



데이터 가공 및 분석 (1)
[컴퓨터월드]

| 1. 데이터 수집 - 크롤링 소개, Scrapy 및 BeautifulSoup 사용방법 2. 데이터 저장 - EFK 스택 사용방법 3. 데이터 가공 및 분석 (1) 4. 데이터 가공 및 분석 (2) 5. 데이터 가공 및 분석 (3) |
데이터 분석의 기본적인 단계는 크게 다음의 4단계로 구분할 수 있다.
1. 데이터 수집 및 저장
2. 분석 알고리즘 선정
3. 분석 알고리즘에 맞춰 데이터 가공
4. 분석 알고리즘에 의한 처리(기계학습 등)
우리는 현재 데이터 수집 및 저장 능력을 갖춘 상태다. 그럼 바로 분석 알고리즘을 선정하는 단계로 가면 될까? 사실은 그렇지 않다. 현실 세계에서 분석 알고리즘의 선정은 대부분 군집화(Clustering), 분류(Classification), 예측(Regression)이라는 범주 중 하나를 선정하게 된다.
각 범주는 우리가 만나게 될 문제의 종류만큼이나 다양한 알고리즘을 포함하고 있고, 우리는 이러한 알고리즘 중 몇 가지를 선택해 다양한 데이터로 실험하게 되며, 이러한 과정을 통해 우리가 원하는 목표에 가장 부합하는 알고리즘과 데이터 형태를 찾을 수 있다.
이때 각 알고리즘은 학습에 요구되는 데이터의 종류나 형태가 다른 경우가 많다. 따라서 다양한 알고리즘을 실험하기 위해서는 데이터를 원하는 형태로 가공할 수 있는 능력이 필수적이라고 할 수 있다.
이번 글에서는 우리가 수집한 데이터를 원하는 형태로 가공하는 방법(특히 벡터와 매트릭스)을 알아보고, Word2Vec 알고리즘을 이용해 영화배우와 영화감독 간의 간단한 의미 분석 도구를 작성해보도록 하겠다.
본 글에서 사용된 코드는 https://github.com/haandol/kobis 에서 확인할 수 있으며, 데이터는 영화진흥위원회에서 제공하는 KOBIS 영화정보를 크롤링해 예제로 사용했다.
Pandas
파이썬(Python)으로 데이터 분석을 할 때 빠지지 않고 등장하는 라이브러리가 바로 Pandas와 Numpy다. Numpy는 과학 분야에서 자주 다루게 되는 다차원배열에 대한 연산을 빠르게(거의 C 코드에서 배열을 다루는 속도로) 처리할 수 있게 하는 라이브러리이며, Pandas는 Numpy를 기반으로 해 더 추상화된 다양한 편의기능들을 제공하는 라이브러리라고 생각하면 된다.
본 글에서는 Pandas에서 제공하고 있는 수많은 기능을 하나하나 언급하기보다는, 실제 데이터를 가공하는 간단한 예제를 기반으로 자주 사용하는 기능들만 소개할까 한다. 백문이 불여일견이라고 했으니 코드를 보면서 설명하겠다.
