



테스트웍스 임정현 연구개발 솔루션 본부 팀장

[컴퓨터월드] GIGO(Garbage In, Garbage Out). IT 분야에서 데이터의 중요성을 얘기할 때 자주 사용되는 말이다. 특히나 인공지능(AI) 모델 개발은 귀납적 추론을 통해 수많은 인공 신경의 파라미터 값을 결정짓는데, 잘못된 전제로 이루어진 추론은 잘못된 결과로 이어질 수밖에 없다.
문제가 있는 데이터를 이용해 AI 모델을 훈련할 경우 다음과 같은 문제가 발생할 수 있다.
● 부정확하고 신뢰할 수 없는 추론 결과
● 편향된 예측
● 개인정보 노출 등 보안 문제
● 비효율적인 모델 유지 및 업데이트
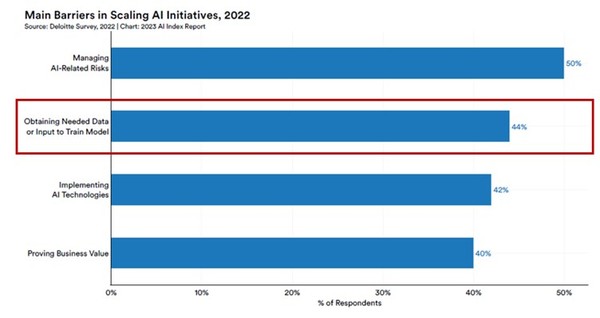
지난해 초 발간된 스탠포드 대학의 ‘AI 인덱스 리포트 2023(Index Report 2023)’ 보고서에 의하면 기업에서 AI를 확장할 때 직면하는 주요 문제 중 하나는 ‘인공지능 모델 훈련에 사용할 적절한 데이터를 획득하는 것이 매우 어렵다’는 점이었다. AI 프로젝트를 추진함에 있어 데이터가 얼마나 중요한지 알 수 있는 내용이다.
구글과 바이두에서 AI 연구를 이끌었으며 스탠퍼드대 컴퓨터공학부 교수였던 앤드류 응 교수가 주창한 ‘데이터-센트릭 AI(Data-centric AI)’ 개념은 AI 모델의 성능을 효율적으로 높이기 위해서는 모델보다는(코드&알고리즘) 데이터를 체계적으로 개선하는 것이 더 효과적이라는 것이다.
시간이 지날수록 개발되는 AI 모델 내부의 인공신경망을 이루고 있는 파라미터의 개수는 기하급수적으로 늘어난다. GPT 3의 경우 약 1,750억 개에 달한다. 시각화 도구 같은 툴을 이용한다고 하더라도 모델 내부를 디버깅하거나 추적하는 등 원인 파악을 하는 것은 거의 불가능에 가깝다.
또한 초기에는 자연어 처리(NLP)에 주로 사용됐던 트랜스포머(Transformer) 구조가 ‘어텐션 이즈 올 유 니드(Attention Is All You Need)’ 논문에 나온 것과 같이 영상, 음성 등 거의 전 분야에 사용되면서 모델 통합이 이뤄지는 상황이다. 최근에 발표되고 있는 초거대언어모델(LLM)들의 경우, 모델의 기본 구조는 거의 동일하고 크기만 키워서 더 많은 데이터를 학습할 수 있도록 만든 구조이기 때문에 모델 자체로 인한 성능 개선은 어느 정도 포화 상태에 이르렀다고 할 수 있다. 대부분의 모델이 오픈소스로 공개된 상황도 모델 자체보다는 데이터가 더 중요하다는 데에도 한 몫하고 있는 셈이다.
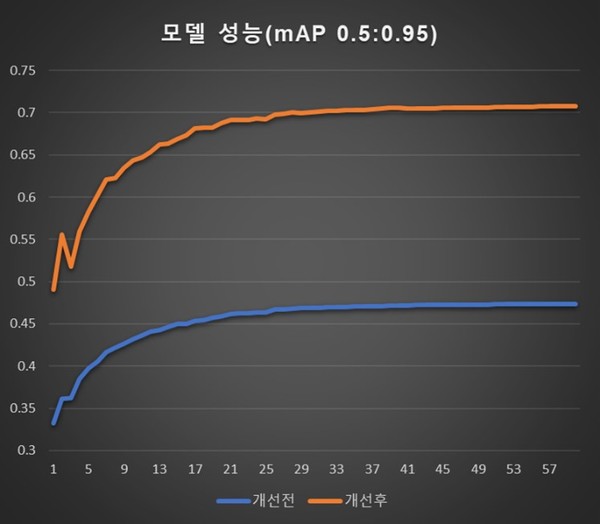
품질 좋은 데이터의 중요성에 대한 예를 들어 보면 필자가 참여한 공공데이터 개선 과제에서 동일한 모델을 사용하고 데이터(도로 장애물 표면 인지 데이터)만을 개선했을 때 아래 도표와 같이 개선한 데이터로 학습한 모델의 성능이 약 48% 향상되는 것을 확인할 수 있었다.
