



전현상 AWS코리아 솔루션즈 아키텍트(Solutions Architect)

전현상 AWS코리아 솔루션즈 아키텍트는 금융 고객의 클라우드 기술 도입과 문제 해결 관련 업무를 하고 있다. 금융 및 다양한 AI·ML 영역에서 비즈니스 요구사항과 과제를 해결할 수 있는 서비스를 제공하고 있다.
[컴퓨터월드] 음성 텍스트변환(Speech to Text, STT)은 음성 데이터를 자동으로 텍스트로 변환하는 기술이다. STT는 비즈니스의 많은 분야에서 활용되고 있는 기반 기술이다. 예를 들어, 금융업에서 전화 상담 내용을 자동으로 기록하고 분석하여 고객의 요구사항을 파악하고 비즈니스 기회를 찾는데 사용하거나 e커머스에서 고객과의 대화를 녹음하고 이를 분석하여 제품 개발이나 서비스 개선 등에 활용할 수 있다. 이 외에도 의료, 교육 등 분야에서 회의록을 기록한 후 서비스 개선에 사용하는 등 다양한 분야에서 STT를 활용할 수 있다.
STT를 이용한 분석 플랫폼 기능을 활용하기 위해서는 여러 기능이 필요하다. 우선 대량의 음성 데이터를 수집하고 저장하는 기능이 필요하다. 또한 STT 모델 엔진과의 연동이 필요하며, 이를 위해 모델 선택과 연동 방법을 고려해야 한다. 그리고 STT 분석 결과를 텍스트로 변환하고 분석 및 시각화 할 수 있는 NLP 분석 플랫폼 기능도 필요하다.
그리고 무엇보다 STT 분석에 사용되는 음성 데이터는 민감한 정보를 포함할 수 있으므로, 보안 기능이 필수적이다. 대규모 음성 데이터 분석을 위해서 모델 엔진의 서빙에는 스케일링이 필요하며 이를 위해 클라우드 서비스나 분산 처리 기술을 고려할 수 있다. 이러한 STT 분석 플랫폼을 온프레미스에 자체적으로 구축하기 위해서는 고려해야 할 사항이 많다.
아마존웹서비스(Amazon Web Services, 이하 AWS)가 제공하는 아마존 트랜스크라이브(Amazon Transcribe)[2] 서비스를 포함한 다양한 플랫폼 서비스를 활용하면 STT를 활용한 분석 플랫폼을 쉽게 구축 및 확장할 수 있다. AWS의 서비스를 활용하면 하이브리드 클라우드 환경을 구축하고, STT분석에 필요한 리소스의 간단한 연동으로 분석 플랫폼 구축에 대한 어려움을 해소할 수 있다. 그러나 일부 비즈니스의 경우 데이터 보안, 비싼 GPU 서버의 활용, 서빙 API 레이턴시 등의 이유로 STT 엔진 모델을 온프레미스에서 독자적으로 처리해야 하는 경우가 있다. 이러한 경우, 온프레미스에서 머신러닝 STT 모델을 자체 구축하면서 클라우드에서는 해당 모델에 대한 예측과 분석을 수행할 수 있다.
여기에서는 AWS 클라우드를 이용한 STT가 필요한 사례 중에 규제나 특화된 기능을 위해서 자체 STT 엔진 모델을 만들고자 하는 독자들을 위해, 오픈소스 STT 모델을 사용하는 방법에 대해 소개한다.
위스퍼(Whisper)라는 오픈소스 STT 모델은 일반적인 음성 인식 벤치마크에서 우수한 성능을 보여주고 있다. 파인튜닝 없이도 제로샷 전이 설정에서 잘 작동하는 것으로 알려져 있다.[1] Whisper 모델의 학습 데이터 중 한국어는 약 8,000시간으로, 영어를 제외한 다른 언어 데이터 중에서 7번째로 많은 데이터량을 기반으로 학습돼 한국어 인식을 위한 별도의 재학습 없이 사용할 수 있다.