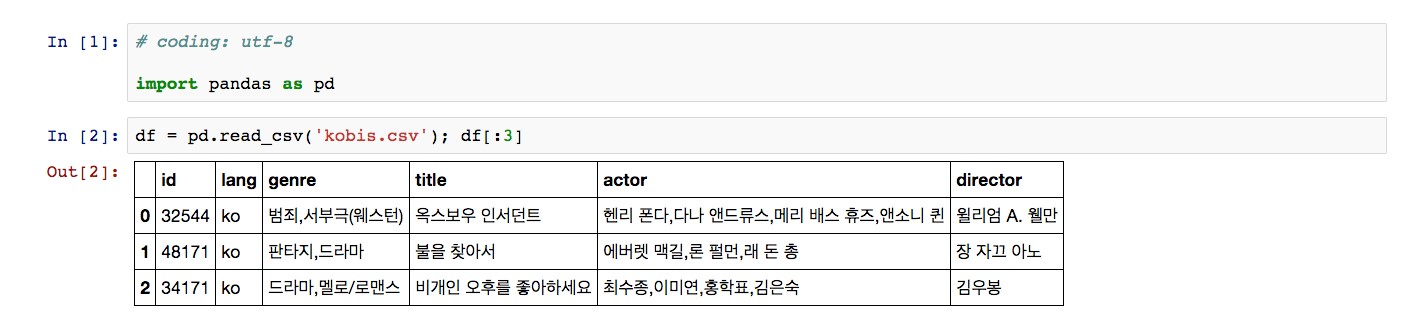
CSV(Comma Separated Values)는 몇 가지 필드를 쉼표(,)로 구분한 텍스트 데이터 및 텍스트 파일로 다양한 곳에서 자주 쓰는 형태다. Pandas에서는 이렇게 자주 사용되는 파일 형태에 대해 손쉽게 Pandas 데이터 객체로 읽어 들일 수 있도록 함수를 제공하고 있으며, 예제에서 사용하는 CSV 외에도 SQL 쿼리 결과(read_sql), 엑셀 파일(read_excel), HTML 파일(read_html) 등이 대표적인 지원 형태다.
이렇게 읽은 데이터는 데이터프레임(DataFrame, 이하 DF)이라는 Pandas데이터형으로 저장이 되는데, DF는 일단 RDBMS에서 사용하는 테이블 구조를 파이선 객체로 옮겨놓은 것이라고 생각하면 된다. DF도 테이블과 마찬가지로 행(row), 과 열(column)로 구성됐으며, 각 행을 가져올 수 있는 주키(Primary Key: PK)가 존재한다. DF에서는 주키를 인덱스(Index)라고 부른다.
열과 행에 접근하는 방법은 아주 쉽다. 열에 접근할 때는 열 이름을 키로 해 파이썬 사전형(dictionary)처럼 사용하면 된다. 행에 접근할 때는 인덱스를 이용해 접근해야 한다. <그림 1>의 데이터를 보면 id 열 왼쪽에 0, 1, 2, 3... 등이 인덱스다. 행에 접근할 때도 인덱스를 이용하는 부분만 다를 뿐 마찬가지로 인덱스 이름을 키로 해 파이썬 사전형처럼 사용하면 된다. 이렇게 행과 열에 접근하는 방법은 <그림 2>와 같다.

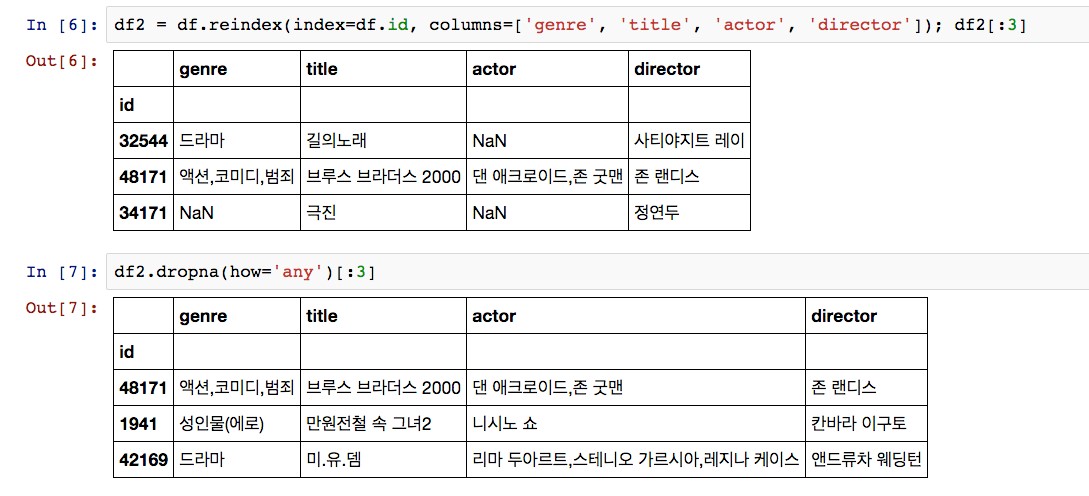
만약 인덱스를 id로 바꾸고 싶다면 어떻게 하면 될까? reindex 명령을 통해 인덱스를 변경할 수 있다. 아래 <그림3>에서 보듯 reindex를 이용할 때 columns 파라미터에 원하는 열의 이름을 배열로 넘겨줌으로써 불필요한 열들은 빼버릴 수도 있다.
