본지, 제17회 ‘2020 데이터 컨퍼런스’ 개최
[컴퓨터월드] 본지(컴퓨터월드/IT DAILY)가 제17회 ‘2020 데이터 컨퍼런스’를 지난달 26일 양재동 엘타워에서 개최했다. ‘데이터 컨퍼런스’는 지난해까지 ‘BI 컨퍼런스’라는 이름으로 열렸으나, 비즈니스 인텔리전스(BI)도 결국은 데이터로부터 출발한다는 점을 다시 한 번 상기하고, 본격적으로 꽃을 피울 것으로 기대되는 ‘데이터 경제’ 트렌드에 발맞추자는 의미에서 올해부터 새로운 이름으로 행사를 열게 됐다.
코로나19로 전 세계가 휘청거린 2020년은 국내 IT업계에게는 ‘데이터 경제(Data Economy)’가 본격화된 해로도 기억될 것으로 보인다. 바로 데이터 3법 개정안이 통과되고 정부의 ‘디지털 뉴딜’ 정책의 중심에 ‘데이터 댐 구축’이 자리하는 등 데이터의 중요성이 그 어느 때보다 강조된 한해이기 때문이다. 이제 데이터는 성장의 한계를 맞은 기존 산업이 희망을 걸 수 있는 새로운 미래 성장 동력으로 떠올랐다. 기업들은 데이터를 수집하고, 분석하며, 활용함으로써 기존 업무를 효율화하고 비즈니스 성과를 극대화하고자 고심하고 있다.
이에 2020 데이터 컨퍼런스는 “‘DATA & AI, BI’ 어디까지 왔나?”를 주제로 인공지능(AI)을 통해 한 단계 진화를 시도하는 BI는 물론, 데이터를 수집하고, 활용하며, 또 보호할 수 있는 방안까지 모두 한 자리에서 들을 수 있는 자리로 마련했다.

이번 ‘2020 데이터 컨퍼런스’는 한국데이터마이닝학회장을 맡고 있는 김용대 서울대학교 데이터사이언스학과 교수의 축사로 문을 열었다.

김용대 교수는 “4차 산업혁명의 중심에는 데이터가 있다. 많은 조직들이 데이터를 확보하기 위해 노력하고 있으며, 정부 또한 데이터 경제 확산에 투자하고 있다. 데이터 경제로의 전환을 위해 정부와 기업들이 발 빠르게 움직이고 있다”면서, “특히 코로나19로 촉발된 비대면 트렌드는 문화와 사회를 급격하게 변화시키고 있다. 모든 산업군에서 변화가 일어나고 있으며, 특히 유통분야는 온라인 환경이 더욱 활성화되고 있다”고 말했다.
이어 “조직이 데이터를 활용하기 위해서는 데이터의 수집, 정제, 분석 등을 위한 시스템과 방법론이 필요하다. 이번 데이터 컨퍼런스를 통해 데이터 분야의 최신 트렌드를 공유할 수 있기를 기대한다”고 덧붙였다.
“SW 로봇으로 코딩 자동화 실현한다”
2020 데이터 컨퍼런스의 첫 번째 키노트는 배영근 비아이매트릭스 대표가 ‘4차 산업혁명시대 SW로봇과 함께 시스템 구축을’이라는 주제로 발표했다. 배영근 비아이매트릭스 대표는 “이번 발표를 통해서는 통합 UI 솔루션 트렌드와 시스템 구축을 위한 SW 로봇을 살펴보고자 한다”고 말하며 발표를 시작했다.

배영근 대표에 따르면, 일반적인 SW의 UI는 ▲비즈니스 인텔리전스(BI)/OLAP ▲대시보드 ▲리포트 ▲UI/UX ▲플래닝/시뮬레이션/SCM ▲JSP/자바 등으로 세분화돼 있었다. 하지만 각각의 솔루션을 구매 및 운영함으로써, 조직들은 구매, 개발, 운영 비용 모두가 증가하고, 솔루션을 모두 사용할 수 있는 전문가를 구하기 어렵다는 문제가 있었다. 솔루션이 다양하게 운영돼 왔던 이유는 기술력이 부족했기 때문이다. 리포트 솔루션은 다차원 분석이 안되는 등 기술과 기능이 부족했기 때문에 솔루션이 세분화됐던 것이다.
기술이 발전하면서 통합 솔루션이 등장하기 시작했다. 통합 솔루션의 등장한 배경은 개발 및 구매 비용을 절감할 수 있다는 장점 때문이다. 또한 전문가 육성에서도 통합 솔루션이 유리한 점이 많다.
비아이매트릭스는 2005년 설립 이후 BI, 인공지능(AI), 협업지능(CI, Collaboration Intelligence) 등과 관련된 기술을 개발해왔다는 점을 강조했다. 배 대표는 “2005년 비아이매트릭스를 설립하면서 BI 기술 개발에 주력했다. BI 기술로는 2012년 장영실상을 수상하기도 했다. 2010년대에는 AI가 트렌드로 떠오르면서, 비아이매트릭스 역시 AI 관련 기술 개발에 나섰다. 이 결과 ‘아이스트림(i-STREAM)’ 솔루션을 출시했으며, 2018년 장영실상을 수상했다. 2017년부터는 CI 기술을 선보이고 있다. 더불어 EPA(Excel Process Automation) 방법론, AUD(Autimated UI Development) 방법론 등을 개발했으며, 이를 기반으로 SW로봇을 이용한 시스템 구축 방안을 제시하고 있다”고 말했다.
이어 배 대표는 비아이매트릭스의 SW로봇 3가지를 소개했다. DB봇, UI봇, 프로세스봇 등 3가지로 구성된 SW로봇을 활용하는 방안을 시연했다. 배 대표는 “SW로봇은 단순 반복적인 업무를 자동화함으로써 개발 생산성을 향상시킬 수 있는 것이 특징”이라고 강조했다.
이어 “아직 SW로봇을 통해 100%개발하는 것은 불가능하다. 80%정도를 자동화한 로봇과 초급 개발자를 투입하고, 복잡한 개발업무에 고급개발자를 집중할 수 있도록 함으로써 개발자 업무의 효율성을 높일 수 있다. 더불어 개발속도를 10배 이상 높일 수 있으며, 개발방법을 표준화하고 개발비용 또한 절감할 수 있다”면서 “개발자의 주요 업무는 분석, 설계, 구현, 테스트다. 코딩에만 집중하는 환경을 탈피해야 한다”고 강조했다.
“데이터 경제 시대, 데이터 유통 플랫폼에 주목하라”
이어진 두 번째 세션에서는 안현주 데이터스트림즈 본부장이 ‘데이터 거버넌스 기반 데이터 거래 유통 플랫폼’이라는 주제로 발표를 진행했다.