이번 기고에서는 Whisper 모델의 한국어 음성 인식 성능을 평가하기 위해 한국어 음성 데이터를 녹음하고, 녹음한 대본 문장과 Whisper 모델의 인식 문장을 CER(Character Error Rate)를 사용하여 평가한 결과를 소개하고자 한다.
1. 소개
위스퍼(Whisper)는 Dall.E2, 챗GPT(chatGPT)로 잘 알려진 오픈AI(OpenAI)사의 음성인식(Speech to Text) 오픈소스 기계학습 엔진 모델이다.
위스퍼(Whisper)는 2022년 깃허브(github)에 공개된 머신러닝 모델로, 인터넷에서 수집한 많은 양의 음성 대본 데이터를 이용하여 68만 시간에 이르는 다국어 학습 데이터를 활용해 학습한 것으로 알려졌다.[1] 오픈AI(OpenAI)는 위스퍼(Whisper) 모델에 대해 ‘일상 대화’, ‘속삭이는 소리’, ‘음악’, ‘외국어’, ‘감정이나 특정 억양의 대화’ 등과 같은 다양한 음성 샘플에 대한 인식 결과를 확인할 수 있다고 소개하고 있다.
위스퍼(Whisper)는 영어 이외의 다양한 다국어 음성 데이터셋을 포함한 변환 추론을 제공하는데 그 중 한국어 학습 데이터 셋은 약 7,993시간으로 7번째로 많은 음성데이터로 학습되어 있다.[1]
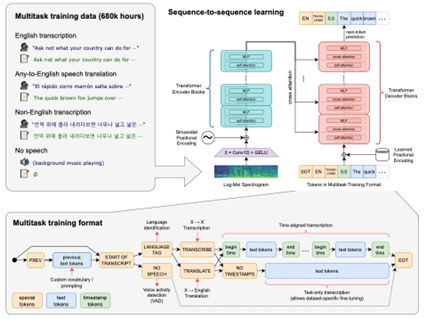
논문[1]에 따르면 위스퍼(Whisper)는 다양한 음성 처리 작업을 수행하는 데, 이를 위해 시퀀스-투-시퀀스(sequence-to-sequence) 트랜스포머(Transformer) 모델이 사용된다. 예를 들어 다국어 음성 인식, 음성 번역, 말하기 언어 식별 및 음성 활동 감지 등 일련의 작업에서 사용되며, 모든 작업은 예측할 시퀀스 토큰의 시퀀스로 나타내어 디코더에 의해 예측된다. 이러한 기술을 통해 전통적인 음성 처리 파이프라인의 다양한 단계를 단일 모델로 대체할 수 있다. 예를 들어 아래 <그림 1>과 같이 멀티테스킹(Multitasking) 학습을 통해 Transcription 과 Translation Task를 동시 수행하여 음성인식과 번역이 바로 제공되며, 출력 인식에서 단어 토큰의 시간 재정렬이 이뤄지는 것이 특징이다.
위스퍼(Whisper)의 한국어 음성인식 모델 성능 분석을 위해 사용된 테스트 데이터 세트는 통계적 성능 분석을 위한 음성 데이터와 실제 생활에서 발생할 수 있는 열악한 환경을 고려한 고객 상담 데이터 두 가지를 포함했다.
첫번째 데이터 셋은 단일 화자를 대상으로 약 8시간 동안 3,922 문장을 녹음한 것이다.
두번째 데이터 셋은 실제 통화 품질 환경을 가정한 이중 화자 기반의 금융 고객상담 상황으로써 3가지 대본을 사용해 음성을 녹음했다.
위스퍼(Whisper) STT 모델의 인식율 평가는 CER (문자오류율) 측정 함수[4]를 사용해 위스퍼(Whisper) 모델의 음성인식 출력 텍스트와 실제 대본 문장 간의 최소 편집 거리를 측정하였다.
