



아마존웹서비스(AWS) 강병억 솔루션즈 아키텍트

[컴퓨터월드] 인공지능(AI)은 급격한 발전을 거듭하며 우리의 삶에 많은 변화를 가져오고 있다. 특히 최근 딥러닝 기술의 비약적 성장으로 자연어 처리, 컴퓨터 비전, 음성 인식 등 다양한 분야에서 혁신적인 성과가 나타나고 있다. 이러한 AI 기술 발전의 중심에는 ‘벡터 데이터베이스’라는 핵심 인프라가 자리잡고 있다.
벡터 데이터베이스는 비정형 데이터를 고차원의 밀집 벡터로 표현하고, 이를 효율적으로 저장하고 검색할 수 있게 해준다. 텍스트나 이미지, 음성 등의 데이터를 의미론적으로 유사한 벡터 표현으로 변환해 벡터 공간상에서 가까운 위치에 배치하는 것이다. 이를 통해 의미 기반의 검색과 분석이 가능해진다.
특히 최근 주목받고 있는 ‘생성형 AI’ 분야에서 벡터 데이터베이스는 필수 불가결한 역할을 한다. 대규모 언어모델(LLM)을 활용하는 생성형 AI 시스템에서는 RAG(Retrieval Augmented Generation) 아키텍처를 통해 관련 컨텍스트를 검색하고 답변을 생성하는데, 이 과정에서 벡터 데이터베이스가 중추적인 역할을 수행하게 된다.
이처럼 벡터 데이터베이스 기술은 AI 혁신의 근간이 되고 있다. 본 기고에서는 벡터 데이터베이스의 원리와 구현 방식, 실제 활용 아키텍처들을 살펴보고, 이 분야의 최신 기술 동향과 전망에 대해서도 다뤄 보도록 한다.
벡터 데이터베이스란?
전통적인 데이터베이스는 일반적으로 테이블 형태의 구조화된 데이터를 저장하고 관리한다. 이 데이터는 행과 열로 구성돼 있으며, 각 행은 특정 엔티티(예: 고객, 주문 등)를 나타내고 열은 해당 엔티티의 속성(이름, 주소, 금액 등)을 나타낸다. 이러한 관계형 데이터베이스는 데이터 무결성과 일관성을 유지하는 데 적합하다.
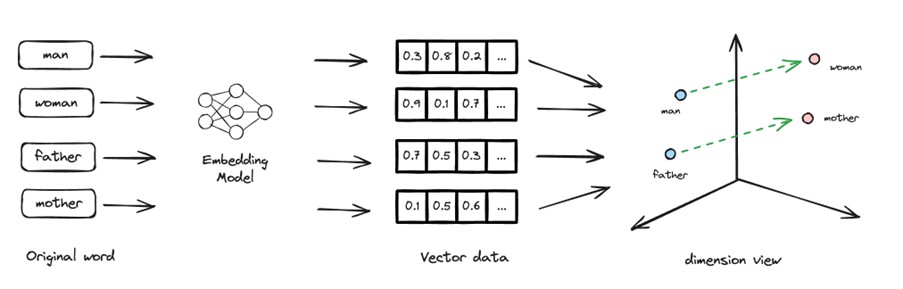
그러나 텍스트, 이미지, 오디오와 같은 비정형 데이터를 다루는 경우, 벡터 데이터베이스가 더 효과적이다. 벡터 데이터베이스에서는 텍스트를 고차원 벡터로 임베딩해 저장한다. 이를 위해 자연어 처리 기술을 활용한 임베딩 모델이 활용된다. 이러한 모델은 단어나 문장의 의미를 벡터 표현으로 변환해 벡터 공간상에 배치한다. 의미가 유사한 텍스트는 가까운 위치에, 상이한 텍스트는 먼 위치에 위치하게 된다. 예를 들면, 아래 그림에서와 같이 man은 woman이나 mother보다 father에 더 가까운 의미론적인 유사성을 가지고 있다. 이 의미론적 유사성은 차원 벡터 공간에서 벡터 거리가 가까운지를 계산해 판단한다.
