



정윤진 피보탈 랩 프린시플 테크놀로지스트
[컴퓨터월드]

| 1. 스프링 부트 <2017.5월호> 2. 스프링 클라우드 Config server <2017.6월호> 3. 스프링 클라우드 Service discovery <2017.7월호> 4. 스프링 클라우드 Zipkin <2017.8월호> 5. 스프링 클라우드 Zuul <2017.9월호> 6. 스프링 클라우드 Hystrix <이번호> |
서킷브레이커(Circuit Breaker)는 일반적으로 어떤 전기적 회로를 과전압 등으로부터 보호하기 위해 사용하는 일종의 장치를 말한다. 아주 단순한 의미에서 보면, 각 가정집에 설치돼있는 누전차단기 또는 퓨즈와 같은 장치를 말한다.
누전차단기의 역할은 각 가정에서 보면 우리집에 흘러들어오는 과전압 등으로부터 각종 전자제품을 보호하고 화재를 예방하는 것처럼 보이지만, 원래는 하나의 가정에서 발생한 누전사고로 인해 전체 가구에 문제가 생기는 것을 방지하기 위한 장치였다.

누전차단기가 없는 상황을 상상해보도록 하자. 누전차단기가 없다는 말은, 예를 들어 아파트에 공급되는 전원장치에 모든 가구들이 회로차단기 없이 연결돼있는 상태를 의미한다. 이런 환경에서 특정 가구가 더 많은 전기를 사용하기 위해 거미줄처럼 멀티탭을 여럿 연결해 사용해 과부하가 걸려 화재가 발생하게 된다면 인접한 모든 가구들이 위험에 빠질 것이다. 쇼트가 발생한다면 어떨까. 모두 하나의 회로를 공유하므로 여기에 연결된 모든 전기제품들이 동작하지 않게 될 것이다. 또는 과부하 위험에 빠져 퓨즈가 없는 전자제품들은 아예 망가져 버릴 수 도 있다.
이런 문제를 해결하기 위해 등장한 게 바로 서킷브레이커, 즉 누전차단기다. 위와 같은 상황이 발생했을 경우 안전하게 해당 가구의 전기적 연결을 전체 망에서 분리시켜 문제를 제거한다. 또한, 문제가 해결되기 전까지는 회로의 연결을 거부하며, 문제해결이 정상적으로 완료된 상태에서만 회로의 연결을 허용하게 된다. 어디가 문제인지 발견하지 못한 상태에서 누전 또는 과전압 등이 발생한다면 서킷브레이커는 지속적으로 연결을 거부할 것이다.
어떤 서비스가 마이크로 구조로 돼있다는 것은, 하나의 서비스가 매우 많은 작은 서브 서비스들로 이뤄져있다는 말과 같다. 그 구조는 다수의 가구로 이뤄진 아파트의 모양을 생각하면 쉽다. 각각의 가구는 어떤 역할을 하는 마이크로서비스이며, 이들이 모여 거대한 하나의 아파트를 이룬다. 이때 각각의 서비스에 문제가 발생하면 모든 서비스가 정지하게 되는 구조라면 어떻게 될까.
본 연재의 시작에 넷플릭스가 있었다. 이들이 현재 마이크로서비스로의 전환에 대해 가장 첫 번째로 언급하는 이유 중 하나가 바로 이런 문제의 해결을 위해서다. 거대한 자바에 담긴 수많은 애플리케이션들은 아주 다양한 문제를 발생시킨다. 의존성 문제, 거대한 코드베이스에서 발생하는 여러 문제들도 있지만, 가장 큰 문제는 프로덕션 서비스의 다운이다. 온라인으로 장사를 하는 사업을 구현한 서비스가 정지하면 그 즉시 매출이 0이 되며, 경우에 따라 이전의 고객들도 잃을 수도 있게 된다.
2008년에 발생한 넷플릭스 장애는 단 하루만에 18~30억 달러 규모의 손실을 발생시켰다. 이때의 장애는 다양한 검색을 통해 살펴볼 수 있는데, 대개 설명되고 있는 것은 거대한 자바 애플리케이션이 거대한 오라클 DB와 연결돼있었고, 이때 오라클 DB에서 사용 중인 하드디스크 가운데 하나에 장애가 발생하면서 모든 서비스가 정지됐던 것이 원인으로 규명된다.
