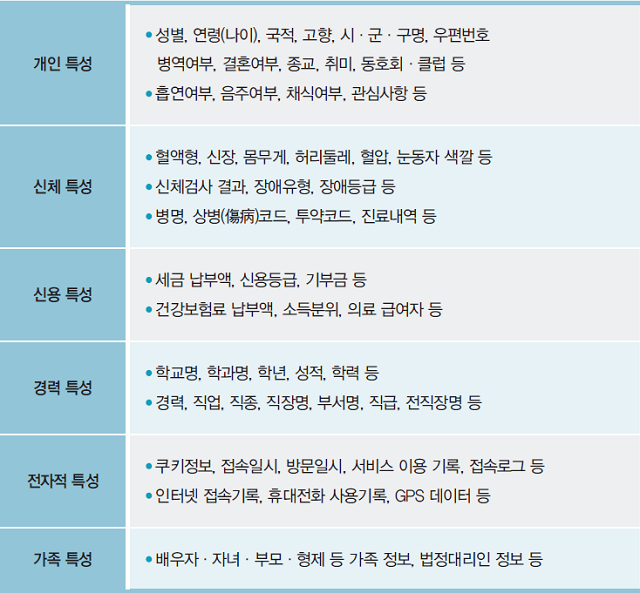
가이드라인에는 데이터에 포함된 속성자도 데이터 이용 목적과 관련이 없는 경우에는 원칙적으로 삭제해야 한다고 명시돼 있다. 또한 데이터 이용 목적과 관련이 있는 속성자 중 식별요소가 있는 경우에는 가명처리, 총계처리 등의 기법을 활용해 비식별 조치를 해야 한다. 특히 희귀병명, 희귀경력 등 구체적인 상황에 따라 개인 식별 가능성이 매우 높은 속성자는 엄격한 비식별 조치가 필요하다고 강조하고 있다.
비식별 조치, 5가지 기법 및 17가지 세부기술 정립
현재 국내에서 공급되고 있는 비식별화 솔루션들은 2016년 가이드라인의 5가지 비식별 조치 처리기법과 17가지 세부기술을 기반으로 개발돼 있다. 5가지 처리기법과 17가지 세부기술은 ▲가명처리(Pseudonymization) - ①휴리스틱 가명화 ②암호화 ③교환방법 ▲총계처리(Aggregation) - ④총계처리 ⑤부분총계 ⑥라운딩 ⑦재배열 ▲데이터 삭제(Data Reduction) - ⑧식별자 삭제 ⑨식별자 부분삭제 ⑩레코드 삭제 ⑪식별요소 전부삭제 ▲데이터 범주화(Data Suppression) - ⑫감추기 ⑬랜덤 라운딩 ⑭범위 방법 ⑮제어 라운딩 ▲데이터 마스킹(Data Masking) - ⑯임의 잡음 추가 ⑰공백과 대체 등으로 구성된다.
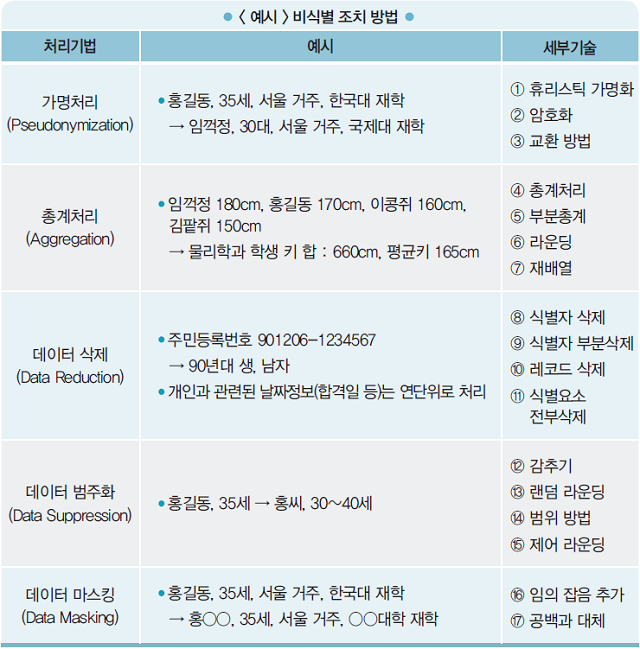
‘가명처리’는 개인 식별이 가능한 데이터를 직접적으로 식별할 수 없는 다른 값으로 대체하는 기법으로, 성명 및 기타 고유 특징을 비식별 처리할 때 사용된다. 데이터 변형 또는 변질 수준이 적은 것이 장점이며, 대체 값을 부여해도 식별 가능한 고유 속성이 계속 유지된다는 것이 단점이다.