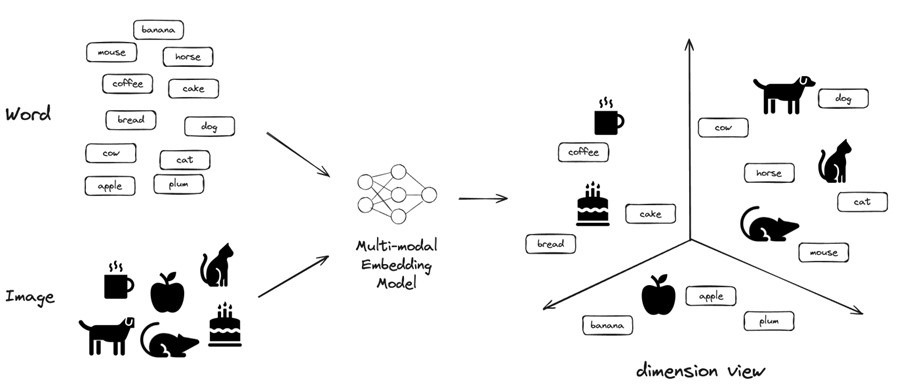
벡터 데이터베이스의 중요한 특징 중 하나는 멀티모달(multi-modal) 기능이다. 이를 통해 텍스트, 이미지, 오디오 등 다양한 유형의 데이터를 동일한 벡터 공간에 표현할 수 있다. 예를 들어, 이미지와 텍스트를 동시에 임베딩해 유사도를 비교할 수 있다. 이는 이미지 검색, 멀티모달 데이터 분석 등 다양한 응용 분야에 활용될 수 있다.
요약하면 전통적 데이터베이스는 구조화된 데이터를 효율적으로 관리하는 반면, 벡터 데이터베이스는 비정형 데이터를 벡터 표현으로 변환해 의미 있는 패턴과 관계를 탐색할 수 있다. 특히 텍스트 임베딩과 멀티모달 기능은 벡터 데이터베이스의 주요 강점이다.
벡터 데이터베이스의 활용
벡터 데이터베이스의 주요 활용 사례는 다음과 같다.
• 이미지 인식: 이미지 임베딩을 사용한 유사 이미지 검색, 역방향 이미지 검색, 유사 제품 추천, 얼굴 인식 등
• 자연어 처리: 단어, 문장, 문서 임베딩을 활용한 정보 검색, 문서 클러스터링, 텍스트 분류 등
• 추천 시스템: 사용자 행동, 아이템 특징 임베딩을 사용한 개인화 추천, 크로스셀링
• 이상 탐지: 정상 행동 벡터 집합과 비교해 이상치 식별
• 생물정보학: 복잡한 생물정보 데이터를 고차원 벡터로 표현, 패턴/유사성 발견
• 음성 인식: 음성 샘플 벡터와 저장된 음성 프로필 비교
추가로 전자상거래에서 개인화 추천과 크로스셀링, 콘텐츠 필터링, 지리공간 분석, 네트워크 보안을 위한 이상 탐지, 지능형 검색 등에도 벡터 데이터베이스가 활용된다.
생성형 AI 생태계에서의 벡터 데이터베이스 활용
생성형 AI를 사용하는 환경에서는 벡터 데이터베이스가 RAG 아키텍처에서 많이 활용된다. RAG의 아키텍처는 다음과 같은 특성을 갖고 있다.
• RAG는 방대한 양의 프라이빗 데이터 전체에서 검색하고, 최종 사용자가 질의한 내용과 가장 유사한 결과를 검색해 LLM에 컨텍스트로 전달한다.
• 검색된 관련 컨텍스트와 사용자 질의를 입력으로 받은 LLM은 이를 바탕으로 최종 답변을 생성한다. 단순 정보 검색이 아닌 LLM의 언어 이해/생성 능력을 활용해 높은 수준의 답변 생성 가능하다.
• RAG는 단순 QA 외에도 요약, 분석, 태스크 완성 등 다양한 자연어 처리 과제에 응용 가능하다.
벡터 데이터베이스는 RAG 아키텍처에서 중요한 역할을 한다. 이 아키텍처는 3단계로 구성돼 있다.