안현주 본부장은 “기존 산업과 ICT 융합하는 4차 산업혁명의 특징은 ‘데이터 혁명’이며, 데이터를 매개로 한 새로운 생태계인 ‘데이터 경제’의 중요성이 부각되고 있다”면서 “2013년을 기점으로 전 세계적으로 빅데이터에 대한 투자가 늘어나고 있으며, 빅데이터 수행을 통해 도출된 ‘정보의 자산화’에 대한 필요성이 대두됐다. 가트너는 기존 산업의 공급망 관리체계를 참조해 ‘인포노믹스(Infonomics)’라는 개념을 제시했다”고 말하며 발표를 시작했다.
안현주 본부장은 데이터 거래 유통 플랫폼 발전을 ▲데이터 거버넌스(Data Governance) ▲서비스형 데이터(Data as a Service) ▲데이터 공유 및 거래(Data Sharing & Exchange) ▲데이터 마켓플레이스(Data Marketplace) 등 4단계로 구분해 설명했다.
먼저 데이터 거버넌스는 데이터 활용의 기반을 마련하는 단계다. 이 단계에서는 데이터 기반 서비스 구현을 위해 거버넌스를 수립하고, 메타데이터 체계의 기반을 마련한다. 더불어 데이터 표준 및 품질을 확보까지를 포함한다. 서비스형 데이터 단계에서는 데이터 기반의 서비스를 구현한다. 데이터 카탈로그 서비스, 클라우드 기반 데이터 안심 구역 분석 환경, 데이터 가상화 기반 융합 분석 환경 등이 요구된다.
본격적인 데이터 유통이 시작되는 것은 3단계인 ‘데이터 공유 및 거래’다. 이 단계에서는 개방형 데이터스토어가 구현된다. 데이터 거래 및 유통 메타를 구현하고, RDF를 기반으로 내외부 플랫폼과의 데이토 공유체계를 만들게 된다. 다만 이때는 직접거래 방식보다는 공유기반의 중개 및 교환 방식의 거래가 주를 이룬다.
마지막 4단계 ‘데이터 마켓플레이스’에서는 종합거래형 데이터스토어를 완성한다. 데이터 거래를 위한 가격정책을 수립해야 하며, 데이터 상품을 평가할 수 있는 툴이 필요하다. 더불어 데이터 거래관련 법률이나 가이드라인이 수립돼야 하며, 직접 거래를 위한 기술(빌링 서비스 및 블록체인 등)도 고려돼야 한다.
이어 안 본부장은 해외의 데이터 거래소 사례를 소개했다. 데이터 마켓플레이스 사례로는 미국의 액시엄(Acxiom)을 꼽았다. 액시엄은 3천 개의 데이터 속성을 기반으로 7억 명의 데이터를 관리하고 있으며, 마케팅 및 부정 사용 탐지를 위한 데이터 분석 서비스를 제공한다. 고객사들은 각자 보유하고 있는 고객 데이터를 액시엄의 데이터와 융합해 사용하고 있다.
데이터 거래 플랫폼은 상해 데이터 거래소를 꼽았다. 상해 데이터 거래소는 공공 및 민간 자본이 공동 출자해 설립된 법인으로, 공공과 민간의 데이터 융합 촉진을 목표로 운영되고 있다. 특히 상해 데이터 거래소는 결제, 업무, 기술 별로 레벨을 구분해 데이터 거래를 지원하고 있으며, 구매자/판매자간 신용 관계가 불확실할 때 제3자가 중계하는 매매 보호 서비스인 ‘에스크로 서비스’도 제공하는 것이 특징이다.
이어 안현주 본부장은 데이터스트림즈가 제공하고 있는 빅데이터 마켓플레이스 서비스 모델과 데이터 거래 유통 플랫폼 모델을 소개했다. 특히 데이터 거래 유통 플랫폼의 구축 경험을 소개하며, 주요 기능으로 ▲데이터 상품 메타 ▲데이터 맵 ▲블록체인 기반 원본 증명 등을 제공하고 있다고 설명했다.
“디지털 전환의 핵심은 프로세스 마이닝”
이어진 세 번째 세션에서는 김영일 퍼즐데이터 대표가 ‘디지털 프로세스 분석을 위한 이벤트 로그 기반 프로세스 마이닝의 활용 및 사례’라는 주제로 프로세스 마이닝을 소개했다.

김영일 대표는 “최근 코로나19 팬데믹으로 인해 비대면(Untact) 소비가 급증하고 있다. 모든 소비 및 업무에 디지털 트랜스포메이션이 나타나고 있는 것이다. 디지털 환경으로 바뀌면서 쉽게 프로세스를 설정하고, 검증, 변경할 수 있게 됐다”면서 발표를 시작했다.
김 대표는 주제인 프로세스 마이닝이 최근 주목받고 있다고 강조했다. 시장조사기관 가트너가 2019년 10대 전략 기술 중 디지털 트윈을 얘기하면서 프로세스 마이닝을 강조했다는 점을 예시로 들었다. 김 대표에 따르면, 프로세스 마이닝은 이벤트 로그를 통해 프로세스 모델을 도출하고, 이를 분석해 프로세스를 개선하는 것을 의미한다. 일련의 업무과정을 도식화해, 병목 및 반복 현상 등을 탐지, 분석할 수 있다.
프로세스 마이닝 분석 시스템은 문제가 해결될 때까지 ▲계획(Plan) ▲실행(Do) ▲검사(Check) ▲행동(Action) 등의 사이클을 반복한다. 퍼즐데이터는 프로세스 마이닝 분석 솔루션 ‘프로 디스커버리(Pro Discovery)’를 공급하고 있다. ‘프로 디스커버리’는 시스템 이벤트 로그 데이터를 기반으로 프로세스 맵을 자동으로 생성, 가시화, 분석할 수 있다. 김영일 대표는 이를 통해 ▲스마트 프로세스 이노베이션(Smart Process Innovation), 스마트 커스토머 익스피리언스(Smart Customer Experience), 스마트 RPA(Smart Robotic Process Automation) 등을 구현할 수 있다고 설명했다.
이어 김영일 대표는 ‘프로 디스커버리’를 활용한 프로세스 혁신 사례를 소개했다. 먼저 전통적인 프로세스 이노베이션에서 디지털 프로세스 마이닝을 기반으로 한 스마트 프로세스 이노베이션 사례를 설명했다. 김영일 대표는 “전통적인 프로세스 이노베이션은 컨설턴트가 직접 기업을 방문, 관찰을 통해 흐름만을 추정했다. 이를 통해 단순 데이터 통계 분석을 진행했기 때문에 비용은 비싸지만 효율은 적었다. 디지털 프로세스 마이닝으로 바꾼다면 이벤트 로그 데이터를 기반으로 분석하기 때문에 전체 및 개별 동선을 가시화하고, 다양한 필터를 연계해 다층 분석이 가능하다. 짧은 시간에 정확하고 다양한 인사이트를 발굴할 수 있어 고효율의 프로세스 혁신이 가능하다”고 말했다.
이어 김영일 대표는 공공 및 금융, 물류 등 다양한 분야에 프로세스 마이닝을 통한 프로세스 혁신 사례를 소개했다. 또한 금융, 교육, e커머스 등의 분야에서 고객 경험 향상을 위해 프로세스 마이닝을 활용한 사례도 공유했다. 프로세스 마이닝을 활용해 스마트 RPA를 구축한 사례로는 국내 한 반도체 기업을 꼽았다.
김영일 대표는 “프로세스 마이닝은 ▲프로세스 매핑 및 모델링 ▲조직 모델링 ▲SNS 분석 ▲RPA ▲회계 감사 컴플라이언스 ▲시뮬레이션 ▲프로세스 성과 분석 등으로 확장할 수 있다”고 강조했다.
“당장 실행 가능한 목표를 설정해 데이터 & AI 프로젝트를 추진하라”
오전 마지막 세션에서는 박준규 메가존 전무가 연단에 올라 ‘Data to AI, 작고 빠른 실행이 성공의 열쇠-고객사례를 통해 본 데이터 & AI 전략’이라는 주제로 발표를 진행했다.

