



디토닉 기술연구소 ST-AIR 이민우 팀장

[컴퓨터월드] IoT 기술의 발전은 우리에게 방대한 양의 데이터들을 남겼다. 여러 센서를 통해 데이터를 수집했고 여기에는 시간과 위치 정보가 함께 흘러 들어왔다. 공간 정보는 점이나 선, 면과 같은 도형으로 표현되기도 하고 수집 장비에 따라 사진이나 영상 또는 점의 군집으로 나타나기도 한다. 센서가 수집하는 주기도 다양하며, 1초 당 수차례 데이터를 수집하는 것도 있다.
시공간 데이터는 그 양도 어마어마하다. 위성 영상 이미지는 연간 1 PB(페타바이트) 이상, X-Ray영상도 50 PB이상의 데이터를 생산한다. 최근에는 스마트 시티, 스마트 팜, 자율주행, 디지털 트윈 등의 분야가 대두하면서 더 많은 시공간 데이터가 생산되기 시작했고, 시간과 공간의 정보를 담은 이러한 데이터들은 빅데이터의 3V(Volume, Velocity, Variety)를 충족하며 ‘시공간 빅데이터’라고 불리게 되었다. 점차 빅데이터 분석과 가치 창출에 대한 관심이 높아지며 빅데이터의 특징(5V, 7V)들에 대해 정의되고 있지만 데이터를 저장함에 있어 가장 중요한 것은 앞서 언급한 3V이다.
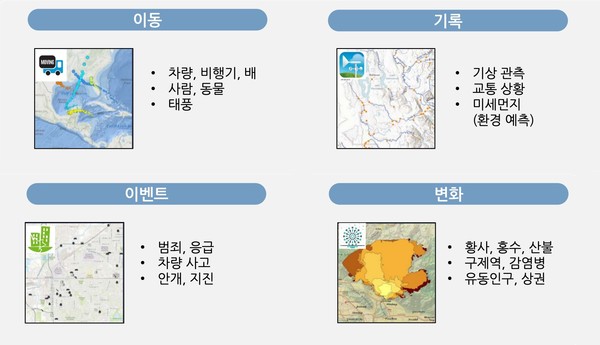
시공간 빅데이터의 저장
시공간 빅데이터를 저장한다는 것은 데이터를 활용하기 위한 준비를 마치는 것과 같다. 빅데이터에서 방대한 양의 데이터를 저장한다는 것은 ‘언제든 활용할 수 있는’ 데이터 자산을 모아두는 것이기 때문이다. 태풍 프란체스 당시 각 매장에 팝타르트와 맥주를 추가로 배치해 큰 이윤을 창출한 월마트 사례가 그러하다. 월마트는 태풍 찰리를 위해서만 데이터를 수집했던 것은 아니었다. 태풍 프란체스 소식을 접하고 태풍 찰리가 지나간 시간적, 공간적 범위 내의 데이터를 조회해 분석했을 뿐이다.
이처럼 빅데이터 플랫폼은 단순히 데이터를 저장하는 것에 그쳐서는 안 된다. 저장소에 저장된 데이터는 마이닝을 통해 원석을 채광하고, 분석을 통해 가치 있는 데이터로 정제되었을 때 진정한 의미를 가진다. 이를 위해서는 데이터를 잘 활용하기 위한 저장 기술이 필요하다.
시공간 빅데이터의 다양성을 이해해야
잘 활용할 수 있는 데이터로 저장하기 위한 첫걸음은 그 데이터를 이해하는 데에서 시작한다. 시공간 빅데이터의 범위는 매우 광범위하다. 단순히 시간과 좌표 정보를 갖는 데이터로 생각할 수 있겠지만, 개념을 조금만 더 확장한다면 시공간 데이터가 갖는 범위는 더욱 다양해진다.
우리가 이해하기 쉬운 가장 대중적인 시공간 데이터로는 차량의 GPS를 들 수 있다. 차량이 지나가는 위치 좌표와 해당 좌표를 지나간 시점으로 표현된 데이터는 차량의 경로를 시간의 흐름에 따라 표현이 가능하며 이와 유사한 경로를 지나는 차량을 분석할 수 있게 한다. 하지만 그 개념을 확장한다면 일상생활에서 우리가 가장 쉽게 접할 수 있는 사진이나 동영상 역시도 시공간 데이터에 포함된다. 사진이나 동영상의 한 프레임은 어느 시점의 특정 장소에 대한 정보를 담기 때문이다.