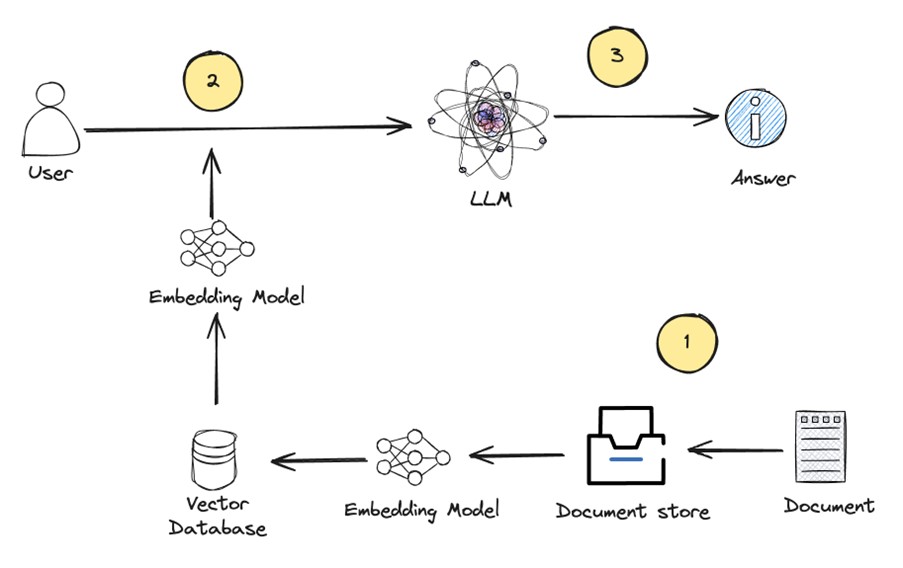
• 1단계 문서 임베딩: 이 단계에서는 질문에 대한 답변으로 사용할 문서들을 LLM을 사용해 벡터로 임베딩한다. 각 문서는 고차원 벡터로 표현되며, 이 벡터들은 벡터 데이터베이스에 저장된다.
• 2단계 질문 임베딩: 사용자로부터 질문을 입력받으면, 동일한 LLM 모델을 사용해 질문 텍스트를 벡터로 임베딩한다. 이 질문 벡터는 1단계에서 저장된 문서 벡터들과 비교된다.
• 3단계 컨텍스트 검색 및 답변 생성: 벡터 데이터베이스에서는 질문 벡터와 가장 가까운(유사한) 문서 벡터들을 찾는다. 이를 위해 코사인 유사도나 유클리디안 거리 등의 유사도 측정 기법이 사용된다. 가장 관련성이 높은 문서들이 선택되면, 이 문서들을 컨텍스트로 활용해 LLM 모델이 최종 답변을 생성한다.
요약하면 RAG 아키텍처에서 벡터 데이터베이스는 문서 임베딩, 질문 임베딩, 그리고 유사도 기반 컨텍스트 검색을 수행하는 핵심 역할을 한다. 이를 통해 대규모 문서 집합에서 사용자 질문에 관련된 컨텍스트를 효율적으로 찾아낼 수 있다.
다양한 유형의 벡터 데이터베이스
벡터 DB는 크게 세 가지 유형으로 나눌 수 있다. 각각의 특징과 장단점을 이해하면 프로젝트 요구사항에 맞는 최적의 솔루션을 선택할 수 있다.
1. 벡터 라이브러리: 벡터 라이브러리는 프로그래밍 언어에 내장해 사용할 수 있는 라이브러리나 오픈소스 라이브러리이다. 이러한 라이브러리는 간단한 벡터 연산을 수행하기에 용이하다. 하지만 대규모 데이터셋을 다루거나 복잡한 쿼리를 실행하기에는 한계가 있다.
2. 벡터 전용 데이터베이스: 벡터 전용 데이터베이스는 고차원 벡터 데이터를 효율적으로 저장하고 검색하도록 설계됐다. 이러한 데이터베이스는 근접 벡터 검색(Nearest Neighbor Search)에 최적화돼 있어 유사도 기반 검색이 가능하다. 또한 대규모 데이터셋을 처리할 수 있는 확장성을 갖추고 있다. 하지만 일반적인 관계형 데이터베이스와 달리 벡터 데이터에 특화되어 있어 다른 유형의 데이터를 저장하기에는 적합하지 않다.
