



엔비디아, GPU로 10년간 딥러닝 견인…인텔, 2020년까지 100배 성능 향상 공언

오늘날 AI의 발전에는 데이터의 폭발적 증가, 머신러닝 알고리즘의 고도화 등이 크게 기여했지만 하드웨어(HW)의 발전 역시 중요한 요소로 꼽힌다. 특히 AI의 부상에는 엔비디아의 그래픽처리장치(GPU)를 연산에 이용, 딥러닝의 학습 속도를 가속시킬 수 있었던 게 큰 역할을 했다. 기존에 몇 달씩 걸리던 학습 과정을 단 며칠로 줄일 수 있었기 때문이었다.
고성능 컴퓨팅(HPC) 시장을 주도하던 인텔 역시 딥러닝 가속기 시장에 뛰어들었다. 2012년 병렬컴퓨팅에 특화된 ‘제온 파이’를 내놓은 인텔은 2016년 2세대 ‘제온 파이’를 내놓고 AI 시대를 돌파하고자 하고 있다. 게임을 위한 GPU를 넘어 자율주행차까지 사업 범위를 넓히고 있는 엔비디아에 맞서, 인텔이 딥러닝 성능을 2020년까지 100배 끌어올리겠다고 공언하면서 딥러닝 가속을 둘러싼 경쟁에 불이 붙고 있다.
인공지능(AI) 열풍…인공신경망 기반 ‘딥러닝’ 주목
지난 2016년 3월, 구글 딥마인드가 개발한 인공지능(AI) ‘알파고’가 이세돌 바둑 9단과의 대국에서 4승 1패의 성적으로 승리를 거뒀다. 이후 IT업계뿐만 아니라 사회 전 영역에서 AI가 화제로 떠올랐으며, 각계에서 AI를 미래 신성장동력으로 꼽고 있다.
이처럼 AI의 역사에서 한 페이지를 장식한 알파고의 압도적 승리의 배경에는 기계가 알고리즘을 통해 데이터로부터 자동으로 학습하는 머신러닝(Machine Learning) 기술, 그 중에서도 인공신경망(Artificial Neural Network) 알고리즘에 기반한 ‘딥러닝(Deep Learning)’이 자리하고 있다.
생물학적 신경망 구조를 차용한 통계학적 학습 방법인 인공신경망은 이미 1940년대에 기본 개념이 등장한 바 있는 오래된 기술이다. 이후 컴퓨터의 발전과 함께 지속적으로 연구가 이뤄지다, 1980년대에는 학습에 사용되는 데이터의 최적화를 위한 역전파(back propagation) 방법이 발표되면서 전성기를 맞았다. 하지만 90년대 이후 인공신경망은 알고리즘의 한계 개선 관련 연구에서 막다른 벽에 부딪혔고, 또 다른 머신러닝 방법들이 주류로 떠오르면서 연구자들의 관심에서 멀어져갔다.
이러한 상황은 2006년 제프리 힌튼(Geoffrey Hinton) 전 토론토 대학 교수가 비지도학습(unsupervised learning)을 이용한 은닉층(hidden layer)에서의 데이터 전처리 방법을 제시하면서 전환을 맞게 된다. 전처리를 거치면 입력된 데이터에 과도하게 영향을 받아 학습 결과가 일반성을 잃는 과적합(overfitting) 문제를 해결할 수 있기 때문이었다. 이를 기반으로 알고리즘을 개선하고 본격 등장한 딥러닝 기법은 인공신경망을 다층으로 쌓아올린 모델에서 전처리를 이용해 데이터를 분류하는데 특화된 기술이다.

여기에 2010년대에는 알고리즘 오류 개선을 위한 몇 가지 방법들이 새롭게 더해졌으며, 2012년 머신러닝을 이용한 이미지 인식 경진대회인 이미지넷 챌린지(ImageNet Challenge)에서 딥러닝 기반 이미지 인식 알고리즘을 선보인 알렉스 크리제브스키(Alex Krizhevsky)가 우승을 차지하면서 마침내 딥러닝은 ‘대세’로 각광받게 된다.