박 전무는 기아자동차의 ‘오너스 매뉴얼(Owner’s Manual)’ 사례를 소개하면서, “애자일(Agile) 방법론을 최우선의 목표로 설정해야 하며, 당장 실행 가능한 목표를 설정해 데이터 & AI 프로젝트를 추진해야 한다”고 강조했다.
박준규 전무는 데이터와 AI가 4차 산업혁명의 기폭제가 됐다고 설명했다. 정형·비정형 데이터를 수집·분석해 새로운 통찰력을 확보한다는 욕구가 증가했고, GPU, TPU 등 하드웨어 기술의 진화와 머신러닝/딥러닝 등 프레임워크 개발로 AI 기술이 대중화된 것이 데이터 경제를 촉발시켰다는 것이다.
하지만 데이터를 활용하는 것은 기업들에게 큰 도전과제가 되고 있다. 빅데이터가 이슈가 되면서 수집되는 데이터의 양은 늘었지만, 데이터를 비즈니스에 활용하는 기업은 줄고 있다. 데이터 기반 경영을 포기하는 경우가 생기고 있는 것이다. 이는 데이터의 증요성이 대두됨에 따라 데이터를 수집했지만, 관리 및 정제 등이 원활하지 않아 문제가 되고 있는 것으로 보인다. 현재 트렌드에서는 데이터 웨어하우스의 현대화, 데이터레이크의 현대화, 데이터 스트림 분석 등 3가지가 맞물려 발전해야 한다.
박준규 전무는 선진사례의 공통 분모를 ▲도구 ▲설계 ▲실행 등 3가지 관점에서 설명했다. 먼저 데이터 및 AI 관련 도구 선택의 기준은 명확해지고 있다. 쿠버네티스, 텐서플로우 등 오픈소스를 위주로 인프라, 플랫폼 개발도구 및 환경을 선택하고 있다. 설계의 관점에서는 하이브리드 및 멀티 클라우드 구조로 AI 및 빅데이터 관련 인프라와 플랫폼이 설계되고 있다. 설계 방향은 통합과 자동화가 중요 목표가 되고 있다.
마지막으로 실행의 관점에서는 작게 시작해 크게 적용하는 방식이 선호되고 있다고 짚었다. 기존 서비스나 시스템의 개선 가능한 부분을 찾아 신속하게 프로젝트를 추진하고 성과 분석을 토대로 새로운 적용 대상을 탐색하고 있다는 것이다. 박준규 전무는 특정 기술에 대한 내재화보다는 데이터 주도, AI 우선 조직으로 인식과 행동 방식을 바꾸는 것이 더욱 중요하다고 말했다.
이어 박준규 전무는 기아자동차 ‘오너스 매뉴얼’ 사례를 소개했다. 기아자동차는 차량 소유자를 대상으로 앱 기반 매뉴얼을 제공하기 위해 시스템을 구축했다. 인공지능 및 구글클라우드 머신러닝 기반의 심볼 스캐너를 적용해 차량 내 심볼을 인식, 동영상 등으로 콘텐츠를 제공한다.
기아자동차는 글로벌 서비스 확산 전략으로 208개 국가, 39개 언어로 사용할 수 있도록 글로벌 CMS 및 안드로이드·iOS 앱을 구현했다. 또한 쉬운 매뉴얼 이용을 위해 심볼 스캐너를 적용했다. 차량의 특정 영역을 이미지 인식하면, 심볼을 인식해 그 부분에 맞는 매뉴얼을 제공하는 방식이다. 기아자동차는 심볼 스캐너 구현을 위해 구글 인공지능 플랫폼과 하이퍼인퍼런스(Hyper Inference)를 결합했다.
박준규 전무는 사례 소개에 이어 AI 성숙도를 높이기 위해 고려해야 할 사항에 대해 소개했다. 박 전무는 “데이터 및 AI 역량을 강화하기 위해서는 사람, 기술, 데이터, 프로세스 모두를 살펴야 한다. 먼저 기술에 대한 접근은 학습과 훈련을 통해서 해야 한다. 사람에 대한 접근은 데이터 과학자와 AI 개발자 중 누구에게 힘을 실어줄지, 관계자들 간의 협업은 어떻게 지원할지를 살펴야 한다”고 강조했다. 이어 “데이터는 보안 및 규제에 대한 통제력 확보를 전제로, 접근성, 확정성, 자동화 등을 고려해야 한다. 프로세스는 매뉴얼 기반 작업과 체계화되지 않은 데이터 MLOps 파이프라인을 정리해 자동화를 기반으로 효율적으로 실행되도록 해야 한다”고 덧붙였다.
마지막으로 박준규 전무는 “데이터 및 AI 프로젝트를 실행할 때는 애자일 방법론을 최우선 목표로 설정해야 한다. 기술과 도구가 아니라 데이터와 AI를 능숙하게 제품, 서비스, 업무에 적용해 질을 높이는 데 집중해야 한다. 또한 당장 실행 가능한 목표를 설정해 데이터 & AI 프로젝트를 추진해야 한다. 데이터와 AI 선도 기업의 사례를 살펴보면 오랜 준비와 철저한 준비보다 가치 있는 한 번의 실행이 더욱 중요하다”고 강조했다.

주제별 심화 내용과 실제 산업 활용 사례 공유
점심시간 이후 진행된 오후 행사는 주제별로 두 개 트랙으로 나뉘어 진행됐다.
트랙1에서는 ‘데이터 준비: 수집, 저장, 통합’을 주제로 ▲장현 나무기술 이사의 “디지털 트랜스포메이션을 위한 클라우드 전략” ▲하상윤 티맥스비아이 실장의 “셀프서비스 BI를 위한 빅데이터 분석 자동화와 데이터 활용” ▲김기훈 사이람 대표의 “코로나19 접촉 추적 네트워크 분석 시각화 솔루션” ▲조외현 데이타벅스 대표컨설턴트의 “마이데이터 인프라 구축을 위한 CDC 및 GDPR 활용전략” 등의 세션이 마련됐다.
또한 트랙2에서는 ‘데이터 활용: AI & 빅데이터, 보안’을 주제로 ▲이동혁 시큐레이어 팀장의 “인공지능 기반 능동형 보안관제체계(SIEM & SOAR & AI)” ▲박수성 SSG.COM 파트너의 “Spark+Cassandra 기반 Big Data를 활용한 추천시스템 서빙 파이프라인 최적화” ▲안현주 데이터스트림즈 본부장의 “차세대 데이터 플랫폼 전략 ‘Data Fabric’” ▲윤용관 다크트레이스코리아 영업총괄대표의 “베이지언 순환 확률 모형을 활용한 비지도 학습 머신러닝 기반의 사이버 면역 시스템” 등의 세션이 이어졌다.

디지털 트랜스포메이션을 위한 클라우드 전략
트랙1의 첫 번째 세션은 장현 나무기술 이사가 맡았다. 장현 이사는 ‘디지털 트랜스포메이션을 위한 클라우드 전략’이라는 주제로, 클라우드 네이티브 전략의 핵심 기술과 이를 효과적으로 지원·관리하기 위한 올인원 패키지 ‘칵테일 클라우드(Conktail Cloud)’를 소개했다.