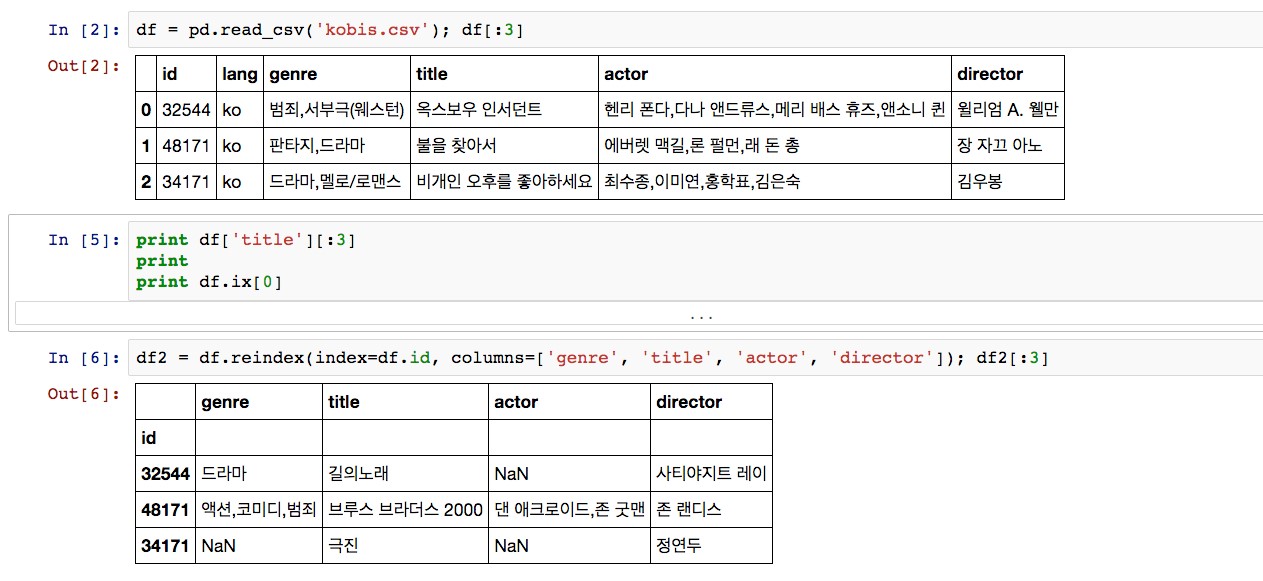
그런데 <그림 3>에서 첫 번째 행의 actor에 보이는 NaN은 값이 존재하지 않는다(NULL)는 의미다. 만약 값이 존재하지 않는 열을 갖고 있는 행을 제거하고 싶다면 어떻게 해야 할까? dropna 명령을 통해 해당 행들을 쉽게 제거할 수 있다.