딥러닝, GPU 기반 컴퓨팅 파워로 가속
딥러닝의 부흥에는 단지 알고리즘 측면에서의 성과만이 작용한 것은 아니었다. 컴퓨터의 보급과 인터넷의 발달로 인해 데이터가 폭발적으로 증가하면서, 딥러닝 모델을 제대로 훈련시킬 수 있는 여건이 마련된 점도 큰 영향을 미쳤다. 여기에 방대한 데이터를 다층의 인공신경망에 투입, 수많은 계산을 통해 특징을 추출하고 학습시키기 위해서는 상상을 초월하는 컴퓨팅 능력도 필요했다.
예를 들어, 현재 페이스북 AI연구소 책임자를 맡고 있는 얀 러쿤(Yann LeCun)과 그 동료들이 1989년 진행한 연구에서, 손으로 쓴 10자리의 우편번호를 인식 가능하도록 훈련시키는 데만 당시의 컴퓨터를 이용해 3일이 걸렸다. 27년 후 이세돌과 대결한 알파고는 3천만 건이 넘는 대국 정보를 48층 구조의 인공신경망을 이용해 학습한 것으로 알려졌다. 데이터와 인공신경망 구조가 과거와는 비교할 수 없을 정도로 무겁고 복잡해진 것이다.
그러나 당시 구글 측은 알파고가 100만 기보를 4주 만에 학습 가능한 속도를 갖췄다면서, 이는 사람의 경우 1,000년간 쉬지 않고 바둑만 학습해야 가능한 양이라고 설명했다. 또한 이처럼 거대한 양의 데이터를 처리하기 위한 알파고의 시스템으로는 1920개의 CPU(Central Process Unit, 중앙처리장치)와 280개의 GPU(Graphic Process Unit, 그래픽 처리장치)를 갖춘 구글 클라우드 컴퓨팅 플랫폼(GCP)을 사용했다고 언급했다.
알파고의 시스템에서 알 수 있듯, 복잡하고 방대한 알파고의 딥러닝 알고리즘이 성과를 거둘 수 있었던 배경에는 다수의 컴퓨터를 네트워크로 이어 한 대의 컴퓨터처럼 사용함으로써 연산 능력을 극대화시키는 병렬 컴퓨팅(Parallel Computing)의 기여가 있었다.
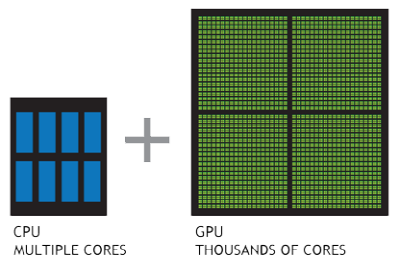
그러나 여기서 주목할 점은 CPU보다는 GPU가 딥러닝을 위한 병렬 연산면에서 더욱 큰 효과를 보여준다는 것인데, 업계 전문가들은 일명 GPGPU(General-Purpose computing on Graphics Processing Units, GPU를 이용한 범용 계산) 기술이 등장하면서부터 딥러닝의 본격적인 발전이 가능했다고 말한다.
본래 3D 그래픽 처리용으로 개발된 GPU는 프로세서 당 수천 개에 달하는 소형 코어가 탑재돼 있다. GPU는 최대 수십 개의 코어를 갖춘 데이터센터용 CPU에 비교하면 개별 코어 성능은 떨어지지만, 애플리케이션의 단순 계산 부문에 저성능의 수천 개 코어를 활용함으로써 CPU의 연산을 돕는다. 이로써 GPGPU 기술은 과거 몇 개월에 걸쳐 학습해야 했던 딥러닝 알고리즘을 단 며칠 만에 완료 가능한 수준으로 크게 개선시켰다.
알렉스 크리제브스키가 선보인 ‘알렉스넷(Alexnet)’ 역시 GPU를 사용한 딥러닝 모델이었다. 그는 GPU로 훈련 시간을 단축하며 나선형신경망(Convolution Neural Network)을 사용한 심층신경망(Deep Neural Network)을 실제로 구현해냈고, 이전까지 한계로 여겨졌던 80%대를 크게 뛰어 넘은 84.7%의 인식정확도를 기록하며 새로운 AI 시대를 예고했다.
알렉스넷의 등장 이후 대부분의 연구자들이 AI에 딥러닝을 접목하기 시작했으며, GPU 역시 크게 조명을 받았다. 여기에 다양한 AI 프레임워크들이 새롭게 발표되면서 정확도는 더욱 높아졌으며, 현재 이미지 인식은 인간의 오류율 5%보다 낮은, 96% 이상의 정확도를 보여주고 있다.