클라우드 네이티브를 효과적으로 구현하기 위해서는 ▲프로세스 단위로 독립된 운영환경을 제공하는 운영체제 가상화 기술 ‘컨테이너(Container)’ ▲수백 개의 컨테이너를 효과적으로 관리하기 위한 운영 자동화 기술 ‘오케스트레이션(Orchestration)’ ▲서비스 간의 느슨한 결합(loosely coupled)을 실현하는 ‘MSA(Micro Service Architecture)’ 등이 갖춰져야 한다. 성공적으로 구현된 클라우드 네이티브 환경은 자원을 효율적으로 활용해 비용을 절감하면서 업무 능률을 향상시킬 수 있으며, 하드웨어에 대한 종속이 없어 이식성 측면에서 큰 장점을 갖게 된다.
특히 컨테이너는 클라우드 네이티브의 핵심 기술로, 개별 서비스와 프로세스들이 운영체제 레벨부터 독립된 실행 환경을 갖출 수 있는 환경을 제공한다. 실행체 안에 애플리케이션까지 패키징해 배포할 수 있다. 특히 서버 가상화 기술과 달리 프로세스 기반 가상화 기술이기에 하이퍼바이저가 필요하지 않고, 별도의 게스트OS가 없어도 되기 때문에 훨씬 가볍고 빠른 인프라를 갖출 수 있다.
지난 2019년 CNCF(Cloud Native Computing Foundation)의 조사 결과에 따르면 이미 전 세계 기업의 84%는 기업 운영에 컨테이너 기술을 활용하고 있는 것으로 나타났다. 또한 운영하고 있는 컨테이너의 수는 50~259개 사이라고 답한 비율이 전체의 25%로 집계돼 가장 많은 비율을 차지했다. 한편으로는 1,000~4,999개라는 답변이 15%, 5,000개 이상이라는 답변이 19%를 차지해 실제 기업들이 컨테이너 기술을 적극적으로 활용하고 있는 모습을 확인할 수 있었다.
수천 개 이상의 컨테이너들을 효과적으로 관리하기 위해서는 컨테이너 오케스트레이션 기술을 활용해야 한다. 이 기술의 대표주자는 구글의 보그(Borg) 프로젝트에서 시작한 쿠버네티스(Kubernetes)로, 현재는 리눅스 재단 산하의 CNCF가 메인 프로젝트로 이끌고 있다. 쿠버네티스는 복수의 클러스터를 묶음 단위로 관리하며 호스트 간에 컨테이너 배치, 오토 스케일링, 수명주기를 관리한다. 실제로 컨테이너 기술을 활용하는 기업 중 컨테이너 오케스트레이션을 위해 쿠버네티스를 사용하는 비율은 전체의 70%에 달한다.
이어서 장현 이사는 클라우드 네이티브 컴퓨팅을 위한 올인원 패키지 ‘칵테일 클라우드’를 소개했다. ‘칵테일 클라우드’는 기업에서 클라우드 네이티브 컴퓨팅을 손쉽게 도입하고 활용할 수 있도록 돕는다. 까다로운 쿠버네티스를 활용하는 대신 손쉬운 GUI 기반의 사용자 환경을 통해 높은 편의성을 지원하며, 단일 제어부에서 멀티 클러스터 통합 관리하거나 단일한 대시보드에서 전체 운영 환경을 모니터링할 수 있어 관리 효율성을 크게 향상시킬 수 있다.
장현 이사는 “처음 클라우드 네이티브 환경을 구성할 때는 소규모 프로젝트에서 작은 클러스터로 출발하게 되겠지만, 경험치가 축적되고 사내 요구치가 높아지면 전체 클러스터의 관리 이슈가 반드시 발생하게 될 것”이라며, “나무기술은 ‘칵테일 클라우드’를 통해 복잡한 클라우드 네이티브 환경을 손쉽게 통합 관리할 수 있도록 지원한다”고 설명했다.
셀프서비스 BI를 위한 빅데이터 분석 자동화와 데이터 활용
두 번째 세션에서는 하상윤 티맥스BI 실장이 ‘셀프서비스 BI를 위한 빅데이터 분석 자동화와 데이터 활용’에 대해 발표했다.

최근 몇 년간 데이터 분석에 대한 수요는 지속적으로 증가해왔지만, 해당 업무를 수행할 수 있는 데이터 전문가의 숫자는 턱없이 부족한 상황이다. 따라서 앞으로는 비전문가도 빅데이터를 손쉽게 분석할 수 있는 엔드 유저 컴퓨팅(End User Computing) 체계가 마련돼야 한다는 설명이다.
하상윤 실장은 기존의 전통적인 빅데이터 플랫폼들이 데이터의 수집과 저장에만 포커스를 맞추고 있다고 설명했다. 하둡 파일 시스템(HDFS)은 원시적인 빅데이터 플랫폼을 만들기 위해 만들어졌고, 정형 데이터와 비정형 데이터를 구분해 모든 데이터를 수집하고 저장하는 데에 성공했다. 하지만 수집과 저장에 집중한 전통적 플랫폼들은 데이터의 유통과 활용이 강조되는 오늘날과는 맞지 않는다. HDFS는 여기저기에 산발적으로 적재돼 있는 데이터들을 분류하고 한 곳에 쌓아놓는 엔지니어링 관점에서 개발된 솔루션이며, 데이터를 분석하고 시각화해 인사이트를 만들고자 하는 현업의 요구와는 동떨어져 있다는 것이다.
또한 다양한 빅데이터 관리/분석 수요를 해결하기 위해 하둡 에코시스템은 지속적으로 확장돼 왔고, 이에 따라 너무 다양하고 복잡한 생태계를 갖추게 돼 접근성이 떨어지는 결과를 낳았다. 직접 하둡을 활용해 빅데이터 플랫폼을 구축하고자 하면 클라우드에 대한 이해도 있어야 하고 오픈소스에 대해서도 잘 알아야 하며, 서로 다른 기술 세트 간의 인터페이스 연계 등 너무 다양한 분야의 지식을 갖추고 있어야 한다. IT 전문가가 부족한 대다수 중소기업·스타트업에서는 사실상 하둡으로 직접 빅데이터 플랫폼을 구성해 운용하는 것은 불가능에 가깝다.
이에 티맥스BI는 비전문가도 손쉽게 빅데이터 플랫폼을 구축하고 머신러닝 기반의 데이터 분석이 가능한 자동화된 머신러닝 플랫폼이 필요하다는 목표를 세웠다. 사용자가 복잡한 로직을 생각하지 않고도 표준화된 SQL 쿼리를 사용해 데이터를 가상화시키고 수집·저장·분석이 가능해야 한다는 것이다. 이를 위해서는 ▲오픈소스 및 서드파티와 원활한 연계가 가능한 오픈 아키텍처로 구성돼야 하고 ▲현업 조직의 요구에 맞춰 복잡한 데이터 라이프 사이클 관리 과정을 통합한 단일 플랫폼이어야 하며 ▲다양한 AI 라이브러리를 내재화해 손쉬운 분석이 가능해야 한다.
‘하이퍼데이터(HyperData)’는 이와 같은 티맥스BI의 개발 이념으로 탄생한 머신러닝 기반의 편리한 빅데이터 분석 플랫폼이다. 원하는 오픈소스나 서드파티 솔루션들을 블록을 조립하는 것처럼 자유롭게 탑재할 수 있으며, 사용자의 업무 패턴이나 데이터의 특성을 고려해 분석 모델을 자동으로 추천함으로써 직관적인 분석이 가능하도록 한다.
하상윤 실장은 “‘하이퍼데이터’는 데이터 분석과 얽힌 복잡한 문제와 상황들을 손쉽게 풀어내기 위해 사용자의 편의성을 최우선으로 고려해 개발된 플랫폼”이라며, “GUI 기반의 분석 프로세스 설계는 물론, 스스로 학습하고 결과를 설명하는 자동화된 머신러닝 분석 플랫폼이기에 IT 비전문가도 손쉽게 데이터를 확보하고 분석을 수행할 수 있다”고 설명했다.
코로나19 접촉 추적 네트워크 분석 시각화 솔루션
휴식시간 이후에는 김기훈 사이람 대표가 세 번째 발표를 위해 연단에 올랐다.