3. 벡터도 지원하는 엔터프라이즈 데이터베이스: 일부 엔터프라이즈급 데이터베이스는 벡터 데이터 타입을 지원한다. 이러한 데이터베이스는 기존 데이터 타입의 데이터와 벡터 데이터를 모두 저장할 수 있어 통합 데이터 관리가 가능하다. 또한 기존 데이터베이스 인프라와 연계할 수 있어 편리하다.
각 유형의 벡터 DB는 고유한 장단점을 갖고 있다. 프로젝트의 규모, 데이터 유형, 성능 요구사항 등을 종합적으로 고려해 가장 적합한 솔루션을 선택하는 것이 중요하다. 또한 하이브리드 아키텍처를 활용해 서로 다른 유형의 벡터 DB를 함께 사용하는 것도 가능하다.
벡터 라이브러리를 사용하는 솔루션들을 살펴보겠다.
• FAISS(Facebook AI Similarity Search): FAISS는 페이스북(Facebook)의 AI 팀에서 개발한 오픈소스 라이브러리로, 밀집 벡터의 효율적인 유사도 검색 및 클러스터링에 특화돼 있다. 대규모 벡터 검색 작업에 매우 적합하며 이미지 및 비디오 검색과 같은 AI 연구 분야에서 광범위하게 사용된다. FAISS는 고차원 데이터 처리에 탁월하지만 SQL이나 JSON과 같은 구조화된 데이터 유형을 직접 지원하지 않는다. 완전한 데이터베이스라기보다는 주로 라이브러리 형태이며, 호스팅 또는 클라우드 서비스를 제공하지 않는다.
• ANNOY(Approximate Nearest Neighbors Oh Yeah): ANNOY 또한 오픈소스 프로젝트로, 고차원 공간에서 메모리 효율적이고 빠른 근사 최근접 이웃 검색을 위해 설계됐다. 스포티파이(Spotify)에서 개발했으며, 대략적인 결과로도 충분한 시나리오에서 일반적으로 사용된다. ANNOY는 라이브러리이며 데이터베이스가 아니고 호스팅 서비스도 제공하지 않는다. 벡터 연산에 초점을 맞추고 있으며, SQL과 같은 구조화된 데이터 유형을 기본적으로 지원하지 않는다.
• SCANN(Scalable Nearest Neighbors): 구글 리서치(Google Research)에서 개발한 SCANN은 대규모 최근접 이웃 검색에 특화된 오픈소스 라이브러리다. 고차원 공간에서 정확도와 효율성의 균형을 제공하며, 정밀한 벡터 검색 기능이 필요한 사용 사례를 위해 설계됐다. FAISS와 ANNOY와 마찬가지로, SCANN은 벡터 연산에 초점을 맞춘 라이브러리이며 구조화된 데이터 유형이나 호스팅 서비스를 기본적으로 지원하지 않는다.
• NMSLIB(Non-Metric Space Library): NMSLIB는 최근접 이웃 검색을 위한 효율적인 인덱싱 및 검색 알고리즘을 제공하는 범용 라이브러리다. 다양한 거리 함수를 지원하며 고차원 및 희소 데이터셋에서 좋은 성능을 보인다. 비트 벡터, 정수 벡터 및 부동 소수점 벡터를 모두 지원한다.
• Vearch(Vector Search): 버치(Vearch)는 벡타라(Vectara)에서 개발한 오픈소스 벡터 데이터베이스다. 대규모 데이터에 대한 빠른 검색과 삽입을 지원하며 백업, 복제, 클러스터링 등의 기능을 제공한다. 파이썬(Python), 자바(Java) 및 고(Go) 클라이언트 라이브러리를 통해 간편하게 통합할 수 있다.
벡터 전용 데이터베이스를 살펴보겠다.
• Pinecone: 파인콘(Pinecone)은 추천 시스템, AI 기반 검색과 같은 애플리케이션에서 확장 가능하고 높은 성능의 유사도 검색을 위해 설계된 벡터 데이터베이스 서비스다. 완전 관리형 클라우드 서비스로, 벡터 검색 시스템의 배포와 확장을 단순화한다. 주로 벡터 데이터에 중점을 두고 있지만 다른 데이터 유형 및 시스템과의 통합을 지원할 수 있다.