딥러닝용 가속기 시장, 엔비디아 천하…인텔, AMD ‘도전장’
최근 GPU 시장에서는 지포스(GeForce) 시리즈로 유명한 엔비디아(NVIDIA)가 라데온(Radeon) 시리즈를 보유한 경쟁사 AMD를 따돌리고 성능 및 전력효율성 측면에서 앞선다고 평가받고 있으며, 딥러닝을 위한 GPU 가속기 시장 역시 2007년부터 GPGPU 기술인 CUDA(Compute Unified Device Architecture)를 보급해온 엔비디아가 주도하고 있다.

젠슨 황(Jen-Hsun Huang) 엔비디아 CEO는 지난해 2월 뉴욕대학교 창립 기념 심포지엄에서 “AI 개발 프로젝트로 잘 알려진 구글 브레인(Brain) 프로젝트는 유튜브 영상을 통해 고양이와 사람을 구별하는 방법을 학습하는 놀라운 결과를 달성했지만, 이를 위해 2,000개의 CPU를 탑재한 구글 데이터센터의 서버들이 필요했다. 이러한 규모의 시스템은 전 세계에서 극소수만이 제작 및 운영할 수 있을 것”이라며, “그러나 엔비디아의 GPU 기술이라면 이야기가 달라진다. 엔비디아 리서치 팀이 스탠포트 대학의 앤드류 응(Andrew Ng) 연구팀과 함께 GPU를 딥러닝에 활용하기 위한 연구를 진행한 결과, 12개의 엔비디아 GPU가 무려 2,000개의 CPU에 맞먹는 딥러닝 성능을 발휘하는 것을 확인했다”고 밝힌 바 있다.
이처럼 GPU 가속기를 이용하면 상대적으로 저렴한 가격에 딥러닝용 고성능 컴퓨팅(High Performance Computing, HPC) 시스템을 구축할 수 있어, 구글이나 페이스북 같은 초거대기업뿐만 아니라 대학 연구실이나 기업들까지 딥러닝을 연구하고 활용할 수 있도록 장벽을 낮추는 역할을 하고 있다.
엔비디아의 최신 GPU 가속기는 ‘파스칼(Pascal)’ 아키텍처 기반의 최상위 모델인 하이퍼스케일 데이터센터용 ‘테슬라(Tesla) P100’이 있으며, 여기에 딥러닝 추론 과정에 특화된 ‘테슬라 P40’과 저전력 모델 ‘테슬라 P4’ 등이 추가됐다.

사용자는 각 작업의 특성에 따라 ‘테슬라’ GPU의 종류를 다변화해 활용할 수 있으며, 특히 ‘테슬라 P100’은 단정밀도 10.6테라플롭스(TFlops, 1초당 1조 회의 부동소수점 연산), 배정밀도 5.3TFlops의 높은 성능을 기반으로 딥러닝 훈련에 뛰어난 성과를 보인다. 지난해 11월에는 유럽 최고속 슈퍼컴퓨터인 스위스 국립 슈퍼컴퓨팅센터의 ‘피즈 데인트(Piz Daint)’ 시스템 업그레이드에 ‘테슬라 P100’ 탑재가 완료됐다.
이처럼 엔비디아가 이처럼 딥러닝과 GPU 가속기의 시너지 속에서 영향력을 확대하고 있는 가운데, 압도적인 CPU 시장점유율을 보유한 인텔은 한계에 부딪힌 프로세서 클록(clock) 속도 향상과 PC시장 침체 돌파를 위해 클라우드 데이터센터, 5G 네트워크, 사물인터넷(IoT), 모바일, AI 등 IT 생태계 전반으로 영향력 확대에 나서고 있다.
특히 인텔은 일반사용자를 넘어 최근에는 기업용 시장에 더욱 집중하고 있는데, 이 중 HPC 분야에서는 병렬컴퓨팅 역량 강화를 위해 최대 1.1GHz, 61개 코어를 갖춘 보조프로세서(co-processor) ‘제온 파이(Xeon Phi)’ 1세대, 코드명 나이츠 코너(Knights Corner)를 지난 2012년 출시했다. ‘제온 파이’는 CPU의 연산을 보조하면서도 GPU와는 달리 x86 명령어를 그대로 사용 가능하므로 프로그래밍 측면에서 연속성을 가져갈 수 있다는 장점을 갖는다.