2. 본론
2.1 클라우드 STT 분석 플랫폼 구축
테스트를 위해 사용한 STT 분석 플랫폼은 AWS 클라우드를 기반으로 구축되었다. 음성 데이터는 브라우저를 통해 녹음되며 녹음 파일은 사용자의 브라우저에서 음성 녹음 서버로 전송되어 저장된다. 이 때 필요한 것이 DNS다. 사용자가 접속하는 호스팅 서버의 IP 주소를 브라우저가 알아야 파일을 전송할 수 있기 때문이다.
AWS의 DNS 서비스인 아마존 루트53(Amazon Route53)[4]은 도메인 이름을 IP 주소로 변환하고 인터넷에서 호스팅되는 애플리케이션의 네임서버를 관리하는 데 사용된다. 아마존 루트53 DNS 서비스를 사용해 호스팅 서버의 IP 주소를 관리하면, 브라우저에서 음성 녹음 파일을 안전하게 전송할 수 있다.
녹음 웹 서버로 사용한 미믹 레코딩 스튜디오(Mimic Recording Studio)[5]는 음성 녹음 도구로, 아마존 EC2(Amazon Elastic Compute Cloud)에 배포되고 콘덴서 마이크를 통해 자동으로 음성을 녹음한다. 이때 보안 문제 해결을 위해 녹음 환경 접근 설정이 필요한데, AWS 보안 그룹(AWS Security Group)을 사용하면 특정 IP만 녹음 서버에 접근하도록 설정할 수 있다. AWS Security Group[6]은 아마존 EC2 인스턴스의 인바운드 및 아웃바운드 트래픽을 제어하는 가상 방화벽 역할을 담당한다.
음성 녹음 접근에 대한 보안 강화를 위해 AWS 웹 애플리케이션 방화벽(AWS Web Application Firewall, 이하 AWS WAF)[7]이 사용된다. AWS WAF는 클라우드 기반 보안 서비스로, 웹 애플리케이션을 보호하기 위한 다양한 보안 기능을 제공한다. 미리 구성된 보안 규칙 세트를 사용하여 SQL 인젝션, 크로스 사이트 스크립팅, CSRF 및 기타 웹 공격으로부터 웹 애플리케이션을 보호할 수 있다. 또한 사용자 지정 규칙을 설정하여 특정 유형의 공격을 막을 수 있으며, 음성 녹음 데이터를 저장할 때 외부 공격 방지를 위해 2차 보안장치가 사용된다.
음성 녹음 데이터는 실시간으로 아마존 EC2에 저장되며 이 원천 데이터셋은 주기적으로 데이터레이크에 저장되도록 구축해야 한다. 녹음된 오디오 파일과 메타스토어 파일은 녹음 중 주기적으로 아마존 S3[8]에 저장되며, 이후 오픈소스 위스퍼(Whisper)가 배포된 아마존 EC2 모델 서버에서 음성을 텍스트로 변환하게 된다. 본 글에서는 오픈소스 위스퍼(Whisper) 모델의 성능을 확인하기 위해 메타스토어 정보에 STT 변환 텍스트의 분석을 동시에 진행했다. 분석 결과정보는 다시 메타스토어 정보의 CER 열에 입력한 뒤 결과 파일은 다시 S3에 저장했다.
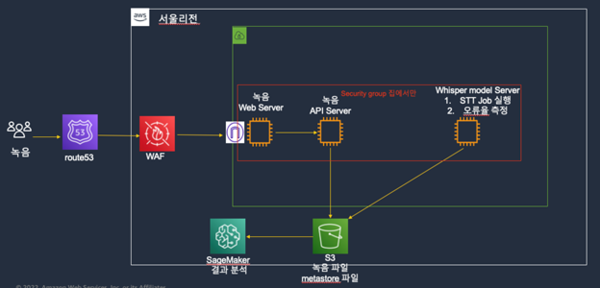
STT 분석 시각화 레이어에서는 아마존 세이지메이커(Amazon SageMaker)[9]를 사용해 STT 성능을 측정하거나 오픈소스 위스퍼 모델을 사용자 음성 데이터셋에 맞게 재학습 할 수 있다.
