



버즈니 AI Lab 임영수 리서치엔지니어
[컴퓨터월드]

1. 개요
인터넷으로 무언가를 사고자 할 때 소비자는 상품을 검색한다. 그리고 검색 결과에 나온 상품들을 하나하나 살펴본다. 내가 원하는 옵션인지, 아니면 더 좋은 옵션이 있는지, 같은 조건인데 더 저렴한 가격의 상품이 있는지. 상품 목록을 끊임없이 훑어본 결과, 소비자는 원하는 조건 내에서 더 합리적인 가격의 상품을 구매한다.
‘합리적인 쇼핑’은 ‘합리적인 가격’과 큰 유사성을 가진다. 비교적 타협의 여지가 있는 상품의 옵션에 비해 가격은 동일한 조건 하에 낮을수록 좋기 때문이다. 하지만 대부분의 경우 쇼핑은 합리적일지 몰라도 과정은 합리적이지 못한 편이다. 수많은 상품들 사이에 흩어져 있는 동일한 상품들을 하나하나 살펴보는 과정이 그렇다. 꼼꼼한 소비자라면 애써 찾아낸 상품보다 괜찮은 상품을 구매 뒤에 발견해서 괜히 손해본 것 같은 기억이 있을 것이다.
그렇다면 동일한 조건을 가진 상품들의 목록을 모아 놓는다면 번거로움을 줄일 수 있지 않을까? 동일한 상품 목록이 존재한다면 불편함이 줄어들고 합리적인 쇼핑이 더더욱 편리해질 것이다. 그뿐만 아니라 추천, 랭킹화 등 다양한 분야에서 가치를 창출할 수 있을 것이다.
버즈니가 운영 중인 모바일 홈쇼핑 포털 앱 ‘홈쇼핑모아’에서는 이러한 생각을 실현하고자 끊임없이 고민하고 연구 중이다. 그 결과가 바로 오늘의 주제, 카탈로그다.
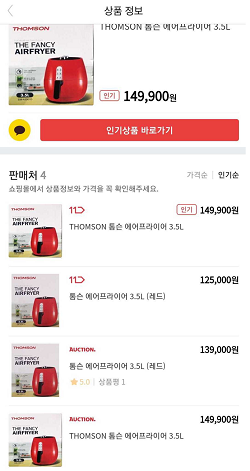
홈쇼핑모아 가격비교 화면
2. 카탈로그 분류 모델
카탈로그라는 단어는 상품의 목록 또는 홍보물이라는 의미를 가지고 있다. 버즈니에서는 같은 상품의 목록을 구성한다는 의미에서 동일상품 목록에 카탈로그라는 명칭을 사용하기로 했다. 이 기고문에서는 ‘홈쇼핑모아’의 카탈로그가 어떤 기술을 통해 구성되는지를 서술하려고 한다.
사람의 눈으로 볼 때 여러 상품을 같은 상품인지 아닌지 분류하는 일은 어렵지 않다. 이름과 이미지만으로 비교해도 열에 아홉은 알 수 있다.
그러나 매일매일 등록되는 수많은 상품들을 사람이 일일이 분류하기는 어렵다. 기술적/인적 비용의 한계는 물론이거니와 분류의 방법론/기준점 차이 같은 세부적인 문제들 또한 존재한다. 버즈니는 이러한 문제점들을 해결하기 위해 딥러닝 기술을 활용해 카탈로그 분류 자동화 기술을 개발, 사용하고 있다.
자동화 기술은 크게 자동화 모델, 후처리 모듈의 2가지 단계로 구분된다. 자동화 모델은 딥러닝을 이용해 상품의 동일 유무를 판별하는 기술이다. 통계 기반의 초기 분류모델에서 리서치를 진행한 결과 딥러닝 모델을 구성했으며, 자체적으로 구축한 4,000만 개의 상품 데이터를 학습시켰다.
후처리 모듈은 정교한 결과물을 얻어내기 위한 단계다. 자동화 모델만으로는 걸러낼 수 없는 세세한 hard feature들을 직접 연구하고 적용해 보다 정확한 결과물을 얻을 수 있도록 한다. 상품명 Segmentor, 불용어 처리, 카테고리 기반 필터링 등 다양한 기술이 포함되어 있다. 후처리 모듈까지 거친 결과물은 그룹 간 통합 과정을 거쳐 서비스에 이용된다.