여기에 HPC용 레퍼런스 시스템 아키텍처인 ‘확장형 시스템 프레임워크(Scalable System Framework, SSF)를 비롯해 CPU-보조프로세서 및 전체 병렬시스템 간 병목현상 해결을 위한 인터커넥트(Interconnect) 패브릭 솔루션 ‘옴니패스 아키텍처(Omni-Path Architecture, OPA)’도 함께 선보이면서 병렬컴퓨팅의 극대화를 통한 HPC 애플리케이션 성능 향상에 집중했다.

그러나 이후 AI 연구에서 딥러닝과 GPU가 대세로 본격 떠오르면서 인텔은 HPC 분야에서 체면을 구기게 된다. 이에 2016년에는 머신러닝과 HPC 시장을 겨냥, ‘제온 파이 2세대’, 코드명 나이츠 랜딩(Knights Landing)을 새롭게 선보이면서 본격적으로 엔비디아와의 HPC 및 머신러닝 분야 주도권 싸움에 나서고 있다.
인텔의 2세대 ‘나이츠 랜딩’은 부팅이 가능한 호스트 프로세서(Host Processor)로 발전돼 보다 유연성을 갖추게 됐으며, 코어 수는 최대 72개로 늘어났다. 단일 프로세서에서 단정밀도 6TFlops, 배정밀도 3TFlops의 연산능력을 보여주며 16GB MCDRAM(Multi-Channel DRAM)을 프로세서에 결합, 최대 500GB/s의 메모리 대역폭을 제공한다. 또한 GPU처럼 PCI익스프레스(PCIe) 버스(bus)에 의존하지 않고 ‘옴니패스’ 패브릭을 ‘제온 파이’ 프로세서에 바로 결합할 수 있어 스케일 아웃 확장도 용이하다.
한편, 2017년에는 AMD도 딥러닝을 위한 GPU 가속기 시장에 다시 도전할 계획이다. 새롭게 준비한 제품은 ‘라데온 인스팅트(Radeon Instict)’다. 제품 라인업은 ‘MI6’, ‘MI8’, 그리고 최상위 모델인 ‘MI25’ 3종류로, 제품명에 붙은 숫자는 2배속 FP16 연산 성능 기준으로 보인다.
그동안 고정밀 연산 영역에서의 역량 강화에 주력하던 AMD는 이번 ‘인스팅트’에서 딥러닝을 겨냥하고 기존보다 저정밀 연산 능력을 강화했다. AMD는 특히 ‘MI25’가 엔비디아의 ‘테슬라 P100’을 뛰어넘는 FP16 연산 성능을 갖췄다고 밝혔다.

발표대로라면 약 25TFlops의 FP16 연산 성능을 보일 것으로 예상되는데, 엔비디아 ‘테슬라 P100’의 경우 약 21TFlops 정도다. 다만 ‘MI6’와 ‘MI8’은 저정밀도 연산에서 ‘테슬라 P4’나 ‘테슬라 P40’에 뒤처질 것으로 보여 제품의 시장 내 위치가 애매하다고 평가된다. 이처럼 엔비디아, 인텔의 경쟁에 AMD까지 전력을 강화하고 뛰어들면서 2017년에는 가속기 시장 경쟁이 더욱 흥미롭게 전개될 전망이다.
| 인텔 ‘제온 파이’ vs. 엔비디아 ‘테슬라’ |
|
인텔 ‘제온 파이’, 128노드 구성 시 단일 노드 대비 50배 성능 향상 인텔 ‘제온 파이’ 2세대 ‘나이츠 랜딩’ 프로세서는 머신러닝과 HPC 분야 시장 공략을 위한 제품이다. ‘제온 파이’ 1세대 ‘나이츠 코너’가 보조 프로세서(Co-Processor)로만 동작했던 것과는 달리, 2세대 ‘나이츠 랜딩’은 단독으로 부팅이 가능한 호스트 프로세서(Host Processor)로 발전했다. 64~72개의 코어를 바탕으로 다수의 병렬 프로세싱 기반 분석 워크로드를 처리할 수 있으며, 16GB MCDRAM(Multi-Channel DRAM)을 결합해 최대 500GB/s의 메모리 대역폭을 제공함으로써 병목현상을 해결하고자 했다. 여기에 별도로 6채널 DDR4 슬롯을 지원, 최대 384GB까지 메모리를 확장할 수 있다. 또한 머신러닝 스코어링(scoring) 모델에 최적화된 인텔 ‘제온 E5 v4’ 프로세서 제품군과 결합하면 더욱 향상된 성능을 보여준다.