아마존 세이지메이커는 AWS에서 제공하는 머신러닝 플랫폼으로, 텍스트 분석 및 자연어 처리(NLP) 분야에서 광범위하게 활용되고 있으며 오픈소스 머신러닝 모델 NLP 기술을 쉽게 학습 적용할 수 있는 라이브러리와 툴킷을 제공하고 있다.
또한 오픈소스 위스퍼(Whisper) 모델을 쉽게 로드, 재학습 및 배포할 수 있도록 지원한다. STT 결과 텍스트를 분석하기 위해 아마존 세이지메이커를 사용하는 것은 매우 효과적인 방법 중 하나이며, 텍스트 분석을 통해 다양한 분야에서 인사이트를 얻을 수 있다.
따라서, 클라우드를 사용한 STT 분석 플랫폼 구축은 오픈소스 기반의 음성인식 엔진 모델을 사용할 때 MLOps 관점에서 데이터 관리, 모델 배포, 모델 모니터링, 추론 서비스 endpoint 설정 및 자동화 등 많은 시간이 소요되는 작업을 간편하게 처리할 수 있다는 장점이 있다.
2.2 실험 음성 데이터 셋 생성
음성인식 실험을 위한 데이터셋은 한국어 인식 모델의 통계적 성능 분석을 위한 단일 화자 기반 데이터 셋과 다중 화자 기반 실제 환경을 고려한 페르소나 데이터 셋 두 가지로 나뉜다.
음성 데이터는 자동으로 wav 파일로 저장되며, 해당 파일의 이름, 실제 문장 및 문장의 문자 길이가 메타스토어 로그 파일에 실시간으로 기록된다.
2.2.1 단일 화자 기반 한국어 문장 데이터셋
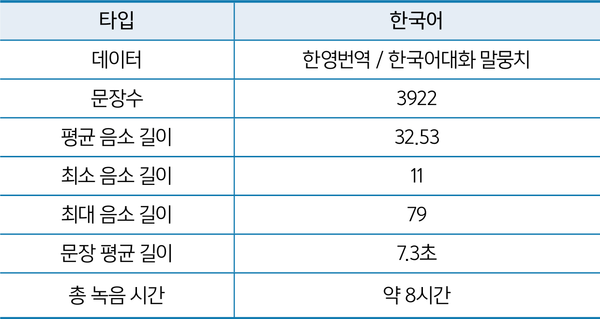
단일 화자 기반 한국어 문장 데이터 셋은 AI-Hub에서 제공하는 ‘한영 번역 말뭉치’[7]와 ‘한국어 대화 말뭉치’[4]를 기반으로 약 8시간 동안 3,922 문장을 녹음했다. 녹음은 한 사람이 울림이 없는 조용한 방에서 콘덴서 마이크를 이용하여 평균 7.3초 길이의 짧은 단일 문장을 읽고 음성 파일로 저장하는 방식이었다. 이 단일 화자 문장 코퍼스는 잘 정제된 구어체 문장으로 구성되었으며 숫자나 이메일과 같은 문장은 포함되지 않았다.
단일 화자 기반 한국어 문장 데이터 셋은 음성 녹음 시 파일 저장과 동시에 메타스토어 정보가 저장된다. 메타스토어 파일은 인덱스, 음성 파일명, 실제 문장(정답 문장), 실제 문장의 단어 길이와 같은 칼럼 정보를 담고 있는 csv 파일로 구성되었다. 아래는 메타스토어 파일 정보의 예시다.