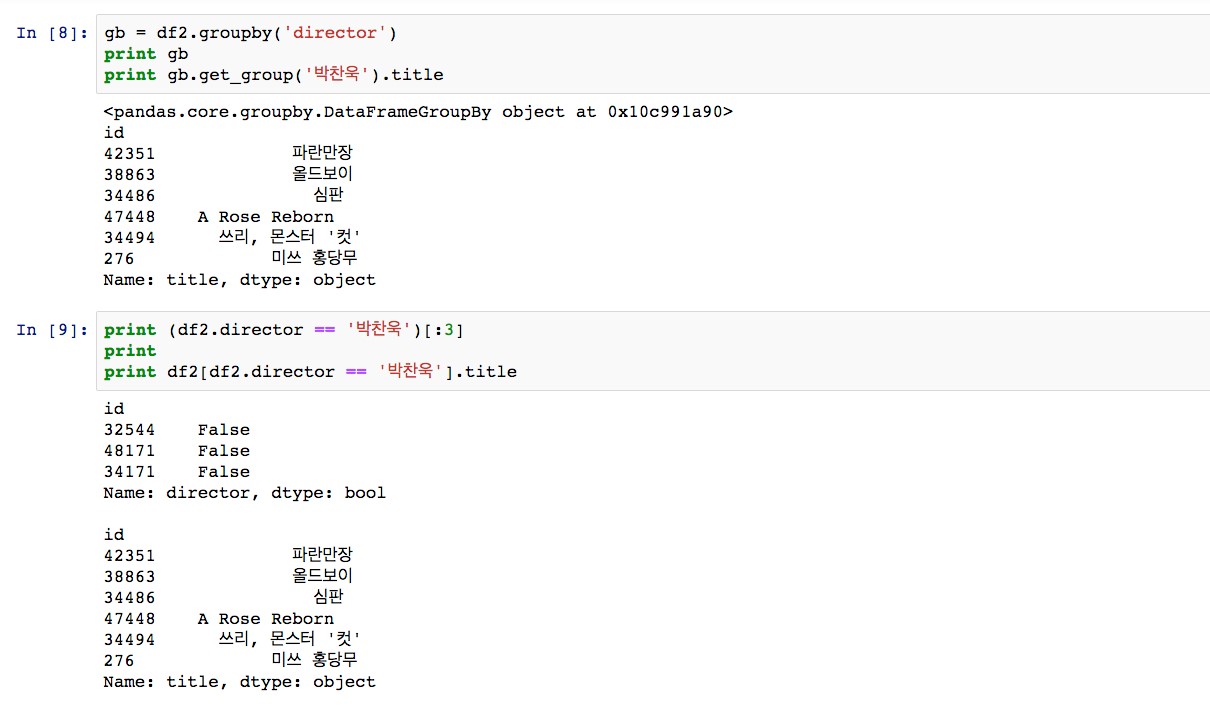
이제 데이터가 기본적인 형태는 갖췄으니 조건에 맞춰 데이터를 뽑아내보자. ‘박찬욱’ 감독이 director인 영화의 actor들은 어떻게 확인할 수 있을까? 다양한 방법으로 가져올 수 있겠지만 가장 간단한 2가지 방법만 알아본다.
먼저 RDBMS에 익숙한 이들은 ‘group by’를 떠올릴 텐데, DF도 해당 명령을 제공하고 있다. 함수 이름도 groupby다. groupby(‘director’)를 통해 director별로 묶어낸 DataFrameGroupBy 객체를 얻을 수 있다. 이 객체는 get_group이라는 함수를 통해 묶인 개별 그룹을 반환한다. <그림 5>와 같이 get_group(‘박찬욱’)으로 박찬욱이 director인 행들을 가져올 수 있다. 다른 방법으로는 df.director의 조건문 기능을 이용하는 방법이 있다.
df.director == ‘박찬욱’ 이라는 명령을 통해 해당 조건에 맞춰 전체 행 크기만큼의 True 또는 False로 채워져 있는 배열(Series)을 반환한다. DF에 해당 배열을 키값으로 넣으면 True 값인 행만 얻을 수 있다.
다음 절에서 다룰 Word2Vec에 학습시키기 위해 데이터 형태를 ‘영화제목 영화감독 배우1 배우2 배우3...’ 형태로 가공해보겠다.