 특히 인텔은 ‘제온 파이 7250’ 제품을 32노드로 구성하면 같은 수로 이뤄진 엔비디아 ‘테슬라 K20’ GPU 가속기 기반 시스템보다 최대 1.38배 향상된 확장성을 제공한다고 주장했다. 또한 확장 가능한 최대 구성인 128노드 시스템에서는 단일 ‘제온 파이’ 노드 대비 최대 50배 빠른 속도로 머신러닝 모델을 훈련시킬 수 있다고 설명했다. 지난해 7월 방한한 휴고 살레(Hugo Saleh) 인텔 HPC그룹 마케팅책임자는 “HPC는 과거 정부나 연구소 등의 전문 영역에서만 사용됐지만, 현재는 전 산업으로 영역을 확장하고 있다”면서, “이제는 날씨, 금융, 제조, 리스크 분석, 영화 제작 등 다양한 영역의 기존 과제들을 해결하는 데 사용된다. 신제품 인텔 ‘제온 파이’는 강력한 병렬컴퓨팅 성능을 제공하는 동시에, 데이터센터의 낮은 총소유비용(TCO)과 높은 투자수익율(ROI)을 제공할 수 있는 제품”이라고 소개했다. |
|
엔비디아 ‘테슬라 P100’, 단일 GPU로 CPU 수십 개 대체 엔비디아는 AI 및 HPC 등 고도의 연산 처리가 요구되는 최신 데이터센터를 위해 PCIe 서버용 ‘테슬라(Tesla) P100’ GPU 가속기를 내세운다. 엔비디아가 최근 새롭게 선보인 ‘파스칼’ GPU 아키텍처 기반의 ‘테슬라 P100’은 CPU 기반 시스템 대비 큰 폭의 성능 개선 및 효율성 향상이 가능하다. 특히 엔비디아는 단일 GPU로 32개 이상의 CPU 기반 노드에 준하는 처리량을 제공, 자본 및 운영비용을 70% 이상 절감할 수 있다고 주장하고 있다. 표준 PCIe 폼팩터에서 사용할 수 있으며 최신 GPU 가속 서버와도 호환 가능하다. 연산 집약적인 AI 및 HPC 데이터센터 애플리케이션에 특히 최적화된 성능을 보여주는데, 예를 들어 단일 ‘테슬라 P100’ 기반 서버는 분자동역학 시뮬레이션 프로그램 ‘앰버(AMBER)’의 구동에 있어 50개의 CPU 전용 서버 노드보다 뛰어난 성능을 제공한다. 또한 오스트리아 비엔나 대학의 소재과학 애플리케이션 ‘VASP’ 실행에 있어서는 32개의 CPU 전용 노드보다 빠르다.
 이안 벅(Ian Buck) 엔비디아 가속컴퓨팅 부문 부사장은 “GPU 가속컴퓨팅은 HPC 및 AI 슈퍼컴퓨팅에 대한 연구자들의 끊임없는 요구를 만족하기 위한 유일한 수단”이라고 말했다. 공과대학 ETH 취리히의 전산물리학 교수이자 스위스 국립 슈퍼컴퓨팅 센터 디렉터인 토마스 슐테스(Thomas Schulthess) 박사는 “스위스 국립 슈퍼컴퓨팅센터의 ‘피즈 데인트’에 탑재된 4,500개 GPU 가속 노드를 ‘테슬라 P100’으로 업그레이드함으로써 시스템 성능을 2배 이상 향상시키고 우주론, 소재 과학, 지진학, 기후학 등 다양한 연구 분야에 새로운 돌파구를 제공할 수 있을 것”이라고 밝혔다. |
협력, 인수 등으로 AI 생태계 확장 주력
양사는 각자 AI 분야에서 영향력을 확대하기 위해 분주히 움직이고 있다. 인텔은 머신러닝 저변 확대를 위해 공개 코드 개발자 커뮤니티와의 협력을 강화할 예정이다. 카페(Caffe), 구글 텐서플로(Tensorflow), 시아노(Theano)와 같은 딥러닝 프레임워크를 최적화해 인텔 아키텍처에서 관련 소프트웨어(SW)가 최적의 성능을 낼 수 있게 지원하는 한편, 심층신경망을 위한 공개 수학 커널 라이브러리(Math Kernel Libraries, MKL)를 최적화해 발표할 계획이다.