가명처리를 위한 기술 중 ①휴리스틱 가명화는 식별자에 해당하는 값들을 몇 가지 정해진 규칙으로 대체하거나 가공해 자세한 개인정보를 숨기는 방법이다. 식별자의 분포를 고려하거나 수집된 자료의 사전분석을 하지 않고 모든 데이터를 동일한 방법으로 가공하기 때문에 사용자가 쉽게 이해하고 활용할 수 있다는 것이 장점이다. 단점은 활용할 수 있는 대체 변수의 한계가 있으며 일정한 규칙이 노출될 수 있다는 취약점이 있다는 것이다. 주로 적용하는 정보는 성명, ID, 소속명, 주소, 전화번호 등이다.
②암호화는 정보 가공 시 일정한 규칙의 알고리즘을 적용해 암호화함으로써 개인정보를 대체하는 방법이다. 통상적으로는 다시 복호화가 가능하도록 복호화 키를 갖고 있다. 암호화를 주로 적용하는 정보는 주민등록번호, 여권번호, 신용카드 번호 등이다. ③교환 방법은 기존 DB의 레코드를 사전 정해진 외부의 변수(항목) 값과 연계해 교환하는 방식으로, 주로 ID, 나이, 성별, 신체정보, 전화번호, 주소 등을 비식별 처리할 때 사용한다.
‘총계처리’ 기법은 통계 값을 적용해 특정 개인을 식별할 수 없도록 한다. 개인과 직접 관련된 날짜 정보, 기타 고유 특징 등을 통계 값으로 치환한다. 단점은 정밀 분석이 어렵고 집계수량이 적을 경우 추론에 의해 식별 가능성이 있다는 점이다.
④총계처리 방법은 데이터 전체 또는 부분을 집계하는 것으로 나이, 신장, 카드사용액, 유동인구, 사용자수, 제품재고량 및 판매량 등에 활용한다. ⑤부분총계는 데이터 셋 내 일정부분 레코드만 총계처리하는 방법이다. 다른 데이터 값에 비해 오차범위가 큰 항목을 통계값으로 변환한다. 주로 나이, 신장, 소득, 카드사용액 등에 활용한다.
⑥라운딩은 집계 처리된 값에 대해 라운딩 기준을 적용해 최종 집계 처리하는 방법으로 세세한 정보보다는 전체 통계정보가 필요한 경우 많이 사용한다. 나이 값을 대표 연령대로 표기하는 방법이 여기에 속한다. ⑦재배열은 기존 정보값을 유지하면서 개인이 식별되지 않도록 데이터를 재배열하는 방법으로 개인의 정보를 타인의 정보와 뒤섞어서 개인이 식별되지 않도록 한다.
‘데이터 삭제’ 기법은 말 그대로 개인 식별이 가능한 데이터를 삭제 처리하는 방법이다. 데이터를 삭제함으로써 개인정보를 효과적으로 보호할 수는 있지만, 분석의 다양성과 분석 결과의 유효성 및 신뢰성을 저하시킨다는 단점이 있다.
데이터 삭제 세부기술 중 ⑧식별자 삭제는 원본 데이터에서 식별자를 단순 삭제하는 방법이며, 성명·전화번호·계좌번호 등에 적용된다. ⑨식별자 부분삭제는 식별자 일부를 삭제하는 방식이며, 주소·위치정보·전화번호 등에 활용된다. ⑩레코드 삭제는 다른 정보와 뚜렷하게 구별되는 레코드 전체를 삭재하는 방법으로, 키·소득·질병 등 구별되는 값을 가진 정보 전체를 삭제한다. ⑪식별요소 전부삭제는 식별자뿐만 아니라 잠재적으로 개인을 식별할 수 있는 속성자까지 전부 삭제하는 방법이다.
‘데이터 범주화’는 특정정보를 해당 그룹의 대푯값 또한 구간값으로 변환해 개인 식별을 방지하는 기법이다. 주소, 생일 등 개인을 식별할 수 있는 정보에 적용하며, 통계형 데이터 형식을 갖추고 있어 다양한 분석 및 가공에 활용할 수 있다는 장점이 있다. 하지만 정확한 분석 결과 도출이 어려우며, 데이터 범위 구간이 좁혀질 경우 추론 가능성이 있다.