이 글을 읽는 수많은 이들 중에는 아마 아직도 마이크로서비스가 왜 좋은지, 서비스에 어떤 도움을 주는지, 그리고 어떤 문제를 해결할 수 있는지 잘 이해가 안 되는 이도 있을 것이다. 아마도 대부분의 경우 현재 운용하고 있거나 개발 중인 서비스에서 DB가 다운된다면 전체 서비스가 다운되는 구조인 상태를 왜 그대로 유지하고 있는지 궁금해 하는 이도 많지 않으리라 생각된다.
사실 생각해보면 신기하다. 왜 우리는 DB 다운이 전체 서비스 다운을 야기하는 서비스 구조를 그대로 사용하고 있는가. 그리고 왜 DB에서의 구조 변경이 서비스의 규모가 커지면 커질수록 더 힘들어지는가. 그리고 잘못된 변경 하나로 다른 수많은 기능에 문제가 발생할까 두려워하는가.
서킷브레이커는 이 같은 현상을 방지하기 위한 결함격리(fault isolation) 개념을 구현한 도구로 볼 수 있다. 즉, 하나의 서비스에서 발생한 장애가 전체 서비스에 영향을 주는 것을 방지하려면 두 가지가 필요하다. 먼저 해당 부분의 역할을 수행하는 서비스들이 ‘분리’돼있어야 하고, 이는 곧 두 서비스가 서로 적절한 방법으로 데이터나 메시지를 주고받을 수 있는 수단이 있음을 의미한다. 이때 하나의 서비스 장애가 다른 서비스에 영향을 미치지 않도록 해야 한다는 것으로, “영향을 미치지 않는다”는 말을 조금 더 전문적으로 바꿔보면 아래의 것들을 생각해볼 수 있다.
● 서비스 A는 DB가 연결돼있는 서비스 B로 HTTP 호출을 통해 필요한 데이터를 받아온다고 가정할 때,
● 서비스 B의 DB가 문제가 발생하는 등의 문제로 타임아웃 또는 50x의 응답이 발생하는 경우에도
● 서비스 A는 지속적으로 동작해야 한다.
대규모 서비스를 설계할 때, 우리는 적절한 타임아웃 설정을 중시한다. 실제로 어떤 요청에 대해 부하 상태 등으로 타임아웃이 발생하게 되면 그 다음 요청에 대한 응답을 조금 더 긴 시간에 랜덤으로 처리하는 엑스포넨셜 백오프(exponential backoff) 등의 기법에 대해 공부한다. 하지만 궁극적으로 요청을 받는 서비스에 심각한 문제가 발생해 단시간 내 복구가 불가능한 상태에 빠지면 언제가 됐건 전체 서비스 다운으로 이어진다는 사실을 알고 있다.
넷플릭스의 서킷브레이커는 이것과는 조금 다른 방식으로 동작한다. 먼저, 각각의 마이크로서비스는 자신의 상태에 대한 정보가 담겨진 ‘스트림’을 생성한다. 그리고 이 서비스와 연계를 원하는 서비스는 이 상태 스트림 정보를 바탕으로 해당 서비스가 어떤 상태인지, 그리고 내 요청에 대한 응답으로 200이 발생했는지 500이 발생했는지 등에 대해 모니터링하고, 문제인 상태가 지속되면 해당 서비스로의 요청을 끊어버린다.
해당 서비스로 요청을 끊어버리면 원하는 데이터를 받지 못하게 돼 다시 문제가 되는 거 아니냐고 생각할 수 있다. 그리고 실제로 그렇다. 해서 서킷브레이커는 ‘fallback’ 메시지를 정의하도록 한다. 무엇이냐면, 서비스 B가 정상일 때 가장 일반적으로 응답할 수 있는 내용 또는 링크 등의 사전에 지정된 ‘static’ 메시지를 서비스 B에 문제가 발생할 때 응답하도록 한다는 것이다.