또한 인텔은 자체 AI 솔루션 및 기술 확보를 위해 딥러닝 부문 SW와 HW를 모두 갖춘 너바나시스템즈를 인수했다. 다이앤 브라이언트(Diane Bryant) 인텔 데이터센터 총괄은 인수 발표 당시 “너바나시스템즈는 앞으로 인텔의 MKL과 산업 표준 프레임워크를 통합하고 최적화하는 데 도움이 될 것”이라며 “인텔의 AI 포트폴리오를 업그레이드하고 ‘제온’과 ‘제온 파이’ 프로세서의 딥러닝 성능을 강화할 수 있을 것”이라고 밝혔다.

너바나 인수 이후, 인텔은 지난해 11월 AI 연구 및 전략을 발전시켜나가고자 업계와 학계 전문가를 포괄하는 ‘인텔 너바나 AI 위원회(Intel Nervana AI board)’를 구성한다고 발표했다. 더불어 AI 관련 교육 및 툴에 대한 광범위한 개발자 액세스를 제공하는 ‘인텔 너바나 AI 아카데미(Intel Nervana AI Academy)’로 AI에 대한 접근성을 높이고, 인텔 실리콘 상에서 딥러닝 프레임워크를 가속화해주는 ‘인텔 너바나 그래프 컴파일러(Intel Nervana Graph Compiler)’도 공개하며 개발자들을 끌어들이기 위해 노력하고 있다.
또한 ‘AI 아카데미’와 연계해 글로벌 교육 제공업체인 코세라(Coursera)와 제휴를 체결하고, 학계에 AI 온라인 과정도 제공할 예정이다. 이 밖에 모바일 ODT(Mobile ODT)와 2017년 1월 캐글 경진대회(Kaggle Competition)를 공동 주최하고, 학계가 보유하고 있는 AI 기술들을 실제 사회·경제 문제 해결에 적용 가능한지를 테스트할 예정이다. 여기에는 개발도상국에서 자궁경부암을 조기 발견하기 위해 연성 조직 이미징에 AI를 활용하는 사례도 포함된다.
국내 시장 공략을 위해서는 HPC 및 머신러닝에 대한 전문가 교육을 확대한다. 인텔은 지난 2015년부터 파트너사인 대한컨설팅과 함께 ‘CMEP(Code Modernization Enablement Program)’를 진행해 왔다. 해당 프로그램은 인텔 ‘제온 파이’ 및 ‘제온’ 프로세서 기반 HPC 시스템 활용을 최적화할 수 있도록 다중 코어에 맞춰 애플리케이션을 병렬화 및 벡터화할 수 있는 교육 과정을 제공한다. 2016년 말 기준으로 약 1,000여 명이 전문 인력 교육 프로그램에 참여했다.
더그 피셔(Doug Fisher) 인텔 소프트웨어 및 서비스 그룹 부사장 겸 총괄 책임자는 “인텔은 AI 혁신을 주도할 핵심 기술들을 제공할 수 있다. 그렇지만 결국 AI의 궁극적인 잠재력을 실현하기 위해서는 산업 및 사회 전반의 공동 노력이 반드시 필요하다”고 말했다.
한편, 엔비디아는 글로벌 기업들과 밀접하게 협력하면서 GPU 기술 기반의 AI 생태계를 구축하고 있다. IBM과의 협력이 대표적이다. IBM의 딥러닝 SW 툴킷인 ‘파워 AI(Power AI)’는 ‘엔비디아 GPUDL’ 라이브러리를 탑재했으며, 또한 ‘오픈파워 재단(OpenPOWER Foundation)’ 회원사인 양사가 함께 개발한 인터커넥트 기술 ‘NV링크(NVLink)’에 최적화돼 있다.