LLM의 경우 기본 모델 훈련 시 SSL(Self-supervised Learning) 기법을 사용하므로 이전에 비해 데이터 품질보다는 양을 늘리는 추세이긴 하지만 챗GPT나 회사 자체적으로 LLM 모델을 실제 도메인에 적용하기 위해 거치는 미세조정 단계에서 입력으로 사용되는 데이터는 품질 좋은 데이터를 이용해야 하기 때문에 데이터의 품질은 여전히 중요하다.
그렇다면 품질 높은 데이터를 구축하기 위해서는 어떻게 해야 할까? 데이터 구축 시 품질을 확보하기 위해 일반적으로 다음과 같은 방안을 고려해 볼 수 있다.
● 데이터 거버넌스 절차 구축
-대부분의 IT 프로젝트와 마찬가지로 품질 좋은 데이터를 구축하기 위해서는 이해관계자들의 참석이 필수적이다. 데이터를 수집하고 가공하는 인력과 해당 데이터를 이용해 모델을 훈련하고, 훈련된 모델을 사용하는 현업 등이 모두 모여 품질 기준을 정하고 표준화된 지침을 마련해야 목표에 부합하는 데이터를 구축할 수 있다.
-목적에 맞는 데이터 수집 및 가공 가이드라인 문서를 작성하고, 이를 이용해 각 작업이 일관성 있고 표준화된 작업이 될 수 있도록 해야 한다.
● 데이터 품질 지표 정의
-데이터 품질을 확인하기 위한 지표는 여러가지가 있고 구체적인 사항은 대상 데이터마다(텍스트, 이미지, 비디오, 오디오) 조금씩 다르지만 이미지 데이터의 경우 다음과 같은 지표를 주로 사용한다.
① 통계적 다양성: 데이터의 라벨이나 속성 정보들이 다양하게 분포되어 있는지 확인한다. 라벨이나 속성의 개수를 확인한 후, 당초 목표한 비율과의 중첩률을 구해 품질의 정도를 확인한다.
② 구문적 정확성: 원천 데이터(이미지, 텍스트, 음성 등)와 이 원천 데이터를 이용해 가공된 데이터 파일의 구조와 값의 유효성 등을 확인한다.
③ 의미적 정확성: 수집/가공 가이드라인 기준을 이용해 라벨이나 속성이 잘못되어 있지 않는지, 누락되거나 과하게 가공된 것은 없는지, 영역이 잘못 가공되어 있지 않는지 등을 체크하고 이를 정량화(정확도, 정밀도, 재현율)해 확인한다.
④ 유효성: 데이터가 실제로 목적하는 모델의 훈련에 적합한지를 확인하기 위한 지표이며, 대상 모델에 해당 데이터를 입력해 훈련한 후 그 모델의 성능을 확인하는 방법으로 데이터의 품질을 확인한다.
● 데이터 정리 및 검증
-벡터(Vector) DB 및 군집, 시각화 도구를 이용한 데이터 큐레이션(Data Curation) 시스템을 구축하면 이상치 데이터나 중복 데이터 등을 손쉽게 선별하고 정리할 수 있다.
-도메인에 상관없이 적용할 수 있는 공개된 거대 모델을 이용하거나 자체적으로 만든 모델을 이용해 ML옵스(Ops) 시스템을 구축하고, 이를 이용해 자동화된 검증 프로세스를 갖춘다면 표준화되고, 효율적인 품질 확인 절차를 구축할 수 있다.
● 데이터 품질 모니터링
-정의된 지표를 정기적으로 측정하고 모니터링할 수 있는 대시보드 형태의 관리 시스템을 구축함으로써 데이터의 품질을 지속적으로 유지할 수 있다.
● 시프트 레프트(Shift Left) 접근 방법
-일반적으로 AI 모델 개발 단계(배포 단계 이후 제외)는 데이터 수집, 데이터 가공, 데이터 검증, 모델 훈련의 단계를 반복하는 절차로 진행된다. 최근 모델의 크기가 커지면서 훈련하는 데 많은 리소스가 소모되는 상황에서 수집부터 잘못된 데이터는 이후 가공, 검증 단계에서 아무리 잘 진행된다고 하더라도 낮은 품질로 남을 수밖에 없다. 이 데이터를 이용해 훈련하면 리소스(비용 및 기간)만 소모하고 성능 낮은 모델을 얻을 수밖에 없다.
-가능하면 앞 단계에서부터 철저하게 품질을 확보해 나가면서 이후 단계로 나가야 비용과 기간을 효율적으로 사용하면서 좋은 모델을 개발할 수 있다.
“AI가 사람을 대체할 수는 없지만, AI를 활용하는 기업이 그렇지 않은 기업을 대체할 것이다.” 필자가 최근에 읽었던 오렐리 미디어(O'Reilly Media)의 콘텐츠 전략 담당 부사장인 마이크 루카이즈(Mike Loukides)의 기고 글의 마지막 부분에 있는 내용이다. AI 개발은 품질 좋은 데이터를 준비하는 것으로 시작할 수 있고, 데이터만 준비되면 프로젝트의 절반 이상은 진행된 것이나 다름없다. AI 시대를 맞은 지금 이제부터라도 회사 내에 있는 데이터를 정리하고 목적에 맞도록 가공해서 AI 적용을 준비해야 다른 회사에 뒤처지지 않고 살아남을 수 있을 것이다.