김기훈 대표는 ‘코로나19 접촉 추적 네트워크 분석 시각화 솔루션’이라는 주제로, 자사의 ‘넷마이너(NetMiner)’ 솔루션을 이용해 국내 코로나19 전염 네트워크를 분석한 결과를 단계별로 소개했다. 분석 과정은 크게 ▲확진자 데이터를 수집·정제·분류·모델링하는 전처리 단계 ▲전처리를 거친 데이터에서 유의미한 값을 찾아내는 분석 및 시각화 단계로 구성됐다.
가장 먼저 본격적인 네트워크 분석을 위해 확진자 접촉 데이터를 수집했다. 방역당국에서는 진단검사(test)와 접촉조사(tracing)라는 두 가지 방법을 통해 확진자 접촉 데이터를 구축, 지자체 홈페이지를 통해 공유하고 있다. 이를 웹크롤링 방식으로 수집하고 정지·분류·모델링 과정을 거쳐 코로나19 전염 과정을 확인해볼 수 있는 네트워크 데이터를 마련했다. 데이터 수집 범위는 서울·경기·인천 등 수도권으로 한정했으며, 국내에 첫 확진자가 발생한 1월 10일부터 수도권 사회적 거리두기가 2.5단계로 격상되기 직전인 8월 20일까지, 확진 판정을 받은 7,430명의 데이터를 수집했다.
이 과정에서 각 지자체별로 다르게 정리된 필드값과 필드구성을 통일해주고 메타데이터를 일원화함으로써 이후 데이터 분석 과정이 원활히 이뤄질 수 있도록 했다. 대부분의 필드값이 작성자의 편의에 따라 비정형 텍스트 형태로 기재돼 있었기에 이를 정제해주는 과정이 필요했다. 가령 감염경로에 대한 값이 “2.16 신천지교회(대구) 참석”/“신천지 대구교회 방문” 등으로 기록돼 있다면, 이를 “집단_종교_신천지”라는 정형화된 값으로 변경하는 것이다.
정제된 데이터는 다시 감염경로를 참고해 ‘개인/집단/해외/불명’이라는 네 가지 카테고리로 분류했다. 이후 특정 개인(source)이 다른 개인(target)을 직접 감염시킨 ‘개인’ 카테고리에 속하는 대상자들 간에 관계성을 정리해, 최종적으로 확진자 간의 감염 정보를 담고 있는 링크(link) 테이블과 특기할 만한 환자들의 정보를 담고 있는 노드(Node) 테이블을 새롭게 생성했다.
본격적인 시각화 및 분석에는 사이람의 ‘넷마이너’ 솔루션이 사용됐다. ‘넷마이너’는 사이람에서 약 20년 전에 개발해 꾸준히 성능을 업그레이드해오고 있는 소셜 네트워크 분석 솔루션이다. 자바 기반으로 만들어져 있지만 파이썬 API로 손쉽게 부가 기능을 구현할 수 있으며, 이번 분석에서는 확진자 데이터 수집 및 전처리 기능과 분석·시각화 기능들을 플러그인으로 추가해 활용했다. 김기훈 대표는 수 분에 걸친 영상을 통해 직접 ‘넷마이너’로 데이터를 분석하고 그래프 형태로 시각화하는 과정을 시연함으로써, 수도권 3개 지역의 코로나19 확산 네트워크를 일목요연하게 확인할 수 있도록 했다.
김기훈 대표는 “코로나19 전염 확산 메커니즘을 분석한 결과, 종교시설 등 집단감염은 줄고 있으나 확진자에 의해 재생산되는 n차 감염을 막는 것이 난제로 떠올랐다”며, “n차 감염자를 막기 위해서는 확진자 추적 조사(contact tracing)가 가능한 역학조사관을 늘려야 한다. 추적 과정에서 생겨나는 네트워크를 추가적으로 분석함으로써 코로나19 확산 방지에 필요한 격리조치를 빠르게 수행할 수 있을 것”이라고 설명했다.
마이데이터 인프라 구축을 위한 CDC 및 GDPR 활용 전략
트랙1의 마지막 발표는 조외현 데이타벅스 대표컨설턴트가 ‘마이데이터 인프라 구축을 위한 CDC 및 GDPR 활용 전략’에 대해 발표했다.

조외현 컨설턴트는 “지난 8월 데이터 3법 개정안이 발효되면서, 개정된 신용정보법을 근거로 마이데이터를 활용한 사업 가능성이 부각됐다”며, “또한 유럽의 개인정보보호법인 GDPR로 인해 해당 지역에서 비즈니스를 펼치는 기업들이 고려해야 할 사항이 점점 더 늘어나고 있다”고 지적했다.
데이터 3법 개정안은 개인정보보호법, 신용정보법, 정보통신망법 개정안을 함께 이르는 말이다. 3개 법이 제정된 이후 사회의 변화를 반영함으로써 개인정보의 유출과 오·남용을 막고, 안전하게 가공된 개인정보가 유의미한 데이터로 사용될 수 있도록 기반을 다지기 위해 추진됐다. 특히 ▲모호했던 개인정보의 판단 기준을 명확히 하고 ▲가명정보/익명정보 개념을 도입해 안전한 데이터 사용의 근거를 마련했으며 ▲데이터의 활용과 보안에 있어 개인정보 처리자의 책임을 강화했다. 이외에도 개인정보 보호와 관련된 법률들의 유사하거나 중복된 규정들을 정비해 효율적인 개인정보 보호 프로세스를 만들었다는 평가다.
개인정보 활용의 근거가 마련됐다고 해서 마냥 유리한 부분만 있는 것은 아니다. 데이터 3법 개정안에 힘입어, 고객의 개인정보를 보유하고 있는 기업들은 자사의 개인정보 처리 프로세스를 재차 점검할 필요가 생겼다. 현재 누구의 개인정보를 가지고 있는지, 그 정보는 어떤 경로와 목적으로 획득한 것인지, 어떤 보안 처리를 취해 언제까지 보관해야 하는지 등을 새롭게 전수조사하고 문서화해야 하는 것이다.
또한 운영 측면에서도 IT 조직의 관리 포인트가 더욱 늘어났다. 데이터의 이동·전송 시 이력을 남기고 배포 규칙 준수 여부를 점검해야 하며, 가공·처리 시에는 처리 과정의 적법성 여부를 확인해야 한다. 필요한 경우 특정 개인정보에 대한 조회·변경 여부나 고객 요청에 의한 처리 작업 수행 여부 등을 담은 감사 보고서를 작성하는 등 철저한 관리 지침 준수가 필요하다.
이어서 조외현 컨설턴트는 ‘스트림(Striim)’ 솔루션의 CDC(Change Data Capture) 기능을 활용해 데이터 3법이나 GDPR을 준수할 수 있는 방법을 소개했다. ‘스트림’ 솔루션은 실시간으로 복제 데이터에 대한 실시간 가공 및 강화(Enrichment)를 수행, 민감한 고객정보를 제거하거나 필터링함으로써 보안상 위험할 수 있는 요소를 배제한다. 또한 감사용 보관 시스템(Audit Vault) 생성을 위해 CDC를 적용, 데이터베이스의 변경 내역을 실시간으로 관찰하고 수집하며 데이터의 이동·전송 이력을 추적할 수 있다. 또한 ‘스트림’의 작업 내용은 보고서로 작성돼 대시보드에서 확인 가능하며, 이를 통해 준수 여부 추적 및 보고를 위한 데이터 계보(lineage) 관리 또한 가능하다.
조외현 컨설턴트는 “‘스트림’은 복잡한 코딩이나 인터페이스 개발 없이도 다양한 데이터 소스에서 복수에 타깃에 대한 데이터 전송이 가능한 실시간 데이터 통합 및 스트리밍 분석 플랫폼”이라며, “데이터 3법 개정안이나 GDPR과 같은 복잡한 데이터 추적 관리 요구사항에도 효과적으로 대응할 수 있다”고 설명했다.
AI 기반 능동형 보안관제체계
트랙 2의 첫 번째 발표를 맡은 이동혁 시큐레이어 부장은 ‘인공지능 기반 능동형 보안관제체계(SIEM & SOAR & AI)’를 주제로 연단에 올랐다.