카탈로그 분류에 대한 본격적인 리서치가 진행되기 전에는 Regression 모델을 초기 모델로 활용해 분류를 수행했다. Regression 모델이란 데이터와 결과물의 인과 관계를 분석하여 결과를 도출하는 일종의 통계 기반 모델이다. 상품의 여러 정보를 feature화한 데이터와 상품 유사도 여부의 인과 관계를 도출하는 식의 모델인 것이다.
상품 feature는 상품명, 가격 등의 다양한 정보들을 재가공하여 사용했다. 이 초기 모델과 feature에서 인사이트를 얻은 후 개선점을 연구하여 현재의 딥러닝 모델을 구성했다.
카탈로그 딥러닝 모델은 상품명 텍스트 정보 / 이미지 정보 총 두 가지의 정보를 feature화해 별도의 모델을 거쳐 사용된다. 텍스트 정보는 자소 기반 character-CNN 기반의 모델을 사용한다. 자소 기반 character-CNN이란 한글의 자음과 모음을 분리하는 것을 전처리로 하여 input으로 하는 CNN을 뜻한다.

초기 딥러닝 모델에서는 word embedding을 사용하여 텍스트 전처리를 진행했다. 띄어쓰기 기반의 tokenizer나 glove와 같은 word2vec을 이용해 단어 단위의 embedding을 구성해 사용해봤으나, 여러 단점들이 발견됐다.
가장 큰 문제는 OOV(Out Of Vocabulary)였다. Word embedding은 사전에 학습한 단어들을 벡터화한다. OOV는 이렇게 구성된 word embedding을 학습할 때 존재하지 않았던 단어를 의미한다. 보통의 NLP 문제에서는 이런 단어들을 위한 Unknown 토큰을 별도로 두어 처리하지만, 문제를 해결하기에는 좋은 방법은 아니다. 예시와 함께 살펴보자.
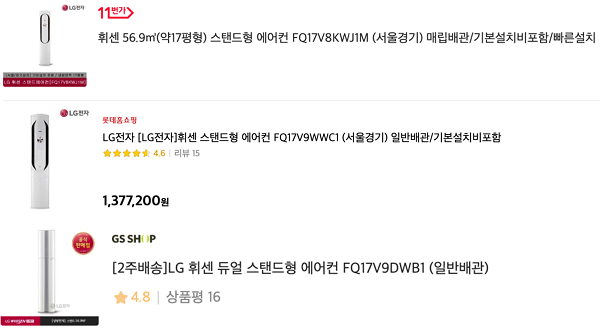
예시의 상품들은 모두 같은 제조사의 같은 상품들이다. 그러나 세 상품은 상품 모델명이 다르기 때문에 동일한 상품이 아니다. 예시의 상품 모델명뿐만 아니라 학습 당시에는 존재하지 않다가 근래 갑자기 이슈로 떠오른 키워드(예시로 KF94 마스크를 들 수 있겠다), 신상 의류 브랜드명 같은 경우는 word embedding을 구성하기가 불가능하다. 물론 가능하다면 단어 간 의미를 알기에 이만한 방법이 없으나, 실제 데이터는 그렇게 이상적이지 않다.
이를 해결하기 위한 방법론이 자소 기반 character embedding이었다. 알파벳이야 애초에 음소문자기 때문에 글자 단위로 떼어낼 수 있으나 한글은 그렇지 않다. 따라서 한글도 가장 작은 단위로 쪼개 character embedding을 적용했다.
이 character embedding은 별도의 embedding 값 학습이 아닌 고정된 고유값을 부여하는 방식으로 진행했다. 자소 간 상관관계를 학습하는 것이 오히려 악영향을 끼칠 것으로 우려했기 때문이다. character embedding 실험 결과 word embedding을 사용할 때보다 약 3%의 정확도 향상을 얻어낼 수 있었다.
embedding의 결과물들은 CNN을 통해 처리된다. RNN과 같은 상품명 데이터의 연속성을 학습하는 네트워크보다는 나열된 단어들 자체에 집중하고자 하는 의도다.
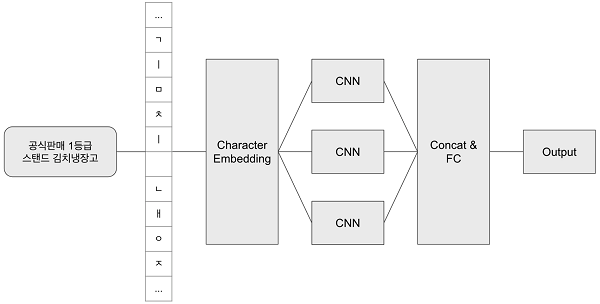
이미지 데이터는 사전에 학습된 이미지 분류 모델을 통해 feature화된다. 이미지 분류 모델은 VGG, YOLO를 비롯해서 지속적인 리서치가 진행되고 있으며, 그 중 최적의 정확도를 보이는 모델을 사용했다.
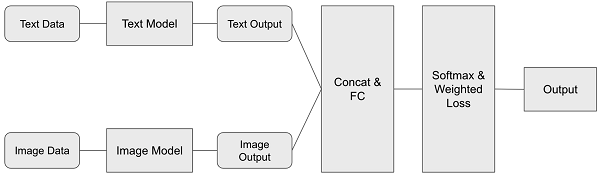
최종적으로는 텍스트 모델과 이미지 모델의 결과 벡터를 통합하여 학습한다. 결과 벡터에는 상품의 텍스트 정보와 이미지 정보가 각각 포함되어 있다. 결과 모델은 상품간의 유사도를 Output으로 내보낸다.
3. 분류 모델 후처리
지속적인 리서치를 통해 딥러닝을 적용하고 성능은 높아졌으나 아직 모델의 결과물은 완벽하지 않다. 모델의 아쉬운 점을 보완하기 위해 존재하는 것이 후처리 모듈이다. 상술하였듯 후처리 모듈에는 자동화 모델이 잡아내기 힘든 부분들을 직접 필터링해주는 역할을 한다.
상품에 존재하는 여러 정보들을 Segmetor로 추출하고, 불용어나 Stopword가 존재하는지 필터링한다. 잘못된 정보가 매칭되지는 않았는지, 상품의 카테고리는 같은지 등을 파악한 뒤 상품 카테고리 별 모델/이미지 유사도 threshold를 적용해 걸러낸다. 카테고리마다 모델 정확도의 최솟값을 지정해두어 기준에 미치지 못하는 유사도의 경우 그룹핑을 하지 않는 방식이다.