Word2Vec
Word2vec은 이름 그대로 단어(word)를 수십~수백 차원의 벡터(vector)로 변환해 단어의 의미를 추론하는 알고리즘이다. 이 알고리즘은 내부적으로 CBOW(Contiguous Bag Of Words) 와 SGNS(Skip-Gram model with Negative Sampling)이라는 2개의 신경망 모델을 이용해 단어(Vocabulary)를 학습하게 된다.
각 모델은 이름에서 언급된 Bag of Words, Skip-gram, Negative sampling 외에도 워드 임베딩(word embedding), 신경망(Neural net) 등을 따로 언급해야 설명할 수 있으므로, 본 글에서는 내부알고리즘과 구현에 대해서는 다루지 않겠다. 이런 다소 복잡해 보이는 알고리즘을 적용한 결과는 상당히 놀랍다. Word2Vec을 이용하면 ‘프랑스 - 파리 + 서울 = 한국’, ‘왕 - 남자 + 여자 = 여왕’ 같은 신기한 결과를 얻을 수 있다.
이번 절에서는 <그림 6>에서 얻은 결과를 Word2vec에 학습시켜 다양한 결과를 얻으려 한다. 먼저 Word2vec을 이용하기 위해 gensim 서드파티 라이브러리를 PIP를 통해 설치한다. gensim은 자연어를 벡터로 변환하는데 필요한 대부분의 편의기능을 제공하고 있는 라이브러리로, 이후 글에서도 계속 사용할 예정이니 시간 날 때 문서를 읽어보는 것도 좋다.
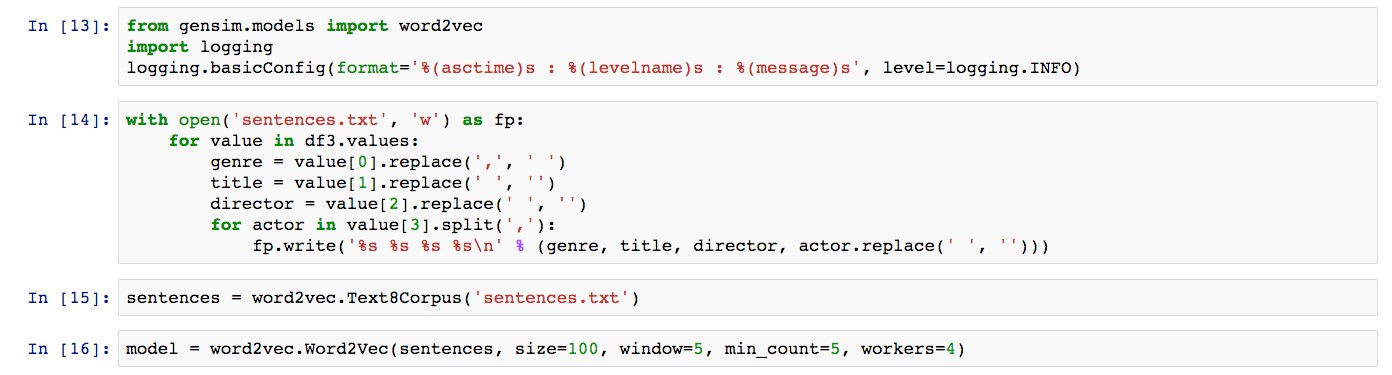
gensim은 Word2vec을 포함하고 있으며, 이를 사용하기 위해서는 단순히 모듈을 임포팅하면 된다. 학습하는 과정도 굉장히 간단한데 <그림 7>과 같이 word2vec.Text8Corpus를 이용해 텍스트 파일에서 문장들을 가져온 뒤 word2vec.Word2vec에 문장들을 전달함으로써 학습시킬 수 있다.
Word2vec은 몇 백만 건 단위로 학습시켜야 제대로 분석할 수 있다고 하지만, 본 글에서는 KOBIS에서 제공하는 영화정보 중 약 3만 건의 영화에 대해 학습시켜봤다. 백만 개 남짓의 단어이기 때문에 몇 분 안에 학습이 됐다. 논문에 따르면 8억 개 단어를 학습하는데 약 하루 정도 걸린다고 한다.