범주화의 세부기술 중 ⑫감추기는 명확한 값을 숨기기 위해 데이터의 평균 또는 범주값으로 변환하는 방식이다. ⑬랜덤 라운딩은 수치 데이터를 임의의 수를 기준으로 올림 또는 내림하는 방법으로, 나이·소득·지출액·유동인구 등에 활용한다. ⑭범위 방법은 수치데이터를 임의의 수 기준의 범위(range)로 설정하는 방법으로, 해당 값의 범위(range) 또는 구간(interval)으로 표현한다. 주로 소득·지출액·사용자 수·분석시간/기간 등에 적용한다. ⑮제어 라운딩은 랜덤 라운딩 방법에서 어떠한 특정값을 변경할 경우 행과 열의 합이 일치하지 않는 단점을 해결하기 위해 행과 열을 일치시키는 기법이다. 주로 나이, 키, 소득, 지출액, 위치정보 등에 활용한다.
‘데이터 마스킹’ 기법은 개인정보 데이터 전부 또는 일부분을 공백·노이즈 등 대체값으로 변환하는 방법이다. 개인 식별요소를 제거하지만 원본 데이터 구조에 대한 변형은 적다는 점이 장점이다. 다만 과도하게 적용하면 필요 목적에 활용하기 어렵고, 수준이 낮을 경우에는 특정값에 대한 추론이 가능하다는 게 단점이다.
마스킹 세부 기술 중 ⑯임의 잡음 추가는 개인정보에 임의의 숫자 등 잡음을 추가하는 방법으로 지정된 평균과 분산의 범위 내에서 잡음이 추가되므로 원본 데이터의 유용성을 해치지 않으나, 잡음값은 데이터 값과는 무관하기 때문에 유효한 데이터로 활용할 수 없다. 주로 ID, 성명, 생일, 나이 등에 활용한다. ⑰공백과 대체는 특정항목의 일부 또는 전부를 공백 또는 대체문자로 바꾸는 방법이며, 주로 성명, 생일, 주민등록번호 등에 활용한다. 예를 들어 주민등록번호 880917-1234567에 공백과 대체 방법을 적용하면 88****-1******으로 변환된다.
비식별 조치 이후 적정성 평가도 중요
기업 및 기관이 진행한 비식별 조치가 충분하지 않은 경우 공개 정보 등 다른 정보와의 결합 또는 다양한 추론 기법 등을 통해 개인이 식별될 우려도 있다. 이에 가이드라인에서는 기업 및 기관들은 개인정보 보호책임자 책임 하에 외부 전문가가 참여하는 ‘비식별 조치 적정성 평가단’을 구성해 개인식별 가능성에 대한 엄격한 평가가 필요하다고 명시하고 있다.
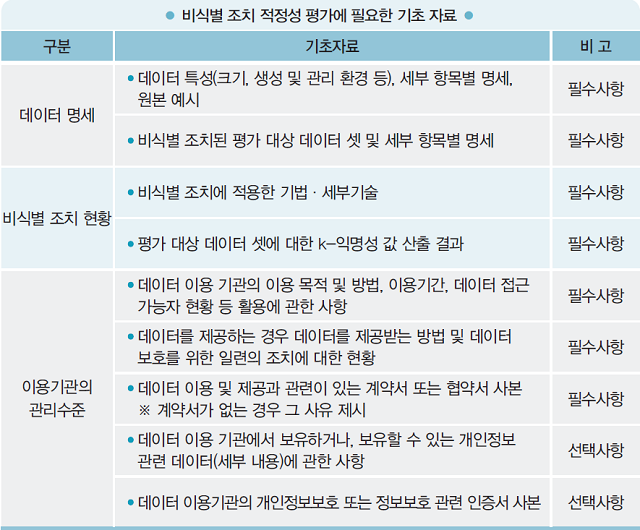
적정성 평가 시 프라이버시 모델 중 k-익명성을 활용하게 된다. 가이드라인은 k-익명성은 최소한의 평가수단이며, 필요시 추가적인 평가모델(l-다양성, t-근접성)을 활용해야 한다고 권고한다. 여기서 얘기하는 프라이버시 보호 모델은 재식별 가능성을 검토하는 모델로, ▲k-익명성 ▲l-다양성 ▲t-근접성 기법 등이 대표적이다.
