



이승학 버즈니 서비스엔지니어링 팀장

[컴퓨터월드] 많은 애플리케이션들은 서비스 사용성과 품질을 보장하기 위해 상당부분 ‘검색’ 기술에 의존하고 있다. 하지만 검색은 다양한 기술의 융·복합체로 쉽게 접근하기 어렵고 여러 가지 어려운 배경 지식을 필요로 한다.
이런 검색 기술의 접근성을 높이고 구현을 용이하게 해주는 솔루션들로는 아파치 루씬(Apache Lucene) 라이브러리에서 파생된 아파치 솔라(Apache Solr), 엘라스틱서치(Elasticsearch)등이 있다. 엘라스틱서치의 필수 구성 요소들을 통해 검색 엔진에 대한 이해도를 높이고 서비스로서의 활용 가능성과 효용 가치를 공유하고자 강좌(6회)를 신설했다. <편집자 주>
| 1. 엘라스틱서치 파이썬 클라이언트를 이용한 ‘검색’ 입문 (2018.9) 2. 엘라스틱서치로 검색엔진 전환하기 (2018.10) 3. 엘라스틱서치 활용(1): 자동완성 (2018.11) 4. 엘라스틱서치 활용(2): 로그 시스템 (이번호) 5. 엘라스틱서치 단계별 최적화 6. 검색엔진 관리 자동화 |
서비스 또는 시스템에서 일어나는 모든 일련의 작업들은 로그를 발생시킨다. 로그는 시스템의 모든 기록을 담고 있는 데이터이다. 이러한 로그 데이터는 서비스 품질 분석, 인프라 관리, 보안 이상징후 탐색 등 다방면으로 활용된다.
많은 이슈가 됐던 IT 보안 등 서비스의 이상 징후에 대비할 수 있는 방안으로 로그 데이터 관리에 대한 중요성이 대두되고 있다. 모든 로그 또는 집중적으로 체크하고자 하는 로그 데이터를 수집하고 분석, 보관, 모니터링해 악의적 공격이나 자체적인 오류를 발견하며, 그 원인을 찾아 신속히 복구할 수 있다.
로그에 대한 중요성이 강조되고 있지만, 이러한 로그를 잘 적재하고 관리하고 분석할 수 있는 시스템을 구성하는 일은 쉽지 않다. 로그 시스템도 결국은 하나의 서비스이고 잘 관리되어야 하는 대상이기 때문이다. 다양한 로그 시스템을 위한 플랫폼이나 솔루션들이 존재하지만, 손쉽게 관리할 수 있고 유기적으로 시스템 구성이 가능한 제품은 많지 않다.
엘라스틱서치는 간편한 인덱싱 구조를 제공하며, 키바나(:Kibana)라는 훌륭한 시각화 툴을 제공 하고 있다. 여기에 믿을 만한 Log collector와 함께 한다면 강력한 로그 시스템을 구성 할 수 있다. 엘라스틱서치를 기반으로 가장 많이 구성되는 EFK스택을 직접 구축해보고 키바나가 제공하는 데이터 분석을 위한 유용한 기능들에 대해서 알아보도록 하자.
# EFK stack: Elasticsearch Fluentd Kibana
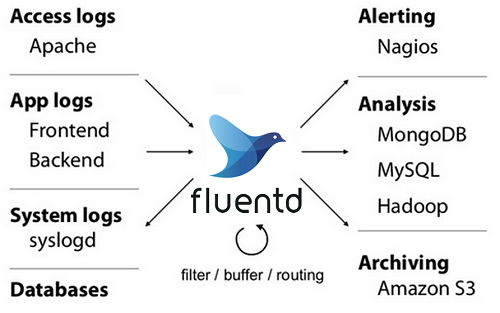
EFK 스택을 구성하기 앞서 fluentd에 대해 간단히 살펴보자. fluentd는 C와 Ruby로 개발된 로그 수집기다. HTTP, TCP의 다양한 소스로부터 로그를 수집한다. 수집된 로그는 이벤트로 처리되며, 원하는 형태로 가공돼 엘라스틱서치, AWS S3, 몽고DB 등의 저장소로 전달될 수 있다. 주요 특징으로는 메모리와 파일 기반의 버퍼 시스템으로 데이터 유실을 예방해주며, 고가용성 구성도 가능하다.