먼저 이동혁 부장은 SIEM(Security Information & Event Management; 통합보안관제)과 SOAR(Security Orchestration, Automation and Response; 보안 오케스트레이션, 자동화와 대응)에 대해 간략히 설명하고 AI 기술을 접목해 어떻게 데이터를 다루고 있는지에 대해 설명했다. 특히 최근 2~3년간 AI 시스템은 포괄적인 데이터 분석을 위해 주목받고 있으며, 다양한 시스템들의 데이터를 통합 자동분석하는 SOAR 시스템도 대두되고 있다고 강조했다.
이동혁 부장은 “SOAR는 AI, 정보공유시스템, TI 플랫폼, 위협 정보, 티케팅 처리, 다양한 보안장비에서 수집되는 이벤트와 그 장비의 API를 각각 연동해서 단편적인 이벤트 처리를 하는 것이 아니라 플레이북 기능에 따라 다양한 이벤트들과 대응방식을 연계해 최종적으로 전체 관점에서 자동 처리하는 방식”이라면서, 글로벌 공격자들이 가장 많이 시도하는 DGA(Domain Generation Algorithm) 공격 등을 탐지하는 모델을 생성하는 과정에서의 데이터 활용 등에 대해 상세히 설명했다.
이어 이동혁 부장은 이러한 내용들을 고려해 시큐레이어가 선보이고 있는 AI 및 SOAR 제품을 소개했다. 시큐레이어의 AI플랫폼인 ‘아이클라우드AI(eyeCloudAI)’는 ▲모델 생성을 위한 워크플로우 기능 ▲모델 생성 기능 ▲인공지능 모델을 위한 확장성 제공 등이 특징이다.
또한 국내는 물론 세계적으로도 발 빠르게 출시한 SOAR 솔루션 ‘아이클라우드SOAR(eyeCloudSOAR)’는 ▲다양한 로그 수집 및 분석 기능 ▲AI기반 분석 ▲MITRE ATT&CK 프레임워크 분석현황 ▲실시간 종합현황 ▲위협이벤트 위험도 현황 ▲자동분석 및 대응 현황 ▲상황 전파 컴포넌트 ▲플레이북 ▲대응 컴포넌트 ▲경보에서 대응까지 자동수행 등을 특징으로 한다.
이동혁 부장은 “시큐레이어는 국내 최대 기관인 국가정보자원관리원의 통합전산센터에 AI, SOAR를 구축했고, 결과적으로 알려진 공격과 이상탐지를 하는데 16개의 모델과 75개의 서비스에 적용해 정탐율 97.9%를 확보했으며 지속적으로 확대해나가고 있다. 또한 제1금융권 은행의 인터넷뱅킹 사용자 로그를 학습해 이상금융거래를 탐지해내기도 했다”고 소개하면서, “TTA BMT에서 우수한 성능을 입증하는 등 기본적인 성능 요건을 충족하고 있으며, IT뿐만 아니라 OT 보안에 적합한 SOAR도 개발돼 있다. OT 부문의 RPA 솔루션과의 연계도 가능하다. 이밖에 데이터를 수집, 확보하고 알고리즘을 적용하고 하이퍼 파라미터를 설정하는 것까지 자동으로 할 수 있도록 하는 기능도 개발돼 있다”고 덧붙였다.
Spark+Cassandra 기반 빅데이터를 활용한 추천시스템 서빙 파이프라인 최적화
트랙2의 두 번째 발표는 SSG.COM의 데이터 엔지니어 박수성 파트너가 ‘Spark+Cassandra 기반 빅데이터를 활용한 추천시스템 서빙 파이프라인 최적화’를 주제로 발표했다.

먼저 박수성 파트너는 e커머스에서의 데이터 활용 사례에 대해 설명했다. 고객들이 웹이나 앱에 접속하면 고객의 행동 즉 방문, 검색, 장바구니, 클릭, 구매, 리뷰 등에 관한 데이터가 생성된다. 유저 에이전트나 IP, 웹/앱 버전, 기기 종류 등의 정보도 파악할 수 있다. 이러한 데이터를 통해 사용자에게 상품을 추천하거나, 수요 및 발주 예측, 트렌드 등에 대한 온라인분석처리(OLAP) 등을 하고 있다. 결과적으로 고객별로 다른 상품을 추천하거나, 현재 보고 있는 상품과 관련한 유사 제품을 추천하는 등의 추천 작업이 자동으로 이뤄진다. 특히 특정 상품과 묶음으로 판매를 유도하고, 쿠폰과 할인까지 제공하는 등의 작업을 자동으로 하고 있는데, 이를 스파크 ML라이브러리의 FP-Growth 코드를 사용해 쉽게 추천 데이터 세트를 만들 수 있다는 설명이다.
박수성 파트너는 “통계학을 전공하지 않은 개발자들도 데이터만 있으면 파라미터만 적당히 조절하는 수준으로도 꾸러미 상품, 연관 상품 등의 알고리즘을 만들어낼 수 있다. 과거에 비해 개발자들도 머신러닝(ML)에 대한 접근이 쉬워지는 추세”라면서, “물론 다양한 프레임워크에서 제공하고 있는 알고리즘에 부족한 부분도 있지만 꾸준히 발전 중이다. 각 프레임워크에서 새로운 것을 빠르게 제공하고 있어 개발자들이 가져다 쓰기만 해도 충분한 퍼포먼스를 낼 수 있다”고 최근 동향을 설명했다.
이어 박수성 파트너는 개발자 입장에서 현재 회사 시스템에서 데이터 파이프라인을 구축하기 위해 고민했던 내용들을 포함, 스파크와 카산드라를 선택하게 된 이유에 대해 언급했다. 이와 더불어 아줄시스템즈의 ‘징(Zing)’을 도입해 향후 늘어날 트래픽에 대응하고자 했던 과정에 대해서도 설명을 더했다. 박수성 파트너는 “아줄의 징GC를 테스트했을 때 패러랠GC나 G1GC에 비해 훨씬 안정적인 사용이 가능했으며, 특히 일정한 GC 타임을 유지하고 STW(Stop The World)를 신경쓰지 않고 안정적인 응답을 기대할 수 있었다. 특히 징은 특별한 튜닝 없이 필요한 메모리만 주면 알아서 잘 돌아가는 것이 가장 마음에 들었다”고 덧붙였다.
마지막으로 박수성 파트너는 “결과적으로 아줄시스템즈의 ‘징’을 도입해 CPU 사용량이 100%에서 20%로 줄어 운영 안정성을 확보했으며, 처리율 증가로 인해 배치 속도가 2시간에서 15분으로 감소했다”고 밝히고, “또한 네트워크와 디스크 I/O만 고려하면서 다중 배치를 수행할 수 있었으며, 징GC 도입 후 안정적인 응답시간 및 메모리 관리가 가능해졌다. 이밖에도 전체 데이터가 아닌 키 캐시만 메모리에 올려놓음으로써 효율적인 운영이 가능해졌고, 실시간 대용량 배치를 분리 운영해 안정성을 확보할 수 있었다”고 덧붙이며 발표를 마무리했다.
차세대 데이터 플랫폼 전략 ‘데이터 패브릭’
트랙2의 세 번째 발표는 오전 두 번째 키노트를 했던 안현주 데이터스트림즈 본부장이 다시 연단에 올라 “차세대 데이터 플랫폼 전략 ‘데이터 패브릭’”을 주제로 진행했다.