k-익명성 기법은 특정인을 추론할 수 있는지 여부를 검토하는 방법으로, 일정 확률 수준 이상으로 비식별화 되도록 하고 있다. 동일한 값을 가진 레코드를 k개 이상으로 함으로써 특정 개인을 식별할 확률을 1/k개로 만든다는 것이다.
l-다양성은 특정인 추론이 안 된다고 해도 민감한 정보의 다양성을 높여 추론 가능성을 낮추는 기법으로, 각 레코드는 최소 l개 이상의 다양성을 가지도록 해 동질성 또는 배경지식 등에 의한 추론을 방지한다.
t-근접성은 l-다양성뿐만 아니라 민감한 정보의 분포를 낮춰 추론 가능성을 더욱 감소시키는 기법이다. 전체 데이터 집합의 정보 분포와 특정 정보의 분포 차이를 t 이하로 줄여 추론을 방지한다.
이러한 프라이버시 보호 모델을 기반으로 기업 및 기관들은 적정성 평가를 진행해야 한다. 적정성 평가 절차는 ▲기초자료 작성 ▲평가단 구성 ▲평가 수행 ▲추가 비식별 조치 ▲데이터 활용 등의 순서로 진행된다. 더불어 비식별 정보파일에 대한 접근통제, 접속기록 관리, 보안 프로그램 설치·운영 등의 기술적 보호조치와 비식별 정보파일에 대한 관리 담당자 지정, 비식별 조치 관련 정보공유 금지, 이용 목적 달성시 파기 등의 관리적 보호조치 또한 요구된다.

8월 데이터 3법 발효…정부 “2월 중 시행령 등 하위법령 마련할 것”
지난 1월 통과된 데이터 3법 개정안은 오는 8월 5일 시행될 예정이다. 행정안전부, 방송통신위원회, 금융위원회, 개인정보보호위원회 등 데이터 3법 관계 부처는 1월 21일 합동 브리핑을 열고 데이터 3법 후속 조치 계획을 발표했다.
먼저 정부는 법률 구체화를 위한 행정 입법을 신속하게 추진할 계획이다. 2월 중 시행령 개정안을 마련하고, 3월까지 고시 등 행정 규칙 개정안을 마련하며, 법 시행 시점에는 분야별 가이드라인과 해설서 개정안을 발간해 가명정보의 활용 범위, 데이터 결합 방법·절차 등을 명확히 한다는 방침이다.
또한 EU GDPR 적정성 결정도 조속히 추진하기 위해 EU와의 협력도 강화한다. 그간 감독기구의 독립성 요건 미충족, 개인정보 보호법 미개정 등을 이유로 두 번에 걸친 적정성 결정 심사가 중단됐으나, 이번 법 개정을 통해 요건이 충족돼 적정성 결정이 가시화된 만큼 적정성 결정의 조속한 추진을 위한 협력을 도모한다는 전략이다.
또한 국무총리 소속 중앙행정기관으로 격상하는 개인정보보호위원회가 개인정보보호 정책 수립과 광범위한 조사·처분권을 보유하는 개인정보보호 정책 및 국민권익 보호기관으로 자리매김할 수 있도록, 예산 및 인력의 이관, 조직 및 위원 구성 등이 차질없이 이뤄지도록 지원한다는 계획이다.
이러한 후속조치 이행은 관계 부처 합동의 ‘법제도 개선 작업반’을 통해 추진되고 있다. 행정안전부 전자정부국장을 반장으로 관계부처 과장급이 참여하며 산업계, 시민사회단체, 각계 전문가들과의 적극적인 소통을 통해 하위법령과 보호정책을 구체화한다는 계획이다.
브리핑 당시 윤종인 행정안전부 차관은 “이번 데이터 3법 개정으로 우리나라도 4차 산업혁명에 대비할 수 있는 제도적 기반이 마련됐지만 여전히 명확한 기준 제시와 해석이 중요하다”면서, “정부는 ‘개인정보의 보호와 데이터 활용의 균형’이라는 대전제 아래, 구체적인 가이드라인을 제시하고 아울러 국제 보호규범 정립에도 적극 참여하겠다”고 말했다.