로그가 처리되는 단위인 이벤트는 tag, time, record로 구성이 된다. tag는 이벤트를 보낼 곳에 대한 구분 값, time은 이벤트 발생 시간, record는 json형태의 로그 데이터 상세 내용이 된다.
엘라스틱서치, 키바나, fluentd, 테스트를 위한 httpd를 포함한 docker-compose를 구성해 EFK를 구성해 보자. 예제에는 엘라스틱서치 6.5, 키바나 6.5를 사용했으며, fluentd의 엘라스틱서치 플러그인은 1.9.5가 사용됐다.
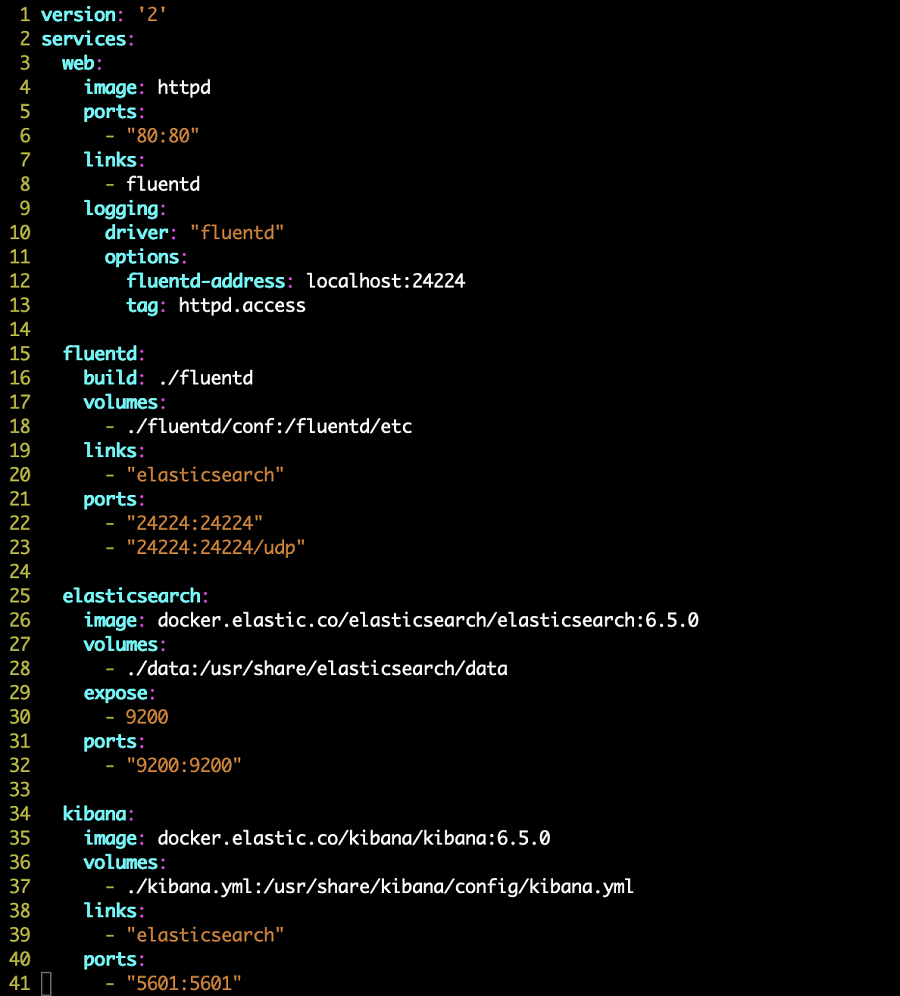
필자는 명시적으로 fluentd의 엘라스틱플러그인의 버전을 1.9.5를 사용하기 위해 docker 이미지를 새로 빌드하도록 과정을 포함했다. 1.9.5이하의 버전을 사용한다면 Content-Type header관련 NotAcceptable 에러를 경험하게 될 것이니, 꼭 확인하고 사용하길 바란다.