이미지 유사도 또한 마찬가지다. 이미지가 얼마나 유사한지 파악하고, 일정 기준 이상 유사하지 않을 경우 걸러낸다. 동일한 상품이라면 이미지 자체를 넘어서 이미지에 포함된 상품 이미지의 유사도까지도 얼마나 유사한지 판별해야 하기 때문이다.
필터링을 거쳐 살아남은 그룹들은 그룹간 동일한 상품이 겹쳐 있지는 않은지 최종적으로 통합 과정을 거친 뒤에 하나의 그룹으로 남게 된다.
4. 결론
카탈로그 분류 작업은 아직 미흡한 점이 많다. 텍스트/이미지 모델에 대한 지속적이고 효율적인 리서치가 필요하며, 그 결과 지속적인 성능 향상이 동반되어야 한다. Supervised Learning에 국한되지 않은 새로운 접근법 또한 적용해볼 법하다. 모델뿐만 아니라 데이터셋에 대한 고민도 필요하다. 데이터가 충분한지, 충분하다면 양질의 데이터로 구성이 되어 있는지가 보장되어야 하며 그래야만 모델의 완성도가 보장될 수 있다.
자동화된 분류 작업의 틀은 완성되어 가고 있다. 그러나 성능을 보증하는 것은 결국 사람이어야 한다. 서론에서 서술했듯이 모든 작업을 사람이 할 수 없기에 자동 분류 시스템을 구축했으며, 많은 시간과 비용을 절약할 수 있게 되었다. 그러나 기계의 계산된 정확도와 소비자의 체감 정확도는 다를 수 있다. 높은 정확도를 가진다 해도 결국엔 확률이니 말이다.
딥러닝의 오류 개선 방식은 정답과의 차이점에서 발생한 Loss를 네트워크 자체에 역전파하는 것이다. 사람이 Loss값을 직접 계산할 수는 없겠지만, 사람의 눈에 보이는 차이점은 결코 무시 할 수 없다고 생각한다. 지속적인 모니터링을 통해 서비스 질의 향상과 자동화 작업 피드백의 두 마리 토끼를 잡을 수 있을 것이다. 천천히, 하지만 옳게 발전한다면 언젠가 완전히 자동화된 카탈로그 분류가 가능할 것이라고 생각한다.