이번 시행령 준비에 있어 미국의 ‘건강보험 이전과 책임에 관한 법(HIPAA)’, ‘경제적·임상적 보건에 대한 건강 정보기술법(HITECH Act: Health Information Technology for Economic and Clinical Health Act)’, ‘가족의 교육적 권리 및 프라이버시 법(FERPA: Family Educational Rights and Privacy Act)’은 물론, 유럽연합(EU)의 ‘개인정보보호규정(GDPR: General Data Protection Regulation)’, 영국 정보보호 커미셔너(ICO)의 익명화 규약, 일본의 개인정보보호법 등 국내외 동향을 참고할 것으로 보인다. 더불어 2016년 발표된 가이드라인과 2018년 제정된 국제 비식별 기술 표준인 ‘ISO/IEC 20889’가 기반이 될 가능성이 높다.
ISO/IEC 20889는 ▲통계 도구(Statistical tools) ▲암호화 도구(Cryptographic tools) ▲삭제 기술(Suppression techniques) ▲가명화 기술(Pseudonymization techniques) ▲해부화 (Anatomization) ▲일반화 기술(Generalization techniques) ▲무작위화 기술(Randomization techniques) ▲합성 데이터(Synthetic data) 등 8가지 비식별 처리 기법과 21가지 세부기술을 정의하고 있다.
박세경 펜타시스템 CTO는 “이전 2016년 가이드라인을 만들 때도 과제를 통해 다양한 국가의 사례를 취합했다. 데이터 3법 개정안의 시행령 및 가이드라인 역시 이를 기반으로 정리될 가능성이 높다”면서, “가명정보, 익명정보에 대한 해석이 사람마다 다르기 때문에 시행령 및 가이드라인에서 정의가 돼야 기업 및 기관들이 본격적인 움직임을 보일 것으로 예상된다”고 설명했다.
한편으론 금융, 통신, 의료 등 각 분야별로 가이드라인을 만들어야 한다는 목소리도 커지고 있다. 각 산업군별로 데이터의 특성이 다르기 때문에 활용 기준 또한 달라야 한다는 것이다. 또한 데이터 결합을 위한 전문기관도 각 산업별 특성을 반영할 수 있도록 구성해야 한다는 주장도 있다.
빅데이터 플랫폼 시장과 함께 고성장 예상
비식별화 솔루션 공급 기업들은 빅데이터 플랫폼 시장이 커질수록 비식별화 시장 또한 고성장을 지속할 것으로 전망하고 있다. 글로벌 시장조사기관 IDC에 따르면 세계 데이터 시장 규모는 올해 2,100억 달러(242조 원)에 달할 것으로 전망된다.
특히 국내에서는 데이터 3법 개정안 통과로 인해 다양한 비즈니스가 창출될 것으로 기대되고 있다. 윤덕상 파수닷컴 본부장은 “이번 데이터 3법 개정안 통과로 크게 두 가지 방향에서 새로운 비즈니스 모델이 나올 것으로 기대된다. 데이터를 유통할 수 있는 플랫폼을 구축하는 기업들이 있을 것이며, 갖고 있는 데이터를 기반으로 새로운 비즈니스를 창출하는 기업도 나올 것으로 전망된다”고 설명했다.
이어 윤 본부장은 “기업 입장에서는 데이터 3법 개정에 맞춰 어떤 비즈니스 모델을 구축할 것인지가 중요하며, 이에 따라 법적 검토 및 인프라 구축이 필요하다. 플랫폼을 제공하는 기업이라면 데이터가 플랫폼에 올라왔을 때 법적 이슈는 없는지, 가공된 데이터를 어떻게 제공할 것인지 등을 고민해야 한다. 기업 내에서 데이터를 활용하는 기업은 내부에서 보관하거나 제3자 제공과 관련된 법적 이슈를 준비해야 한다”고 덧붙였다.
윤덕상 본부장은 기업 및 기관들이 3월까지는 시장을 관망하며 비즈니스 모델을 구상하는 시간이 될 것이라고 전망했다. 또한 우선적으로 8월 데이터 3법 시행에 맞춰 서비스를 제공해야하는 전문기관들이 빠르게 움직일 것으로 보인다고 설명했다. 시행령, 가이드라인이 마련돼야 기업 및 기관들이 프로젝트를 추진할 수 있어, 본격적인 투자는 올 하반기부터 진행될 것이라는 전망이다.