예를 들어, 전체 페이지를 구성하기 위해 백엔드에 3개의 서비스 요청이 필요한데, 이는 각각 검색, 광고, 그리고 추천이라고 해보자. 이때 추천 마이크로서비스가 고장 난 경우, 개인화된 정상 추천 내용을 응답하도록 하는 대신, 가장 많은 사람들이 구매하거나 사용하는 내용을 static 링크로 추천하도록 한다. 이렇게 되면 실제 추천 기능은 동작하지 않지만, 전체 페이지를 나타내는 데는 아무런 문제가 없는 것이다.
궁극적으로, 어떤 기능이 동작하지 않기 때문에 완전히 100% 동작하는 서비스 상태라고 할 수는 없지만, 문제가 되는 서비스를 배제함으로써 마치 100% 동작하는 것처럼 보이도록 할 수 있다. 이것은 매우 중요한 의미인데, 다음의 두 가지 효과를 얻을 수 있기 때문이다.
▶ 고객이 서비스에 어딘가 이상한 부분을 찾을 수도 있겠지만, 전체 서비스를 이용하는 데는 지장이 없다. 따라서 사용자의 서비스 경험에는 큰 이상이 발생하지 않는다.
▶ 서비스 운용에 있어, 특정 마이크로서비스의 장애가 다른 서비스로 들불처럼 번지는 것을 막을 수 있다. 기존 구성이라면 서비스 B의 장애로 인해 응답을 받지 못한 서비스 A는 지속되는 클라이언트 요청에 응답하기 위해 계속 서비스 B로 무리한 요청을 할 것이고, 사실상 다운 상태인 서비스 B는 응답할리 없으므로 이는 양쪽 모두 다운타임이 발생했음을 의미한다. 만약 서비스 A에 의존하는 서비스들이 B 외에도 C, D, E 등 많으면 많을수록 이는 전체로 장애가 서서히 번지는 것을 의미하며, 이때 마이크로서비스는 운영적인 장점을 전혀 가질 수 없는 상태가 된다.
거대한 오라클 DB의 장애가 전체 서비스의 다운타임을 야기하고, 이로써 천문학적 비용의 손실을 야기하는 것은 절대로 즐거운 일일 수가 없다. 그리고 이 오라클 DB가 복구되기 전까지 서비스가 지속적으로 다운타임을 갖는 것도 사업자 입장에서는 발을 동동 구를 일이 아닐 수 없다. 고객 역시 매일 자주 사용하던 서비스에 이런 문제가 발생한다면 아마도 서비스에 대한 신뢰도 하락과 함께 대체 가능한 다른 서비스를 찾아볼지도 모르겠다.
넷플릭스는 이런 마이크로서비스 전환에 있어 가히 핵심이라고 할 수 있는 ‘의존성이 있는 서비스 간 발생 가능한 연속 장애 발생’을 기술적으로 서킷브레이커 도입을 통해 방지했는데, 이것이 바로 넷플릭스 오픈소스SW인 ‘히스트릭스(Hystrix)’다. 해당 깃허브 페이지(https://github.com/Netflix/Hystrix/wiki)에 설명된 핵심내용을 나타내면 다음과 같다.
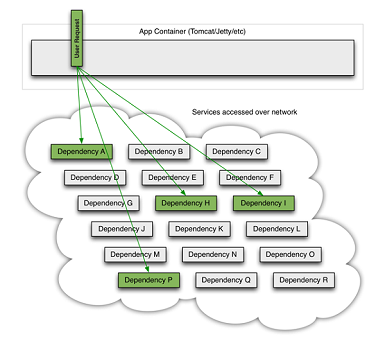
위 이미지는 모든 게 정상 동작할 때 서비스의 모습을 나타낸다. 하나의 사용자 요청을 처리하기 위해서 의존성이 있는 다수의 백엔드 서비스를 문제없이 참조중이다. 하지만 이들 중 하나의 서비스에 문제가 발생하면 아래와 같은 문제가 발생한다.