1

fluentd 설정은 엘라스틱서치에 인덱싱하기 위한 적재 주소와 인덱스 이름이나 타입 등의 로그 식별을 위한 기본적인 내용을 포함했다.
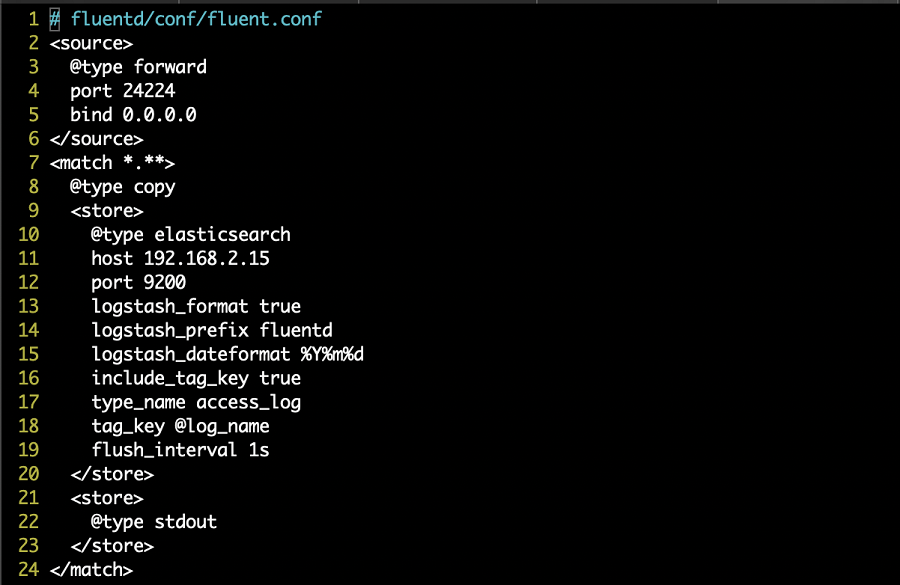

EFK를 사용하기 위한 관련 설정들이 준비가 되었다면 docker-compose를 사용해 실행해보자. 특별히 설정 실수를 하지 않았다면 문제없이 연결될 것이고, 로컬호스트에 5601포트로 접속하면 키바나가 실행된 화면을 확인 할 수 있을 것이다.

키바나에서 추가로 설정을 해줘야 하는 부분이 있는데, 엘라스틱서치로 인덱싱된 데이터를 관찰하기 위해서는 인덱스 패턴을 추가-설정 해줘야 한다. 모든 로그 데이터를 확인하고자 한다면 와일드카드(*)를 사용하면 되지만, 쓰임에 맞게 명시적으로 분할해 사용하는 것을 추천한다.