비식별화 솔루션 공급 기업들은 대형 빅데이터 프로젝트에 비식별화 솔루션이 포함되는 방식으로 시장이 형성될 것으로 보인다고 입을 모았다. 펜타시스템은 이미 빅데이터 플랫폼 속에 비식별화 솔루션을 포함시켜 제공하고 있으며, 파수닷컴 또한 컨소시엄 식 비즈니스가 활발해질 것으로 예상하고 있다.
더불어 비식별화 솔루션의 경우 컴플라이언스 이슈와 밀접하다보니, 단순 솔루션 공급에 그치는 것이 아니라 컨설팅 등 부가적인 서비스를 함께 제공하고 있다. 윤덕상 파수닷컴 본부장은 “비식별화 솔루션은 전문 툴이다보니 교육이 필요하다. 범용화돼 전문인력이 양성되기 전까지는 벤더들이 교육을 진행해야 한다. 파수닷컴은 고객사를 대상으로 교육 세미나를 활발하게 진행하고 있으며, 컨설팅 등을 통해 프로젝트에 대응하고 있다”고 설명했다.
아직 소극적인 업계 반응…빠른 후속조치 필요
IT업계는 데이터 3법 개정안의 통과를 환영하는 반면, 데이터 활용 움직임은 아직까지 소극적이다. 데이터 3법은 통과됐지만, 시행령 및 가이드라인 등 후속 조치가 마련되지 못해 섣불리 움직이지 못하고 있는 것이다. 업계는 시행령과 가이드라인이 마련되고, 데이터 3법 개정안이 본격 시행되는 8월 이후에야 본격적인 데이터 활용이 나타날 것으로 전망하고 있다.
박세경 펜타시스템 CTO는 “데이터 3법 통과 이후 개인정보 유출에 대한 우려의 목소리도 커지고 있다. 하지만 개인정보 유출사고의 실상을 살펴보면, 해킹 또는 내부자에 의한 유출 등 불법적인 행위로 인한 사고가 대부분을 차지한다. 이제는 개인정보 유출이라는 부정적인 시각을 탈피해 데이터 활용을 통한 이득에 초점을 맞춰야 할 때”라고 강조하며, “현재 관계 기관을 중심으로 시행령 등 지침 마련에 박차를 가하고 있는 상황으로 사회적 관심은 높아졌지만, 실제 프로젝트로 이어지진 않고 있다. 8월 데이터 3법이 시행되고 나면 시장의 변화가 나타날 것으로 보인다”고 설명했다.
업계에서는 또한 시행령 및 가이드라인을 최대한 빨리 공개해야 한다는 목소리를 내고 있다. 윤덕상 파수닷컴 본부장은 “정부에서는 2월 시행령을 만들고, 법 시행 전까지 가이드라인 등을 발간하겠다고 밝힌 바 있지만, 이를 가급적 빨리 공개해야 한다. 새로운 제도에 맞춰 SW 및 프로세스를 변경해야 하는데, 시행 직전에 발표하게 되면 실질적인 활용은 더욱 늦어지게 된다. 제도 시행 이전에 시장에서 대응 방안을 마련할 수 있도록 진행했으면 하는 바람이다”라고 말했다.