이처럼 시공간 데이터는 시간의 흐름이나 공간 정보의 유형, 수집 장비에 대한 이동성까지 다양한 조건에 따라 분류할 수 있다. 이런 특성들로 인해 시공간 빅데이터를 저장하기 적합한 저장소에 대한 고민을 하게 된다. 예를 들면 데이터의 크기에 따라 RDBMS 또는 HDFS(Hadoop Distributed File System)와 같은 분산 파일 시스템, HBase와 같은 분산 저장소 등을 선정할 수 있다. S3나 Azure Storage와 같은 퍼블릭 클라우드를 사용하는 것도 한 가지 방법이다. 시간적 특징이 강한 데이터는 Influx DB와 같은 시계열 데이터베이스를 사용할 수 있고, 픽셀 기반 데이터의 경우 SciDB와 같은 저장소를 사용하기도 한다.
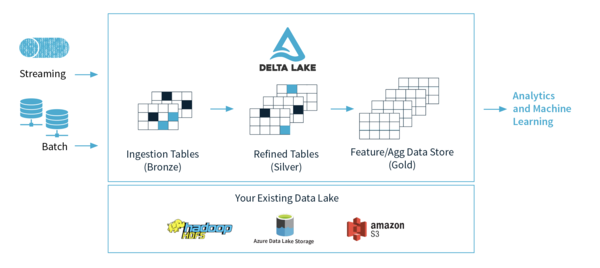
최근에는 하나의 큰 저장소에 정형, 비정형의 구분없이 데이터를 저장하는 데이터 레이크를 활용하기도 한다. 예를 들어 Apache Spark을 기반으로 만들어진 Delta Lake의 경우, HDFS나 LFS(Local File System), S3등에 데이터를 저장하고 Python이나 Scala, R, SQL등의 다양한 언어에서 활용할 수 있도록 지원하고 있다. 하지만 이런 데이터 레이크에서 시공간 데이터를 위한 분석 환경이나 기능 지원 등은 여전히 미진한 상황이다.
가치 창출을 위한 시공간 빅데이터 저장 기술
시공간 빅데이터 기술의 핵심은 데이터를 활용해서 가치를 창출하는 것이다. 이를 위해서는 모든 데이터에 대한 접근이 용이해야 한다. 데이터 레이크에서는 서로 다른 테이블이나 폴더에 존재하는 정형 또는 비정형 데이터들에 단일 인터페이스로 접근할 수 있어야 한다. 또한 모든 데이터에 대해 카탈로그를 저장하여 현재 저장소에 어떤 데이터들이 저장되어 있는지, 어디에 있는지 등의 정보를 확인할 수 있어 데이터 늪(Data Swamp)으로 전락하는 것을 방지할 수 있다. 시공간 빅데이터 저장 기술은 기존의 데이터 레이크 환경에서 레이크 안에 존재하는 다양한 시공간 데이터에 조건을 걸어 조회하거나 시공간 데이터를 가공하여 새로운 가치 있는 데이터로 정제할 수 있도록 연산 기능들을 제공하는 역할을 수행한다.
데이터에 대한 접근성만큼 중요한 것이 성능이다. 아무리 접근성이 좋은 레이크 기술이더라도 데이터를 조회하는 시간이 오래 걸린다면 효율성이 떨어질 것이다. 시공간 빅데이터 역시 빠른 조회나 처리 등을 지원하기 위해 분산 환경 지원이나 인덱싱, 파티션 등의 기술 지원을 통해 시공간 빅데이터 처리를 부스팅하는 노력들이 필요하다.
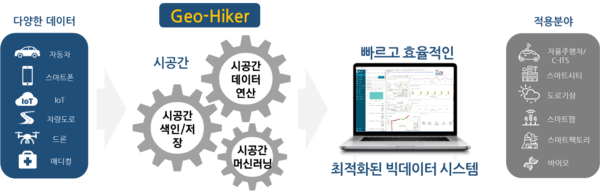
시공간 빅데이터를 부스팅 하자
최근 머신러닝이나 딥러닝과 같은 AI 기술의 인기에 힘입어 시공간 빅데이터 분석에서도 다양한 AI 모델들이 연구되고 있는 상황이다. 이와 더불어 시공간 빅데이터에 대한 다양한 학습 방법론이나 기술 지원 등에도 많은 연구들이 진행되고 있다. 하지만 시공간 빅데이터를 통한 가치 창출을 이루기 위해서 가장 중요한 것은 그에 필요한 데이터를 제대로 저장하는 것이라고 생각한다. 분석이나 데이터 마이닝이 가능한 것은 데이터가 있기 때문이다. 따라서 방대한 데이터의 바다에서 꼭 필요한 데이터에 효율적으로 접근하는 것이 시공간 빅데이터 활용의 시작일 것이다.