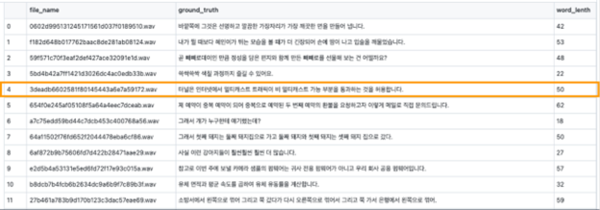
단일 화자 한국어 문장 데이터 셋은 3,922개의 남성 음성 파일로 구성되었으며 총 녹음 시간은 약 8시간이었다. 각 녹음 문장의 평균 음소(단어) 길이는 32.5이고, 음성 데이터의 평균 말하기 속도는 7.3초다.
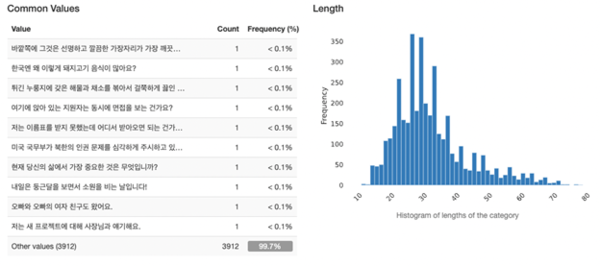
2.2.2 이중화자 기반 한국어 문장 데이터셋
이중 화자 음성 데이터 셋은 보다 현실적인 대화 환경을 가정하고 녹음했다. 이를 위해 울림이 있는 회의실에서 두 명의 사람이 동일한 콘덴서 마이크를 이용하여 전화 통화하는 상황을 시뮬레이션하여 진행되었다. 이중 화자 데이터 셋의 주제는 두 명의 화자가 존재하는 실제 상담 전화 상황을 가정했다.
이 데이터 셋은 금융 업계에서 사용되는 특정 용어와 금액 정보 등이 포함된 세 개의 음성 파일로 구성되었다. 이중 화자 음성 데이터의 인식률은 문장 끝이나 화자 전환이 정확하지 않은 열악한 실제 대화 환경에서 위스퍼(Whisper) 모델의 음성 인식 성능을 분석하고 평가하기 위해 사용되었다.
![[표2] 이중화자 음성 데이터세트 정보](https://cdn.comworld.co.kr/news/photo/202303/50818_42700_2337.png)
첫 번째 데이터 셋은 ‘PB수신고객상담전화’이다. 이 음성 데이터 셋은 여성과 남성이 동시에 대화하는 다양한 음성 주파수를 기반으로 구성된 빠르고 중단 없는 실제 대화 형식으로 구성되어 있다. 이 데이터 셋은 채권명(고유명사), 종목표준코드, 계좌번호, 전화번호 등을 포함하고 있다.
두 번째 페르소나 데이터 셋은 ‘은행의 신생기업 대출안내전화’이다. 이 음성 데이터 셋은 두 남성이 표준어와 방언을 혼용하며, 비교적 평이한 목소리로 대화를 이어가는 점이 특징이다. 이 대화는 숫자가 포함된 이메일과 한국어 주소가 포함 되어있다.
세번째 데이터 셋은 ‘보험 할증료 산정 항의전화’이다. 이 페르소나의 특징은 남성 목소리가 매우 격앙되어 있으며 큰 목소리인 반면, 여성의 목소리는 비교적 작고 차분한 점이 특징이다. 이 대화에는 대화 중 키보드 소음, 차량번호 및 전화번호가 포함되어 있다.
3. 음성 인식 성능 측정 방법
3.1 한국어 CER(음소 문자 오류율) 측정 함수 생성
위스퍼(Whisper) 음성 인식모델은 CER(문자 오류율)을 기반으로 성능을 평가했다. 영어와 같은 라틴어 기반 언어와는 달리, 한국어는 조사의 다양한 변화와 공백의 모호성 때문에 WER(단어 오류율)에 적합하지 않았다. CER은 자동 음성 인식(ASR)과 같은 작업에서 다른 모델을 비교하는데 유용하며, 특히 언어적 다양성으로 인해 WER이 적합하지 않은 한국어 데이터 셋의 평가에 사용된다.