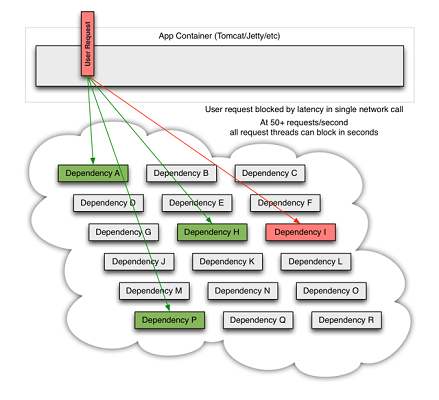
의존성 I의 서비스에 문제가 발생하면서 사용자의 응답은 지연시간이 증가하게 된다. 이는 때에 따라 타임아웃으로 이어져 다른 A, H, P 서비스의 응답이 소용없게 되는 결과를 만들거나, 동일한 요청을 처리하기 위해 다시 동일한 요청들이 발생할 때 부하를 증가시킨다.
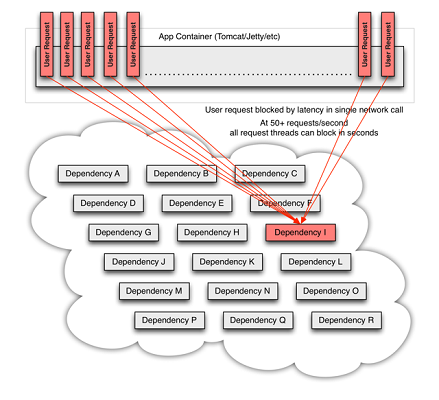
처리시간이 증가한 요청은 결국 켜켜이 쌓여 전체 서비스에 문제를 발생시킨다. 이 요청을 받는 특정 프로세스는 결국 자원을 전부 사용하게 되고, 이로 인해 의존성 I의 서비스는 사용자 요청을 처리하는 다른 서비스를 서비스 불능 상태로 만들어버린다.
이러한 전통적인 방식의 처리는 마이크로서비스 구성에서 쉽게 다른 서비스를 사용 불능 상태로 만들어버린다. 사용 불능 상태가 몇 개의 서비스에서 반복되면, 이는 전체 서비스의 다운타임으로 연결돼 결국 마이크로서비스의 장점을 매우 희석시키는 결과를 낳는다.
이렇게 처리하는 대신, 서킷브레이커를 사용하면 아래와 같이 개선할 수 있다.
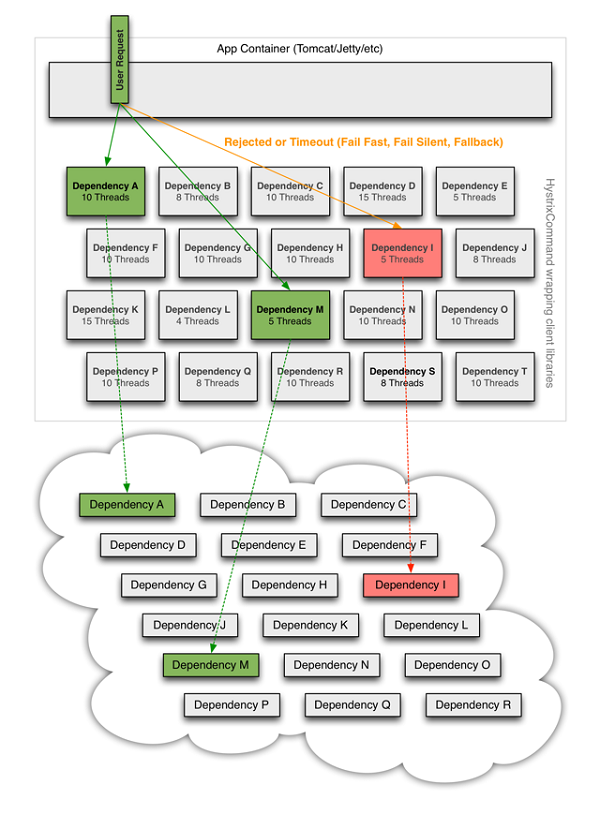
각 서비스에 대한 fallback은 해당 서비스에 문제가 발생했을 때 실제 요청을 전달하는 게 아닌, static fallback 메시지를 응답하도록 한다. 따라서 서비스 I에 문제가 발생한 게 감지되면 바로 이 지정된 fallback을 응답하게 되며, 서비스 I가 다시 정상적인 상태가 될 때까지 이렇게 동작한다. 그리고 정상인 상태로 되돌아오면 사용자 요청은 다시 포워딩된다.