특히 IBM은 최근 자사 ‘파워8(Power 8)’ 프로세서에 ‘NV링크’ 지원을 추가한 ‘파워8 위드 NV링크(POWER 8 with NVLink)’를 새롭게 출시하면서 엔비디아와의 독점적인 협력을 강화했다. ‘NV링크’는 80GB/s의 대역폭을 지원, ‘PCIe 3.0’ 대비 5배 이상 빠른 인터커넥트 기술이다. 양사는 협력을 통해 GPU 간 연결뿐만 아니라 ‘파워8’ CPU와의 연결에도 ‘NV링크’를 적용, CPU-GPU 구간의 병목현상을 없앴으며, 이는 인텔 x86 시스템에서는 불가능하다.

퍼블릭 클라우드 서비스 기업과의 제휴도 폭넓게 하고 있다. 먼저 올해 초부터 ‘테슬라 P100’ GPU 및 ‘테슬라 K80’ GPU가 ‘구글 클라우드 플랫폼’에서 구동될 예정이다. 이로써 전 세계 ‘구글 컴퓨트 엔진(Google Compute Engine, GCE)’ 및 ‘구글 클라우드 머신 러닝(Google Cloud Machine Learning)’ 사용자들이 ‘테슬라’ GPU를 활용할 수 있게 됐다. ‘구글 클라우드 플랫폼’에서 엔비디아 GPU를 활용할 경우, 사용자들은 분 단위 사용량에 기반해 서비스 비용을 지불하면 된다.
또한 마이크로소프트(MS)의 클라우드 서비스 ‘애저(Azure)’에서는 엔비디아의 GPU 기반 데스크톱가상화(VDI) 플랫폼 기술 ‘그리드(GRID)’가 적용된 ‘애저 N시리즈’ 가상머신(VM)이 지난해 12월 1일부터 제공되고 있다. 엔비디아 ‘그리드’에서는 딥러닝 알고리즘을 빠르게 훈련하고 평가할 수 있는 MS의 엔터프라이즈 AI 프레임워크 ‘코그니티브 툴킷(Cognitive Toolkit, 이전 CNTK)’을 사용할 수 있으며, 이는 앞으로 ‘테슬라’ GPU에 더욱 최적화될 예정이다.

이 밖에 양사는 ‘코그니티브 툴킷’을 엔비디아가 딥러닝만을 위해 만든 ‘DGX-1’ 슈퍼컴퓨터에도 최적화했다. ‘DGX-1’은 ‘테슬라 P100’에 사용된 ‘GP100’ 프로세서 8개와 각 GPU 당 16기가바이트의 GPU 메모리, 인텔 ‘제온E5-2698 v4’ CPU, 512GB RAM, ‘NV링크’ 인터커넥트 등으로 구성돼 있다. 양사에 따르면 ‘DGX-1’과 ‘코그니티브 툴킷’의 조합은 딥러닝을 위해 데이터를 활용할 때 CPU 기반 시스템 대비 최대 170배에 달하는 고성능을 보여준다고 한다.
2017년, AI 시대 본격 개막…양사 행보는?
인텔과 엔비디아 양사는 본격적으로 다가올 AI 시대를 맞아 미래 준비를 위해 바쁘게 움직이고 있다. 먼저 인텔은 기기부터 데이터센터에 이르는 전 영역에 걸쳐 AI의 활용을 확대하고, 이를 통해 성장을 가속화한다는 통합 전략을 최근 공개했다. 특히 2020년까지 딥러닝 성능을 100배 향상시킨다는 목표를 제시해 눈길을 끌었다. 이를 달성하는 데에는 인텔이 인수한 너바나시스템즈와 알테라(Altera), 두 기업의 역량이 핵심이다.

앞서 소개했듯 인텔은 너바나의 딥러닝 SW 및 HW 기술을 흡수했으며, 이를 기반으로 새로운 프로세서를 내놓겠다는 구체적 계획을 지난해 말 발표했다. 이를 위해 우선 2017년 상반기 너바나의 기술을 통합한 첫 번째 실리콘, 코드명 ‘레이크 크레스트(Lake Crest)’를 테스트하고 연말에는 주요 고객이 사용할 수 있도록 제공할 예정이다.