한국어 음성 인식의 성능을 측정하기 위해, 위스퍼 모델에 테스트 음성 데이터 셋을 입력하고 추론한 결과 문장을 이용하여 CER 파이썬 함수를 생성하여 음소 단위로 성능을 측정했다.
이 함수는 인식된 문장과 정답 문장 사이의 문자 수준에서 다른 점을 측정하여 오류율을 계산한다. 예를 들어 아래와 같이, 정답 문장이 ‘아키텍트’고 인식된 문장이 ‘아키텍쳐’인 경우, 두 문장 간에 1개의 문자가 다르므로 CER은 1/4 또는 25%가 된다.

구현한 CER 함수를 사용하여,이중 화자 음성 데이터 셋에서 실제 문장과 위스퍼(Whisper)가 추론한 문장 간의 오류율을 계산했다. 이 데이터셋의 문장이 비교적 길어서 문장 간의 최소 편집 거리는 동적 프로그래밍 방법 중 Levenshtein을 사용하여 계산하였다.[6]
실험에서 문장이 길어질수록 CER의 결과는 종종 0과 1사이의 오류율로 계산되지 않았는데, 특히 CER의 삽입 횟수가 높은 경우 오류 백분율이 잘못 계산되었다. 따라서, 구현한 CER 함수에서는 추론에서 삽입에 따라 초과된 오류 값에 대해 아래 차트와 같이 정규화 오류율을 적용했다.[7]
![[표] 초과된 오류값에 대한 정규화 오류율](https://cdn.comworld.co.kr/news/photo/202303/50818_42702_2358.png)
CER 값이 낮을수록 인식 모델 시스템의 성능이 향상되며, CER 값이 0이면 완벽하다고 할 수 있다. 이 함수는 한국어 문장을 입력으로 받아 각각의 문장에 대한 실제문장과 추론결과 문장을 비교하여 S, D, I, C 값을 계산하고, 이를 이용하여 CER 값을 계산했다.
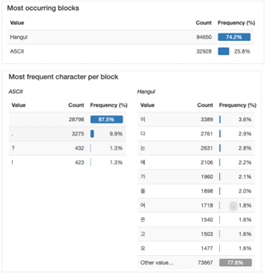
3.2 문장 공백 및 구두점 전처리
이 분석실험에서는 추론 결과 또는 실제 문장에 대해 구두점 전처리 단계가 적용되었다. 한국어 문장 구조에서 단어 간 띄어쓰기의 모호성으로 인해 이 CER 계산에서는 띄어쓰기를 고려하지 않았다. 아래 그림과 같이, 단일 화자 음성 데이터셋의 실제 문장에서는 많은 문장 부호와 공백이 한국어 단어의 성능에 영향을 미칠 수 있다는 것을 발견했다. 따라서 CER 계산 과정에서 구두점과 띄어쓰기를 삭제한 후 CER 함수가 계산되도록 전처리했다.

4. 위스퍼(Whisper) 음성 인식 성능
한국어 음성 인식 성능을 비교하기 위해, 위스퍼의 3가지 오픈 커스텀 모델을 사용하여 단일 화자와 다중 화자 음성 데이터 셋에서 각 추론 모델을 실행했다. 그 다음, 음성 인식 성능 평가에서는 각 추론모델의 출력 스크립트 문장과 실제 문장을 사용하여 CER 점수를 측정했다.
4.1 테스트 대상 위스퍼 음성인식 추론 모델
이번 성능 테스트에서는 공개된 위스퍼(Whisper) 음성 인식 모델 중 3가지를 선택해 비교했다. 인식 성능 비교를 위해 사용한 한국어 음성인식 모델의 정보는 아래와 같다.