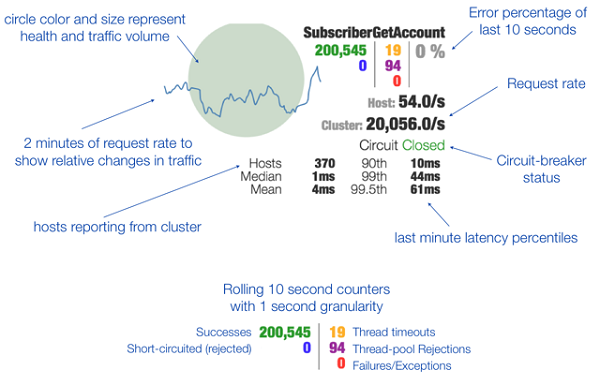
위의 그림은 Hystrix 대시보드를 통해 살펴보는 서킷브레이커의 모니터링 화면이다. 이 모니터링은 하나의 마이크로서비스에 대해 매우 많은 정보를 포함하고 있다. 지난 10초간 에러 발생률, 정상 처리된 요청 숫자, 요청 증감 그래프, 초당 트래픽 처리율, 서비스 요청에 대한 응답시간 등을 나타내고 있다.
이런 각종 지표에 이상이 생기면, 개발자는 fallback 메시지를 응답하도록 서비스를 구성할 수 있다. 기존 시리즈에서와 마찬가지로, 서킷브레이커 역시 매우 쉬운 방법으로 구현할 수 있다. 이 구현방법에 대해 다룬 스프링 페이지(https://spring.io/guides/gs/circuit-breaker/)의 내용을 간략하게 설명하도록 한다. 코드는 깃허브(https://github.com/spring-guides/gs-circuit-breaker)에서 참조 가능하다.
스프링 이니셜라이저로 생성되는 애플리케이션에서는 아래 의존성을 pom.xml에 추가한다.
| <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-hystrix</artifactId> </dependency> |
코드 전개에 앞서 아래의 어노테이션 추가로 해당 마이크로서비스에서 서킷브레이커를 활성화할 수 있다.
| @EnableCircuitBreaker |
아울러, fallback 메시지 구현 샘플은 아래와 같다.
| package hello;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand; import java.net.URI; @Service private final RestTemplate restTemplate; public BookService(RestTemplate rest) { @HystrixCommand(fallbackMethod = "reliable") return this.restTemplate.getForObject(uri, String.class); public String reliable() { } |
이번 호에서는 클라우드 기반 서비스에서 마이크로서비스로 구성된 전체 서비스의 장애 번짐을 방지하기 위해 매우 중요한 서킷브레이커의 사용에 대해 알아봤다. 물론 이번에 소개된 내용은 GET, 즉 read 요청에만 해당되는 것이기는 하지만, 그래도 이러한 구조의 반영은 서비스를 더욱 더 견고하게 만들어 다운타임에 강하게끔 만들어준다.
넷플릭스 Zuul이 게이트키퍼 및 요청의 프로그래매틱 분산 능력을 통해 서비스 업데이트 및 이전 등과 같은 다양한 기능을 구현할 수 있었다면, 서킷브레이커는 의존성 있는 마이크로서비스들 간 장애 확산을 방지하는 매우 중요한 기능을 한다. 따라서 마이크로서비스 아키텍처 적용에는 서킷브레이커 반영이 필수적이라 할 수 있다.
위 링크는 지금까지 연재된 내용을 다시 한 번 되짚어볼 수 있는 유튜브 영상이다. 넷플릭스 부장의 설명에 한글자막이 달린, 아주 유용한 세션이 되리라 믿어 의심치 않는다. 마이크로서비스에 관심이 있는 이들은 반드시 살펴보는 것을 추천한다. 당초 기획된 연재를 마치며, 마지막으로 다음호에서는 지금까지 내용을 간단히 정리해보고, 실무 관점에서 데브옵스, 마이크로서비스, CI/CD 등 전반에 대해 다뤄보고자 한다.