<솔루션 소개>
이지서티, ‘아이덴티티 실드’로 IR52 장영실상 수상 |
 이지서티(대표 심기창)는 지난해 IR52 장영실상에 선정된 개인정보 비식별 조치 솔루션 ‘아이덴티티 실드(IDENTITY SHIELD)’를 공급하고 있다. ‘아이덴티티 실드’는 ▲개인정보 실시간 탐지 기능 ▲K·L·T 프라이버시 모델 방식의 비식별화 기능 ▲비식별 검증 기능 ▲데이터 결합 기능 ▲적정성 평가 관리 기능 ▲통합 모니터링 기능 ▲이력관리 및 접근제어 기능 등을 제공한다. 이지서티 관계자는 “‘아이덴티티 실드’는 비식별 조치 핵심 원천 기술이 적용돼 있으며, 비식별 조치부터 적정성 평가, 데이터 결합까지를 포함한 업무 프로세스를 제공한다는 것이 특징이다. 또한 인메모리 기술을 적용해 고속으로 비식별 처리할 수 있다는 것도 장점이다”라고 설명했다. |
파수닷컴, 글로벌 기준 적용된 ‘애널리틱DID’ |
 파수닷컴(대표 조규곤)은 공공기관 및 기업들이 가명 처리된 데이터를 결합하고 활용함에 있어 정책, 지침, 가이드 등을 수립해 준수할 수 있도록 지원하고 있다. 특히 데이터 활용을 위한 빅데이터 레이크 구성 시 데이터 거버넌스 구축 단계부터 데이터 거래 서비스까지 개인정보 처리 절차와 사용 목적에 맞게 최적화된 결과를 낼 수 있는 비식별화 솔루션 ‘애널리틱DID(AnalyticDiD)’와 컨설팅 서비스를 제공하고 있다. 파수닷컴의 개인정보 비식별화 솔루션 ‘애널리틱디아이디’는 ▲다양한 가명화 및 익명화 기술 지원 ▲데이터 활용 절차 별 지원 ▲업무 프로세스 지원 등이 특징이다. 특히 개인정보 비식별 조치 가이드라인에 명시된 17가지 비식별 기법과 klt 프라이버시 모델을 모두 지원하며, 국제 표준 ISO/IEC 20889에서 제시하는 위험 감소 비식별 기법, GDPR의 가명화·익명화 조치 및 제 3자 색인 기술 모델(Trusted Third Party, TTP) 기반의 결합 키 생성 및 결합 지원 기능 등 글로벌 컴플라이언스 등도 지원한다. 더불어 스파크(Spark) 기반 인메모리(In-Memory) 기술을 통해 다량의 데이터를 빠른 속도로 비식별 처리할 수 있다는 것도 장점이다. 이외에도 파수닷컴은 다수의 빅데이터 레이크 구축 컨설팅과 개인정보 데이터 처리를 성공적으로 구축한 경험을 바탕으로, 데이터 거버넌스 확립 단계의 지원과 수집, 분석 단계의 개인정보 처리 지원, 그리고 증적관리까지 지원하는 API 플랫폼을 구축해 제공하고 있다. ‘애널리틱DID’는 원할한 비식별화 작업을 위해 부서 간 다른 요구사항을 쉽게 적용할 수 있도록 권한 부여 기능을 제공하는 등 업무 프로세스를 지원한다. 파수닷컴은 분석 목적에 맞도록 데이터의 효용성을 유지하면서 개인을 식별할 수 없도록 가명화 및 익명화를 지원하는 컨설팅 서비스(AnalyticDID De-identification Service, ADS)를 별도로 지원하고 있다. 전문 컨설턴트의 노하우와 데이터 3법 관련 법 제도에 대한 이해를 바탕으로 가명화/익명화 조치 지원, 가명화/익명화 위험 진단, 가명화/익명화 플래닝 수립 등에 대한 컨설팅 서비스를 제공한다. 윤덕상 파수닷컴 본부장은 “2017년 고발 사건 이후 2019년까지 국내 시장이 없었다고 해도 무방하다. 그렇다보니 비식별 사업을 위한 개발, 영업, 기술 인력을 유지한 기업이 많지 않다. 파수닷컴은 사업 역량을 꾸준히 유지·발전시켜온 대표적인 기업이다. 국내뿐만 아니라 글로벌 시장도 함께 공략함으로써 사업을 유지할 수 있는 기반을 마련했으며, 모듈화된 제품을 통해 각 분야에 최적화된 솔루션으로 시장을 공략하고 있다”고 강조했다. 이어 “내부적으로 재식별 위험 평가를 위한 특허를 갖고 있으며, 재식별 위험 평가를 GUI로 제공하는 등 담당자의 업무 편의성도 향상시킬 수 있는 기능도 내장했다”고 덧붙였다. 윤덕상 본부장은 시장을 공략하기 위해 고객사를 대상으로 한 교육을 활성화할 것이라고 강조했다. 파수닷컴은 전문기관 시장 및 플랫폼 사용자 시장, 범용사용자 시장을 구분해 비즈니스 전략을 구성하고 있으며, 컨설팅도 확대를 위해 정보보안 컨설팅 전문인력을 비식별 과정 교육을 진행할 계획이라고 설명했다. |