![[표] 위스퍼(Whisper) 다국어 음성인식 모델 정보](https://cdn.comworld.co.kr/news/photo/202303/50818_42705_2433.png)
위스퍼(Whisper) 모델 3가지를 사용했으며 각각 GPU 테스트 서버(EC2 P3.8xlarge)[8]에 배포되었다. GPU는 각 위스퍼(Whisper) 추론모델의 인코더와 디코더에 Tesla V100 두 대를 사용했다.
추론 모델은 각 테스트 추론 서버에서 배치작업으로 CER성능을 분석한 결과 정보는 다시 메타스토어 정보의 CER 열에 입력한 뒤 결과 파일은 다시 결과 아마존 S3에 저장된다. 아래 그림은 메타스토어 파일에 기록된 각 문장에 대한 인식 성능이 CER 열에 기록되어 있는 예제다.
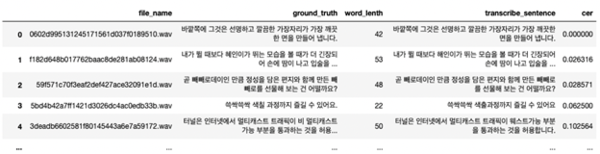
CER은 실제 문장칼럼(ground_truth)과 추론한 문장(transcribe_sentence)칼럼을 사용하여 계산하였다.
4.2 성능 테스트 결과
위스퍼(Whisper) 음성인식 모델의 성능 평가는 사용한 각 추론모델들의 출력 문장과 정답 문장 간의 CER에 초점을 맞추었다. 단일 화자 음성 데이터 셋은 잘 정제된 AI-hub의 약 8시간 분량의 3,922 문장으로 구성되어 있어 위스퍼(Whisper) 모델의 음성 인식율에 대한 분포를 확인할 수 있을 것으로 예상했고, 이중 화자 데이터 셋 3가지는 실제 CS 콜센터의 환경과 다양한 고유명사와 개인식별정보를 포함한 대화를 가정했기 때문에 조금 더 낮지만 실질적인 성능을 확인할 수 있을 것으로 판단했다.
4.2.1 단일 화자 데이터셋 결과
통계적 단일 화자 8시간 음성 데이터 셋을 사용한 각 음성 인식 모델의 평균 CER, 완벽하게 인식된 문장 수(CER이 0인 경우), 그리고 첨도와 표준 편차를 포함하고 있어 각 위스퍼(Whisper) 모델의 추론결과 문장들의 CER 분포를 확인할 수 있었다.
![[표] 단일 화자 음성 데이터 세트 추론결과 (3922문장)](https://cdn.comworld.co.kr/news/photo/202303/50818_42707_251.png)

또한, 모든 모델의 CER 값의 첨도가 높은 것으로 나타났다. STT 모델 인식 결과 CER 분포의 높은 첨도는 모델이 테스트 데이터 셋 전체에서 균일하게 수행되었음을 시사한다.
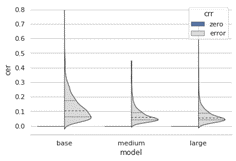
한 가지 흥미로운 사실은 CER 히스토그램 분포 오른쪽에 해당하는 높은 인식 에러의 경우는 medium이 large보다 좀더 안정적인 모습을 보였다는 것이다.
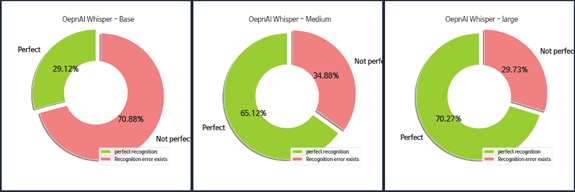
CER가 0%인 인식 결과는 입력 음성을 정확하게 인식한 것으로 간주할 수 있다. 모델이 완벽하게 인식한 음성의 비율은 large 모델의 경우 70%가 넘었다.