• Weaviate: 위비에이트(Weaviate)는 확장 가능한 의미 검색을 위해 설계된 오픈소스 그래프 기반 벡터 데이터베이스다. 비정형 데이터를 포함한 다양한 데이터 유형을 지원하며 기계 학습 모델과 통합해 데이터의 자동 벡터화가 가능하다. 위비에이트는 클라우드 및 자체 호스팅 배포 옵션을 모두 제공하며, 그래프 데이터베이스 기능과 벡터 검색이 필요한 애플리케이션에 적합하다.
• Milvus: 밀버스(Milvus)는 대규모 고차원 벡터 데이터 처리에 최적화된 오픈소스 벡터 데이터베이스다. 다양한 인덱스 유형과 메트릭을 지원해 효율적인 벡터 검색이 가능하며 다양한 데이터 유형과 통합할 수 있다. 밀버스는 온프레미스 또는 클라우드에서 배포할 수 있어 다양한 운영 환경에서 활용 가능하다.
• ChromaDB: 크로마DB(ChromaDB)는 임베딩 벡터 데이터의 효율적인 저장 및 검색을 위한 오픈소스 벡터 데이터베이스다. 텍스트, 이미지, 오디오 등의 데이터를 벡터로 변환해 저장하고, 최근접 이웃 검색 알고리즘을 사용해 빠른 속도로 유사한 벡터를 찾을 수 있다. 크로마DB는 클러스터링을 지원해 확장성을 제공하며, 파이썬과 통합된 단순한 API를 갖추고 있다. 프로토타이핑이나 소규모 애플리케이션에서 높은 처리량과 낮은 대기 시간이 필요한 경우 크로마DB를 효과적으로 활용할 수 있다.
• Qdrant: 쿼드란트(Qdrant)는 고차원 벡터 데이터를 지원하는 오픈소스 벡터 검색 엔진이다. 벡터 데이터의 효율적인 저장 및 검색을 위해 설계됐으며, 필터링과 전체 텍스트 검색 등의 기능을 제공한다. 쿼드란트는 클라우드 또는 온프레미스 환경에서 사용할 수 있어 효율적인 벡터 검색 기능이 필요한 다양한 애플리케이션에 활용 가능하다.
• Vespa: 야후(Yahoo)에서 개발한 오픈소스 빅데이터 서빙 엔진인 베스파(Vespa)는 대규모 데이터 세트의 저장, 검색 및 구성 기능을 제공한다. 정형 및 비정형 데이터를 포함한 다양한 데이터 유형을 지원하며, 실시간 계산 및 데이터 서빙이 필요한 애플리케이션에 적합하다. 베스파는 클라우드 및 자체 호스팅 환경에서 배포할 수 있다.
엔터프라이즈 데이터베이스 환경에서 최적화돼 있는 벡터 데이터베이스에 대해서 알아보겠다.
• OpenSearch/Elasticsearch: 오픈서치(OpenSearch)와 엘라스틱서치(Elasticsearch)는 강력한 전체 텍스트 검색 기능으로 널리 알려진 오픈소스 검색 및 분석 엔진이다. JSON 문서를 비롯한 다양한 데이터 유형을 지원하며 확장 가능한 검색 솔루션을 제공한다. 또한 클라우드 또는 온프레미스에 배포할 수 있으며, 벡터 검색 기능을 추가해 다양한 검색 및 분석 애플리케이션에 적합하게 됐다. AWS와 같은 클라우드 서비스에서는 관리형 서비스로 오픈서치를 지원하고 있다. 아마존 오픈서치 서비스(Amazon OpenSearch Service)는 오픈서치를 관리형 서비스로 제공하고 있고, 서버리스(severless) 형태의 관리형 서비스도 제공하고 있다.