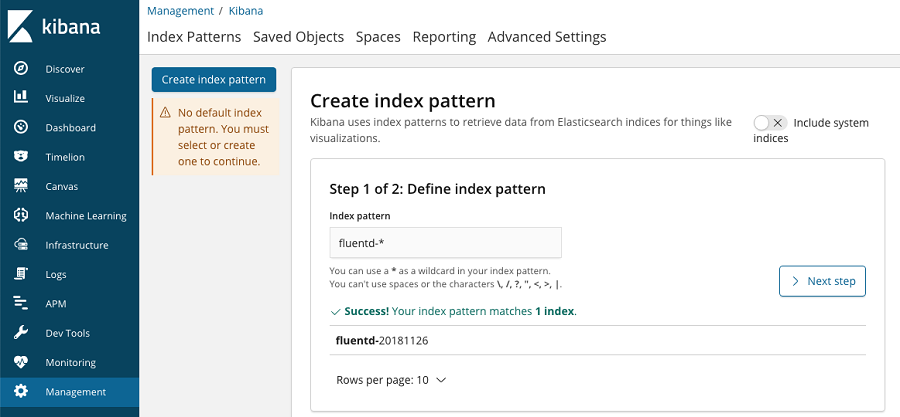
이로써 로그 분석을 위한 EFK 스택이 완성이 됐다. docker-compose에 익숙하지 않는 독자라면 약간의 어색함을 가질 수 있겠지만 간단한 과정을 통해 로그 수집부터 인덱싱 그리고 분석 도구를 갖춘 어엿한 로그 시스템을 구축하게 됐다. 여기서 더 나아가 키바나에서 제공하는 다양한 도구를 살펴보도록 하자.
# Kibana
키바나 6.5를 기준으로 로그 분석을 위한 도구로 Discover, Visualize, Dashboard, Timelion, Canvas 등이 존재한다. 이 중에서 필터와 검색을 사용한 로그 확인을 지원하는 Discover와 시각과 제작 도구인 Visualize를 이용하여 Dashboard를 구성하는 방법을 살펴보도록 하자.
Discover는 검색창에 직접 쿼리를 입력하는 방식과 맵핑된 필드들을 사용해서 필터를 사용하는 방식을 지원한다. 먼저 검색창에 쿼리를 입력해 사용해 보자. 참고로 검색 쿼리를 만들기 익숙하지 않은 사용자를 위해 그림과 같이 Options에 쿼리 자동완성 어시스트 기능을 활성화할 수 있기 때문에 쿼리에 대한 부담을 갖지 않아도 된다.

필터를 사용하는 방법은 매우 간단하다. UI가 단계별로 가이드 해주기 때문에 누구나 어려움 없이 사용할 수 있다. 필터를 적용할 필드와 필터링 행위의 종류 그리고 적용될 값을 기입해주면 필터가 완성된다.
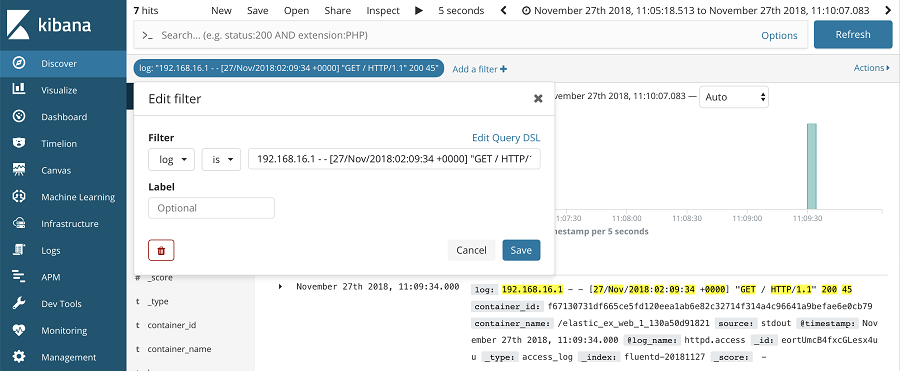
Discover에서 검색 쿼리와 필터를 이용해 원하는 로그를 매칭하는 방법을 간단하게 살펴봤다. 물론 기존에 엘라스틱서치를 사용하면서 알고 있듯이 검색 쿼리와 필터는 동시에 사용이 가능하다는 점을 알아야 한다. 로그의 범주를 설정하고자 한다면 필터를 적극 활용하고 특정 로그 데이터를 매칭 하고자 한다면 검색 쿼리를 사용해 보다 효율적으로 사용할 수 있을 것이다.