학습이 끝났으니 쿼리를 넣어 결과를 확인해보자. <그림 8>에서 2가지 쿼리를 예로 넣어봤다.
1. ‘올드보이’ + ‘박찬욱’ - ‘스릴러’ = ?
2. ‘크리스토퍼놀란’ + ‘크리스찬베일’ - ‘히스레저’ = ?
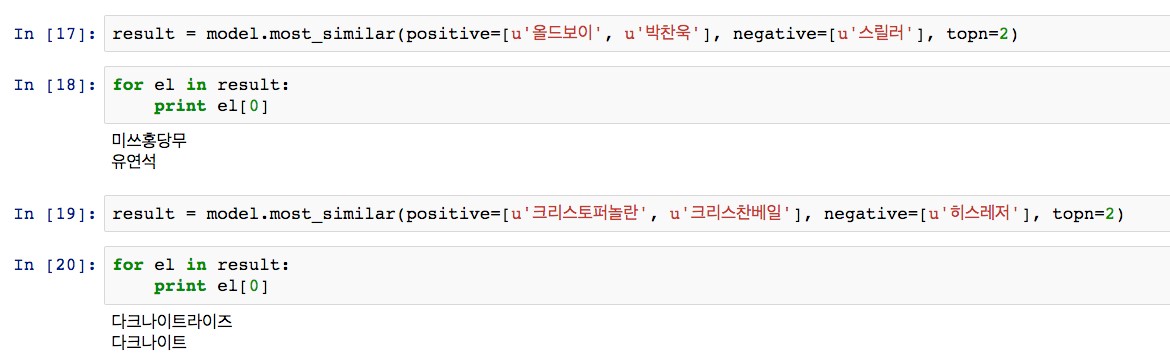
학습된 모델을 이용해 쿼리를 실행한 결과는 다음과 같다.
1. ‘올드보이’ + ‘박찬욱’ - ‘스릴러’ = ‘미쓰홍당무’
2. ‘크리스토퍼놀란’ + ‘크리스찬베일’ - ‘히스레저’ = ‘다크나이트라이즈’
Word2vec으로 학습시키는데 권장되는 데이터양보다 많이 부족한 상태였지만 상당히 그럴듯한 결과를 얻을 수 있었다.
이번 글에서는 Pandas, Numpy를 이용해 데이터를 가공하는 방법과 Word2Vec 라이브러리를 통해 단어 간의 관계를 알아보는 간단한 의미 분석 툴을 작성해봤다. 이제 우리는 어떠한 분석 알고리즘을 선정하더라도 당황하지 않게 됐다. 해당 알고리즘이 요구하는 형태가 무엇이든 해당 모양으로 원본 데이터를 가공할 수 있는 능력을 갖췄기 때문이다.
데이터와 분석 알고리즘이 모두 갖춰졌다면 우리가 할 일은 별로 없다. 시간과의 싸움만이 남았을 뿐이다. 다만, 시작하며 언급했듯이 실제 환경에서 분석 알고리즘의 선정은 크게 군집화(Clustering), 분류(Classification), 예측(Regression)이라는 범주 중 하나를 선택하게 된다. 범주를 정하는 것은 대부분의 경우 꽤 명확하므로 크게 어렵지 않지만, 범주내의 어떤 알고리즘을 어떤 데이터 형태를 입력값으로 설정해 사용(또는 학습)할 것인가는 많은 경험을 통해 얻을 수 있는 직관이 없다면 굉장히 난해한 경우가 많다.
즉, 데이터 분석의 전문가가 되기 위해서는 여러 가지 알고리즘을 다양한 모양의 데이터로 학습시켜보고 어떤 경우에 최적의 결과를 얻을 수 있는지 지속적으로 실험할 필요가 있으며, 앞으로의 글도 실제 환경에서 사용하는 예제를 통해 단순화시킨 이론을 소개하고 이를 토대로 실용적인 경험을 쌓는데 중점을 두고자 한다.