펜타시스템, 빅데이터 플랫폼에 비식별화 통합해 제공 |
 펜타시스템테크놀러지(대표 장종준)는 빅데이터 플랫폼에 비식별화 솔루션 ‘데이터아이 피디(DataEye PIDI: Privacy Information De-identification)’를 포함시켜 시장을 공략하고 있다. ‘데이터아이 피디’ 또한 개인정보 비식별 조치 가이드라인을 준수, 17가지 비식별 기술을 지원하며, k-익명성, l-다양성, t-근접성의 개인정보 보호 모델을 통한 비식별 조치 적정성 평가를 수행할 수 있도록 돕는다. ‘데이터아이 피디’는 데이터 변환 및 이관 처리를 위해 ETL솔루션 ‘PDI(Penta Data Integrator)’를 내장했으며, 인메모리 DB를 활용해 데이터 처리 성능을 높였다. 박세경 펜타시스템 CTO는 “펜타시스템은 데이터 활용의 관점에서 ‘데이터아이 피디’를 개발했다. 기존 빅데이터, 인공지능, 데이터웨어하우스(DW) 구축 경험을 바탕으로 빅데이 플랫폼 사업을 전개하고 있으며, 비식별화 솔루션 역시 포함돼 있다”고 설명했다. 이어 “펜타시스템의 전략은 하나의 기술을 독립적으로 구현하기보다 전체적인 플랫폼의 관점에서 접근한다는 것이다. 이렇게 전략을 추진하다보니 팀 간의 협업을 강조하고 있다”고 덧붙였다. 박 CTO는 “펜타시스템은 또한 마이데이터 사업과 비식별화를 연계할 수 있는 방안을 연구하고 있다. 마이데이터 사업으로 질 좋은 데이터가 수집될 것으로 기대되고 있으며, 데이터를 기반으로 한 새로운 비즈니스도 창출될 수 있다. 마이데이터 사업과 새로운 비즈니스를 연결하는 고리에 비식별화가 필요할 것으로 생각된다. 펜타시스템에서는 빅데이터 플랫폼에 관점을 맞춰 마이데이터 사업에도 접근하고 있다”고 말했다. |
탈레스, 동적 데이터 마스킹 및 토큰화로 개인정보 비식별화 지원 |
|
탈레스는 ‘보메트릭 볼트리스 토크나이제이션 위드 다이내믹 데이터 마스킹(Vormetric Vaultless Tokenization with Dynamic Data Masking)’ 솔루션을 통해 DB 토큰화 및 동적 디스플레이 보안 기능을 제공한다. 이 솔루션은 데이터센터, 컨테이너, 클라우드 등 저장공간에 상관없이 민감 데이터를 보호하고 익명 처리를 지원한다. 이 솔루션의 특징은 ▲동적 데이터 마스킹 ▲무중단 구현 등이다. 동적 데이터 마스킹 기능은 관리자가 필드 전체를 토큰화하거나 일부만 마스킹할 수 있도록 돕는다. 또한 볼트리스 토큰화 솔루션의 포맷 보존 토큰화(Format Preserving Tokenization) 기능을 사용하면 기존 DB의 스키마(Schema)를 변경하지 않고도 민감한 데이터에 대한 액세스를 제한할 수 있으며, REST API를 활용해 토큰화 기능을 시스템을 중단하지 않고 구현할 수 있다. 선택적 일관 데이터 변환은 ‘배치 데이터 트랜스포메이션(Batch Data Transformation) 유틸리티’를 추가 구매해 사용할 수 있는 기능이다. 장시간의 유지보수나 가동중단 없이 대량의 민감 정보를 토큰화 할 수 있도록 지원하며 운영 중인 DB 및 DB 복사본에 포함된 민감한 컬럼들이 토큰화 또는 마스킹 될 수 있도록 지원한다. 탈레스 관계자는 “탈레스는 데이터 보안을 유지하면서도 빅데이터를 효과적으로 제련할 수 있게 하는 툴 중 하나로 가명화(익명화) 솔루션을 활용한 방법을 각 산업에 맞춰 소개하고 있으며, 특히 많은 개인정보를 다뤄야 하는 금융 및 공공기관, 의료산업의 담당자들을 위한 맞춤 컨설팅 서비스를 제공하고 있다. 물론 이 시장이 정부의 규제에 따라 큰 변화가 있는 시장이기는 하지만, 빅데이터의 큰 흐름을 거스를 수는 없는 만큼 각 산업에 맞춘 컨설팅 서비스 제공과 산업별 특화된 채널들의 기술 향상을 통해 고객의 니즈를 충족하며 성장한다는 전술을 펼치고 있다”고 설명했다. |