• Mongo(MongoDB): 몽고DB(MongoDB)는 유연성과 사용 편의성으로 잘 알려진 인기 있는 오픈소스 문서 기반 데이터베이스다. 주로 JSON 형식의 문서를 지원하며 다양한 데이터 유형을 처리할 수 있다. 몽고DB는 클라우드 기반 서비스인 몽고DB 아틀라스(MongoDB Atlas)와 온프레미스 배포 옵션을 모두 제공한다. 전통적으로 문서 저장에 중점을 뒀지만, 벡터 데이터 처리를 위한 기능을 점차 추가하고 있다.
• Redis: 레디스(Redis)는 오픈소스 인메모리 데이터 구조 스토어로, 데이터베이스, 캐시, 메시지 브로커로 사용된다. 문자열, 해시, 리스트, 집합 등 다양한 데이터 유형을 지원한다. 레디스는 속도가 빠르기로 유명하며 캐싱, 세션 관리, 실시간 애플리케이션 등에 일반적으로 사용된다. 클라우드 호스팅 및 자체 호스팅 배포 옵션을 모두 제공한다.
• Postgres(PostgreSQL): 포스트그레SQL(PostgreSQL)은 신뢰성, 기능 견고성, 성능으로 잘 알려진 강력한 오픈소스 객체-관계형 데이터베이스 시스템이다. 구조화된 SQL 데이터와 JSON을 포함한 다양한 데이터 유형을 지원한다. 포스트그레SQL은 온프레미스나 클라우드에서 배포할 수 있으며, 소규모 프로젝트부터 대규모 엔터프라이즈 시스템까지 다양한 애플리케이션에서 널리 사용된다. pgvector 확장 기능을 사용하면 포스트그레SQL을 벡터 데이터베이스로 활용할 수 있다. AWS와 같은 클라우드 환경에서도 사용이 가능하다. AWS에서는 아마존 오로라 포스트그레SQL(Amazon Aurora PostgreSQL)을 통해서 pgvector를 지원하고 있다.
• Amazon Kendra: 아마존 켄드라(Amazon Kendra)는 기업 환경에서 지식 검색을 위한 인텔리전트 검색 서비스다. 이 서비스는 내부적으로 벡터 데이터베이스를 활용해 문서나 콘텐츠를 벡터로 표현하고, 자연어 쿼리에 대한 정확한 검색 결과를 제공한다. 기계 학습 모델을 활용해 텍스트 데이터의 의미를 파악하고, 관련성이 높은 결과를 반환한다. 켄드라는 다양한 데이터 소스로부터 정보를 인덱싱하고 통합할 수 있다.
• Knowledge Bases for Amazon Bedrock: 날리지베이스 포 아마존 베드록(Bedrock Knowledge Base)은 대규모 기업 지식베이스 구축 및 관리를 목적으로 특화된 종합 솔루션으로, 단순한 벡터 데이터베이스 이상의 통합적인 기능을 제공한다. 특히 최신 자연어 처리(NLP) 기술과 임베딩 모델을 내장하고 있어 텍스트 데이터를 의미 있는 벡터 표현으로 변환할 수 있고, 강력한 벡터 데이터베이스와 벡터 유사도 검색 기능을 탑재하고 있다. 대규모 데이터에 대해서도 실시간으로 관련성이 높은 결과를 제공할 수 있다. AWS 클라우드 네이티브 서비스라는 장점으로 확장성, 가용성, 보안, 규정 준수 등의 요구사항을 모두 충족한다. 온프레미스 환경에서는 구현하기 어려운 수준의 기능과 성능을 제공한다.
벡터 데이터베이스 구성 시의 고려사항
벡터 데이터베이스 안정적으로 구축하고 운영하려면 다음과 같은 사항들이 고려돼야 한다.
• 데이터 전처리 및 임베딩: 벡터 데이터베이스에 데이터를 효과적으로 저장하고 검색하기 위해서는 데이터 전처리와 임베딩 과정이 중요하다. 텍스트 데이터의 경우 적절한 토크나이저를 선택하고 정제 과정을 거쳐야 한다. 또한 어떤 언어모델을 사용해 임베딩할지, 미세조정(fine-tuning)이 필요한지 등을 결정해야 한다.
• 성능 최적화: 벡터 검색의 성능은 응답 시간, 처리량 등 애플리케이션의 핵심 요구사항과 직결된다. 인덱싱 전략 외에도 벡터 차원 축소, 캐싱, 분산 아키텍처 적용 등 다양한 기법을 통해 성능을 최적화할 수 있다.