안현주 본부장은 가트너의 2020년 데이터 매니지먼트 하이프사이클 자료를 인용, 우선 하둡 기반의 데이터 레이크 관련 시장이 2006년경 등장 이후 현재까지 폭발적인 성장을 보이며 안정기에 접어들었다고 설명했다. 그리고 여기에 데이터 거버넌스 기반의 데이터 통합 플랫폼인 ‘데이터 패브릭(Data Fabric)’이 차세대로서 현재 하이프사이클의 정점에 위치해 있으며, 중요성이 강조되고 있다고 설명했다.
안현주 본부장은 “데이터 레이크에 축적한 데이터들은 용처가 불확실한 데이터 잔해(Data Exhaust, 핵심적이지 않은 빅데이터)일 가능성이 높아, 데이터 거버넌스의 중요성이 재조명되고 있다”면서, “현업에서 데이터가 부족하고, 있는 데이터도 사용할 수 없다는 이야기를 많이 하는데 모두 데이터 거버넌스가 부족하기 때문이다. 이에 최근 기업들은 CDO(최고 데이터 관리자) 등 빅데이터 관점의 데이터 거버넌스를 수립하는 조직 역량을 확충하고 있다. 또한 데이터 저장의 우선순위와 수명주기, 보관 방식, 폐기 등에 대한 기준을 재정의할 필요가 있으며 하둡에서의 관계형 데이터 처리가 복잡하다는 문제도 있다. 이런 문제들은 데이터 레이크 만으로는 해결이 어렵다”고 말했다.
이러한 문제와 관련해 데이터스트림즈가 강조하는 ‘데이터 패브릭’은 데이터 거버넌스를 기반으로 데이터 활용성을 제고하고 비즈니스 가치 창출을 강화하기 위한 ‘데이터 플랫폼의 새로운 디자인 콘셉트이자 아키텍처 전략’이라고 요약 정리됐다. 즉, 빅데이터 시장이 성숙함에 따라 데이터의 품질 관리가 중요 이슈로 부각했고, 일관된 데이터 관리체계 아래에 양질의 데이터를 이기종 데이터 소스에 상관없이 활용할 수 있는 ‘빅데이터 패브릭’이 각광받고 있으며, 여기에는 ▲데이터 거버넌스 ▲데이터 통합 저장소 ▲데이터 가상화 등 3가지가 핵심 요소라는 설명이다.
데이터스트림즈는 ‘이루다(IRUDA)’라는 데이터 거버넌스 솔루션 전반을 갖고 사업을 해왔고, 빅데이터 통합 저장소인 ‘테라원(TeraONE)’과 데이터 가상화 솔루션 ‘테라원 슈퍼쿼리(TeraONE Super Query)’ 등까지 ‘데이터 패브릭’에 필요한 제품 라인업을 갖추고 있으며, ‘테라원 패브릭(TeraONE Fabric)’이라는 전략 솔루션으로 선보이고 있다.
안현주 본부장은 “데이터스트림즈의 빅데이터 플랫폼은 수집 기능의 경우 대부분 자체 제작 소스이며, RDB나 하둡에 동시 적재할 수 있는 역량도 갖추고 있다. 메타데이터 관리, 데이터 품질 관리, 데이터 흐름 관리, 기준정보 관리 등의 솔루션을 엔진레벨에서 보유하고 있고 지금은 사용자들이 빅데이터 시대에 맞게 관련 기능 세트를 찾아 쓰기 쉽도록 AI 기반의 데이터 카탈로그 서비스 연구를 하고 있다”고 덧붙였다.
베이지언 순환 확률 모형을 활용한 비지도 학습 머신러닝 기반의 사이버 면역 시스템
트랙2 마지막 시간에는 윤용관 다크트레이스코리아 영업총괄대표가 ‘베이지언 순환 확률 모형을 활용한 비지도 학습 머신러닝 기반의 사이버 면역 시스템’을 주제로 발표했다.