4.2.2 이중 화자 금융 콜센터 페르소나 데이터셋 결과
이중 화자 데이터 셋은 개인식별정보나 기업에서 사용하는 상품과 같은 고유명사, 그리고 계좌처럼 숫자가 많은 경우가 포함됐으며 대화 녹음 음성도 다양했다. 또한, 실제 금융 콜센터를 가정하고 녹음했기 때문에 반향과 잡음이 존재하는 음성으로 구성되어 음성 인식 결과 단일 화자 데이터셋에 비해 성능은 다소 떨어졌다. 하지만 medium과 large모델의 인식 성능은 상용 음성인식모델 서비스와 비교할 수 있을 정도의 성능을 보였다.
![[표] 이중 화자 음성 데이터 세트 추론결과 (금융 콜센터 실제 환경 가정)](https://cdn.comworld.co.kr/news/photo/202303/50818_42711_2534.png)
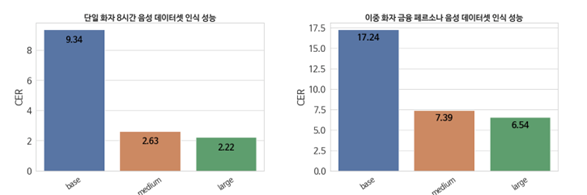
위스퍼(Whisper) large모델의 실제 환경 데이터 셋에서도 비교적 높은 음성인식 성능을 보였다. 다만, 테스트에서 개인식별정보나 특이한 고유명사는 인식율이 떨어지는 것으로 확인되었다. 고유명사의 경우 전이학습을 통해 인식율을 높일 수 있지만 계좌번호나 번호판과 같은 아라비아 숫자로 구성된 개인식별 정보의 경우 인식율을 높이기 위한 후처리가 필요해 보였다.
5. 결론
오픈소스 STT 모델 위스퍼(Whisper)는 별도의 학습 없이 제공하는 사전모델을 사용한 이번 테스트에서 높은 한국어 인식 성능을 보여주는 것을 확인했다. 또한, 위스퍼(Whisper) 음성인식 추론 결과를 보면 아라비아 숫자에 대한 전사처리를 지원하는 것으로 확인됐다. 실제 환경을 고려한 열악한 다중 음성에서도 비교적 높은 수준의 인식율을 보였다.
하지만, 실제 비즈니스 환경에서 STT 모델을 사용할 때는 회사에서 사용하는 고유명사의 인식처리를 위해서 모델의 재학습이 필요하다. ML 엔지니어는 음성 데이터의 수집과 고유명사가 포함된 부분을 전처리한 다음 오픈소스 STT모델을 재학습 시키는 과정을 진행하게 되는데 이때, 추가된 고유명사가 포함된 음성 데이터가 기존 모델의 학습 데이터와 비교해 충분히 다양한 경우 모델의 일반화 성능이 향상될 수 있다.
클라우드 환경에서 아마존 세이지메이커를 활용하여 STT 모델을 재학습시킬 경우 데이터의 가중치를 적절히 조절하여 고유명사나 개인식별정보에 대한 인식 성능을 높이는 작업을 자동화할 수 있다. 또한, 엔드포인트 추론 기능을 활용하면 위스퍼(Whisper)모델의 추론 서빙 기능도 쉽게 구축할 수 있다.
오픈소스 STT 모델인 위스퍼(Whisper)는 서빙 추론모델의 인코더와 디코더에 V100 GPU 두대를 사용했음에도 불구하고 medium과 large 모델의 추론시간은 상당히 느리다는 단점이 확인되었다. 위스퍼 모델을 엔드포인트 서빙 ML API로 사용한다면 클라우드 컴퓨팅 자원에 대한 스케일링 설정 또한 고려할 필요가 있다.