Discover을 통해 raw-data 형태의 로그를 확인해봤다면, Visualize를 사용해서 의미 있는 로그를 추출해서 가독성이 높은 그래프 또는 차트를 만들어 보자. Visualize는 Basic Charts, Data, Maps, Time Series, Other의 세부 그룹으로 구성돼 있으며, 키바나 6.5 기준으로 18개의 타입을 지원한다.
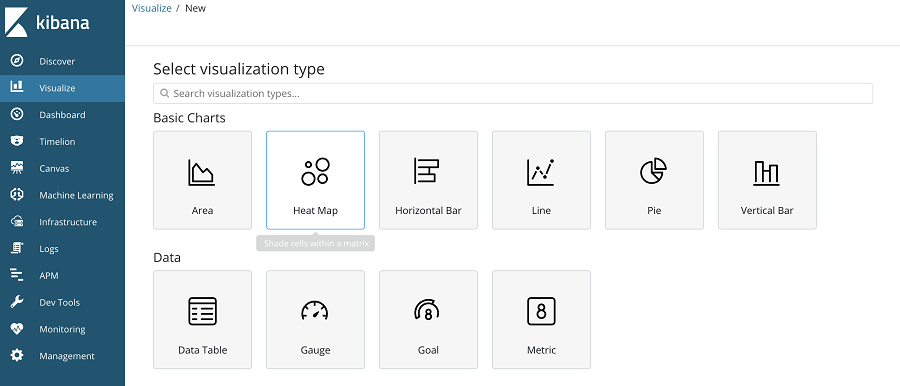
다양한 타입 때문에 사용하는 데 있어 어려움이 있을까 걱정하겠지만 차트 형태를 고르듯이 표현 방법의 차이 정도로 인식하면 된다. 생성 시 필요한 요소들을 Metrics로 정의하는 방법은 공통 사항이기 때문에 대상 로그 데이터를 선정하는 것과 표현 방식에 대해서만 고민할 수 있는 이점이 있다. 추가로 Metrics의 사용가능한 값들은 그래프와 차트라는 특성 때문에 숫자로 인덱싱된 필드만 사용할 수 있음을 유념하자.

의미 있는 로그 데이터들을 선정하고 Visualize로 주요 지표들을 선정했다면 한눈에 보기 쉽고 연관성 있는 지표들 간의 흐름을 Dashboard를 통해 만들어보자. Dashboard 화면은 Discover와 유사하다. 차이점은 다양한 지표를 한 화면에 표현 해준다는 것이고, 그 지표들을 다시 검색 쿼리와 필터로 추가 정제가 가능하다는 점은 유사점이다.

# 마치며
로그를 잘 분석하기 위해서는 안전하게 데이터가 수집돼야 하고, 정확하게 필요한 위치에 적재 돼야 한다. 처음부터 로그 시스템을 구축하려면 독자적인 솔루션을 만들어내는 정도의 피나는 노력이 필요하다. 하지만 EFK스택을 통해 간편하게 로그 시스템을 구축 할 수 있음을 확인했다. 이를 기반으로 키바나를 통해 로그의 흐름과 분석하고자 하는 내용을 충분히 인지 할 수 있으리라 생각한다.
데이터 수집에 사용된 fluentd 외에도 엘라스틱에서 제공하는 Logstash를 사용해보는 것도 추천한다. 범용적인 사용성 측면에서는 fluentd가 좋은 역할을 해주고, 많은 사람들이 쓰고 있다는 무언의 검증적인 요소가 있지만 엘라스틱서치를 기반으로 구축을 한다면, 좀 더 상호 최적화가 잘 돼있는 Logstash의 사용도 괜찮다.
엘라스틱서치를 통해 검색엔진만의 활용성을 넘어서서 다양한 시스템에 적용 될 수 있는 부분을 전편 자동완성과 본편 로그 시스템을 통해서 알아봤다. 이 외에도 검색이라는 기능이 주는 근본의 활용 범위는 무궁무진하기 때문에 다양한 사례를 확인할 수 있을 것이다.