다크트레이스는 베이지언 함수를 오랫동안 연구해온 캠브릿지대학교의 수학자들이 2013년 7월 설립한 후 만 7년간 비지도학습만을 이용해 보안 이슈를 탐지하고 위협에 대응해왔다. 현재까지 10만개 이상의 위협을 찾아낸 다크트레이스의 AI 분석가는 최근 한글까지 익히고 국내 사용자들이 쉽게 볼 수 있는 리포트를 발행하고 있다.
윤용관 영업총괄대표의 설명에 따르면 다크트레이스는 미러링 받은 데이터를 기반으로 비지도 학습 기반 머신러닝을 하고, AI가 평소와는 다른 이상 행동을 자동으로 찾아낸다. 그리고 이러한 행동들이 보안 측면에서 위협이 되는지를 AI 분석가가 판단하고, 관련 리포트를 사용자의 언어로 제공해준다는 것이다.
윤용관 영업총괄대표는 “100% 비지도학습으로 데이터를 보면서 비정상적인 행동을 찾고, 이를 기반으로 위협을 적발해낼 수 있다는 것이 우리의 이론이고, 이를 실제로 증명해나가고 있다. 국내에서는 약 70여곳의 고객사가 사용 중”이라면서, “기업의 IT자산들이 사용되면서 사람에 의한 것인지, 악성코드에 의한 것인지, 혹은 원격 시스템에 의해 세팅된 것인지, 파이썬 등 여러 코드에 의해 내부적으로 이뤄진 것인지 등을, 기계를 이용해 관찰하지 않으면 기계의 속도를 따라가기 힘들기 때문에 머신러닝을 이용하는 것”이라고 말했다.
즉, 보안 위협은 사후에 보면 원인이 간단하고 흔한 것이었다고 느끼게 되지만, 실시간으로 발생하는 수많은 패킷을 빠르게 검토할 수 없기 때문에 사전 탐지가 어려운 것이고, 이를 다크트레이스의 AI 분석가가 해결해줄 수 있다는 설명이다.
이어 윤 대표는 데이터 흐름과 디바이스 현황 등을 볼 수 있는 실제 솔루션 시연을 선보이고, 한글 리포트 작성 화면도 공개했다. AI분석가가 이론에 맞춰 현재 행동 중 이상행동을 뽑아내고, 데이터 이동에 대한 정보들 중 의미 있는 것들을 추려 리포트를 보여주는 화면까지 볼 수 있었다.
윤용관 영업총괄대표는 발표를 마치면서 “전 세계에서 신증 코로나 바이러스에 가장 잘 대응하고 있다는 대한민국 질병관리청과 같이, 다크트레이스는 베이지언 순환 확률 모형 기반의 비지도학습이라는 매우 독보적인 방법으로 AI가 복잡다단한 현실세계의 상황을 인지하고 분석할 수 있도록 나아가고 있다”고 강조했다.
본지는 지난 11월 26일 ‘2020 데이터 컨퍼런스’를 개최했다. 이날 행사 참가자를 대상으로 ▲추진 중인 IT 프로젝트 ▲데이터 산업 발전을 위한 해결 과제 ▲정부의 지원 정책에 대한 평가 ▲국내 데이터 산업계를 위해 필요한 정책과 지원 체계 ▲국산 SW 사용 의지 등에 대한 설문조사도 함께 진행했다. 총 84명이 응답(복수응답)한 설문조사 내용을 정리했다.
‘빅데이터 분석’ 및 ‘클라우드’ 관심 높아
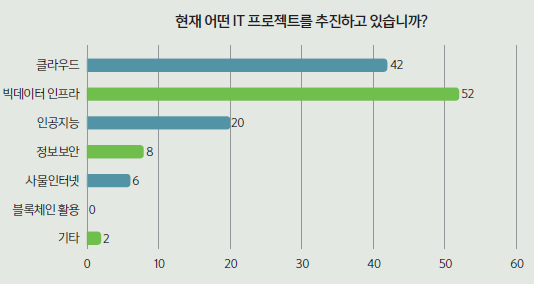
기업 및 기관에서 추진 중인 프로젝트에 대해 52명(61.9%)이 ‘빅데이터 분석’이라고 답했다. 이어 ‘클라우드’가 42명(50.0%)으로 ‘빅데이터 분석’의 뒤를 이었다. 현재 기업 및 기관들의 가장 큰 화두가 ‘빅데이터 분석’과 ‘클라우드’라는 것을 알 수 있는 대목이다. 뒤를 이어 ▲‘인공지능 도입’(16.8%) ▲‘정보보안’(6.72%) ▲‘사물인터넷’(5.04%) 등으로 나타났다. 기타 의견으로 ‘전반적인 디지털 트랜스포메이션 구축’과 ‘로보틱 프로세스 오토메이션(RPA)’ 등도 있었다.
국내 데이터 생태계 활성화위해 ‘전문 인력’ 문제 해결해야
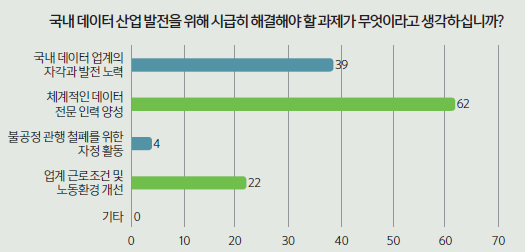
‘국내 데이터 산업의 발전을 위해 산업계에서 시급히 해결해야 할 과제는 무엇인가’라는 질문에 절반이 훨씬 넘는 73.8% 응답자(62명)가 ‘체계적인 데이터 전문 인력 양성’이라고 답했다. 산업계에서 주장하는 ‘인력부족’ 문제가 생각보다 더 심각한 것으로 풀이된다. 이외에도 ‘국내 데이터 업계의 자각과 발전 노력(39명, 46.4%)’과 ‘업계 근로조건 및 노동환경 개선(22명, 26.2%)’이라는 답변이 뒤를 이었다.
정부 데이터 생태계 활성화 및 지원책은 ‘대체로 만족’
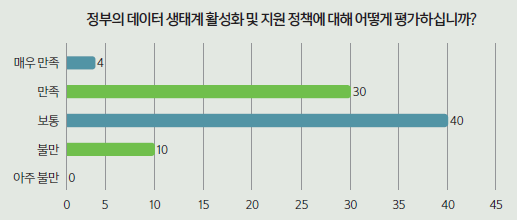
정부의 데이터 생태계 활성화 및 지원 정책에 대해서는 대체로 만족한 것으로 드러났다. 총 84명 가운데 40명(47.6%)이 ‘보통’ 이라고 답했다. 30명(35.7%)은 ‘만족’을, 4명(4.8%)은 ‘매우 만족’ 을 선택했다. 그럼에도 ‘불만’이라고 답한 응답자는 10명(11.9%)이었다. 10명의 응답자들은 향후 정부의 지원책을 계속 주시해야 한다는 뜻으로 풀이된다.
데이터 전문 인력 양성 위한 교육과정 필요
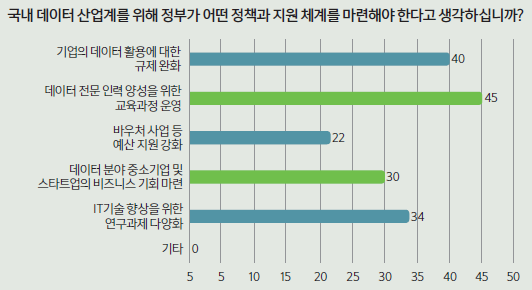
‘국내 데이터 생태계를 활성화시키기 위해서 정부에서는 어떤 정책과 지원체계를 마련해야 한다고 생각하는가’라는 질문에 46명(54.8%)이 ‘데이터 전문 인력 양성을 위한 교육과정 운영’이 필요하다고 답했다. 앞에서 언급됐던 ‘인력 부족’ 문제를 해결하기 위해 교육 과정 마련이 시급한 것으로 보인다. 더불어 ▲‘IT 기술 향상을 위한 연구과제 다양화(34명, 40.5%)’ ▲‘데이터 분야 중소기업 및 스타트업의 비즈니스 기회 마련(30명, 35.7%)’ ▲‘바우처 사업 예산 지원 강화(22명, 26.2%)’ 등의 답변도 많았다.
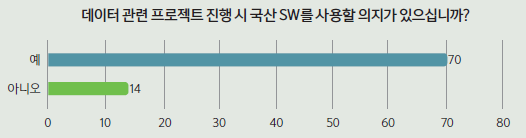
국산 SW 사용 의지 높아
응답자 84명 가운데 70명(83.3%)이 향후 국산 SW를 데이터 관련 프로젝트를 진행할 때 사용할 의지나 계획이 있다고 답했다. 14명(16.7%)은 사용할 계획이나 의지가 없다고 답했다.
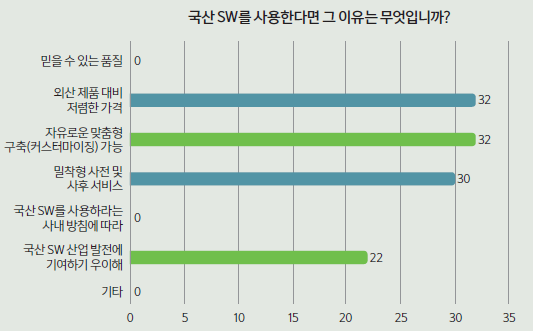
‘자유로운 맞춤형 구축’이 국산 SW 사용 동인
‘자유로운 맞춤형(커스터마이징) 구축’이 국산 SW를 사용하는 주된 이유로 꼽혔다. 총 84명의 응답자 가운데, 32명(38.1%)이 국산 SW 사용 이유로 자유로운 맞춤형 구축(커스터마이징)이 가능하다는 점을 들었다. ‘밀착형 사전·사후 서비스’가 가능하다는 점도 국산 소프트웨어를 선택하는 원인으로 작용했다. 30명(35.7%)은 국산 제품 사용 이유로 원활한 서비스를 들었다. 특히, 15명(17.9%)은 위 2가지를 동시에 선택했다. 외산에 비해 기술지원이 원활하다는 점이 국산 SW의 경쟁력으로 작용하고 있으며, 이를 고객사들이 인정하고 있는 것으로 풀이된다. 이 외에 국내 SW 산업 발전에 기여하기 위해’라는 답을 한 사람도 22명(26.2%)으로 적지 않았다.
국산 SW의 품질 및 안정성에 의문
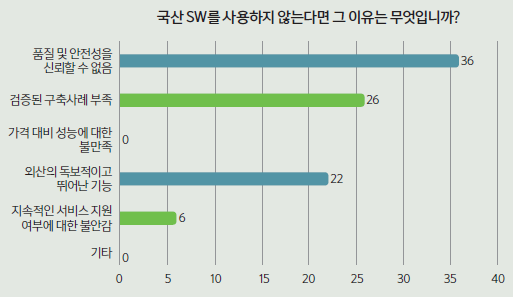
국산 SW를 사용하지 않는 이유에 대한 질문에 84명의 응답자 가운데 36명(42.9%)은 국산 SW의 품질 및 안정성을 신뢰하지 않는다고 답했다. 또 다른 이유로 ‘검증된 구축사례(레퍼런스)가 부족하다(26명, 31.0%)’와 ‘외산의 독보적이고 뛰어난 기능(22명, 26.20%)’을 들었다. 산업계 전반에 퍼진 국산 SW에 대한 인식 개선이 필요하다는 점을 보여줬다. 이 외에도 ‘지속적인 서비스 지원 여부에 대한 불안감’이라고 답한 사람도 6명(7.1%)이 있었다.