‘레이크 크레스트’는 인공신경망에 특히 최적화된 제품으로 딥러닝을 위한 최고의 성능을 제공하며, 고대역폭의 상호 연결을 통해 전례 없는 컴퓨팅 처리 용량을 제공하게 될 것이라는 게 회사 측 설명이다. 또한 이를 바탕으로 새로운 제품, 코드명 ‘나이츠 크레스트(Knights Crest)’도 제품 개발 로드맵에 추가됐다.
또한 인텔이 2015년 말 인수를 완료한 알테라는 사용자가 용도에 맞춰 프로그램의 설계를 변경할 수 있는 ‘프로그래밍 가능한 반도체(FPGA)’ 기술을 보유했다. FPGA는 클록 속도 향상에 한계를 갖는 기존 프로세서에 비해 특정 용도에서 효율성이 높고 병목 현상이 적으며, 프로그래밍에 따라 하나의 알고리즘 가속기로 기능할 수 있다.
MS도 이미 ‘애저’ 클라우드 데이터센터에 FPGA를 적용하는 ‘프로젝트 캐터펄트(Project Catapult)’를 추진했다고 밝혔다. 구글의 경우 ‘알파고’에 FPGA 대신 ASIC(Application Specific Integrated Circuit)인 고유의 TPU(Tensor Processing Unit)를 사용했다고 밝혔는데, 프로그래밍이 가능한 것을 제외하면 TPU도 FPGA와 유사한 기능을 한다. 인텔은 이러한 기술을 최종적으로 자사 ‘제온’은 물론 ‘제온 파이’ 프로세서에 통합함으로써, 현재 GPU가 주도하고 있는 딥러닝 가속기 시장에서 영향력을 확대하고자 준비하고 있다.
한편, 엔비디아는 현재 AI 적용이 시작된 분야 중 전 세계적으로 가장 큰 관심을 받고 있는 자율주행차에 집중하는 모양새다. 이를 위해 자율주행차용 프로세서 및 핵심 기술에 대한 연구·개발을 진행하면서 시장 선점에 공을 들이고 있다.

엔비디아의 차량용 슈퍼컴퓨터 ‘드라이브 PX2’는 자율주행차용으로 개발한 ‘파커(Parker)’ 프로세서와 ‘파스칼’ 아키텍처 기반 GPU가 각각 2개씩 들어간 단일 SoC(시스템 온 칩)를 탑재해 약 8TFlops의 연산능력을 갖췄다.
이를 통해 ▲차량 위치 파악 ▲안전한 운행궤도 측정 ▲360도 주변 상황 인식 등을 수행하면서 초당 약 24조 회의 딥러닝 작업 속도를 구현한다. 여기에 주변 환경을 보다 폭넓게 이해하기 위해 12개의 비디오카메라를 비롯해 레이더, 초음파 센서 등 다양한 경로에서 수집되는 정보들을 결합하는 ‘센서 융합’ 기술도 활용한다.
또한 자율주행차량 개발자들에게 개발 및 테스트를 위한 다양한 라이브러리 및 모듈 등을 제공하는 ‘드라이브웍스’는 주변 환경 측정, 데이터 수집, 동기화, 기록, 처리 등 전체 데이터 흐름을 관장하면서 ‘드라이브 PX2’를 지원한다. 이 밖에 엔비디아 GPU 기반 시스템에서 실행 가능한 신경망 개발, 트레이닝 및 시각화를 위한 도구 ‘디지츠(DIGITS)’를 제공하며, 자율주행 학습을 위한 심층신경망 플랫폼 ‘드라이브넷(Drivenet)’도 서비스한다.
이러한 플랫폼을 바탕으로 엔비디아는 자체 개발한 자율주행차 ‘BB8’의 테스트를 진행했으며, 전 세계 초기 개발 파트너사들은 이미 2016년 2분기부터 ‘드라이브 PX2’를 활용해 자율주행차를 제작해왔다. 자율주행차 분야의 성과는 오는 1월 5일부터 미국 라스베이거스에서 열리는 CES2017에서 젠슨 황 엔비디아 CEO가 기조연설을 진행하는 가운데 공개될 예정이다.