• 모니터링 및 운영: 실제 운영 환경에서는 벡터 데이터베이스의 상태를 지속적으로 모니터링하고 관리해야 한다. 데이터 증가, 쿼리 패턴 변화 등에 따라 인덱싱을 재구성하거나 클러스터를 확장해야 할 수 있다. 또한 백업, 장애 대응 등 운영 관리 절차도 마련돼야 한다.
• 보안 및 프라이버시: 벡터 데이터베이스에는 민감한 데이터가 포함될 수 있으므로 보안과 프라이버시 보호 대책도 필수적이다. 데이터 암호화, 접근 제어, 암호화된 벡터 검색 등의 기술을 활용할 수 있다.
• 통합 및 상호운용성: 벡터 데이터베이스를 기존 데이터 인프라와 통합하거나 다른 시스템과 연계해야 하는 경우가 많다. API, 데이터 파이프라인, 데이터 포맷 등의 측면에서 상호운용성을 고려해야 한다.
이러한 요소들을 종합적으로 검토해 프로젝트 요구사항에 가장 적합한 벡터 데이터베이스 아키텍처를 설계하고 구축해야 한다. 운영 단계에서도 지속적인 모니터링과 최적화가 필요할 것이다.
결론
벡터 데이터베이스는 AI 기술의 발전과 함께 그 중요성이 더욱 부각될 것으로 전망된다. 인공지능이 사람의 인지 능력을 모방하고 넘어서려면 데이터의 의미를 정확히 이해하고 처리할 수 있어야 한다. 벡터 데이터베이스는 이러한 의미 기반 데이터 처리를 가능케 하는 핵심 인프라로 자리매김할 것이다.
머신러닝 모델이 고도화되고 멀티모달 AI의 활용이 확대되면서 벡터 데이터베이스 기술도 지속적으로 진화할 것이다. 텍스트, 이미지, 음성, 센서 데이터 등 다양한 유형의 데이터를 벡터 표현으로 통합하고, 이를 기반으로 새로운 지식과 통찰력을 창출하는 것이 가능해질 것이다.
또한 벡터 데이터베이스는 대규모 데이터 처리를 위한 분산 컴퓨팅, 메모리 및 스토리지 최적화 등의 기술과 긴밀히 연계돼 성능과 확장성을 높여갈 것으로 예상된다. 클라우드 네이티브 아키텍처와의 융합을 통해 벡터 데이터베이스는 더욱 손쉬운 배포와 운영이 가능해질 것이다.
AI 기술의 급진전에 따라 벡터 데이터베이스는 혁신적인 애플리케이션과 서비스를 견인하는 필수적인 데이터 인프라로 자리잡게 될 것이다. 다양한 산업 분야에서 새로운 가치 창출과 AI 기반 의사결정의 토대가 될 벡터 데이터베이스 기술에 대한 연구와 투자가 지속될 것으로 기대된다.
참고문헌
1. 벡터 데이터베이스, Vector Database: https://www.pinecone.io/learn/vector-database/
2. 벡터 검색 커뮤니티, Vector Search Community: https://vectorsearch.dev/
3. Qdrant: https://qdrant.tech/
4. Vespa: https://vespa.ai/
5. NMSLIB: https://github.com/nmslib/nmslib
6. 벡터 데이터베이스 가이드, Vector Database Guide: https://www.semiotic.ai/guides/vector-databases/
7. FAISS: https://github.com/facebookresearch/faiss
8. ANNOY: https://github.com/spotify/annoy
9. Pinecone: https://www.pinecone.io/
10. Weaviate: https://www.weaviate.io/
11. Milvus: https://milvus.io/
12. Elasticsearch 벡터 검색: https://www.elastic.co/
13. MongoDB 벡터 데이터: https://www.mongodb.com/
14. Redis 벡터 데이터: https://redis.io/docs/stack/search/reference/vectors/
15. PostgreSQL pgvector: https://github.com/pgvector/pgvector
16. Amazon Kendra: https://aws.amazon.com/kendra/
17. AWS Bedrock: https://aws.amazon.com/bedrock/