



데이터 가공 및 분석 (2)
[컴퓨터월드]

| 1. 데이터 수집 - 크롤링 소개, Scrapy 및 BeautifulSoup 사용방법 2. 데이터 저장 - EFK 스택 사용방법 3. 데이터 가공 및 분석 (1) 4. 데이터 가공 및 분석 (2) 5. 데이터 가공 및 분석 (3) |
지난 글에서 데이터 분석에는 군집화(Clustering), 분류(Classification), 예측(Regression) 등 세 개의 큰 범주가 있다고 언급한 바 있다. 이전 글에서 단어 간 의미를 분석해보기 위해 사용했던 Word2vec은 신경망(Neural net)을 이용해 단어(Vocabulary)를 벡터로 표현하는 방법으로, gensim 라이브러리에서 제공하는 Word2vec 모듈을 이용해 수십 줄의 코드만으로 원하는 결과(단어의 벡터화된 표현)를 얻을 수 있었다. Word2vec을 통해 얻은 결과를 K-Means 같은 군집화(Clustering) 모델에 바로 적용하면 손쉽게 단어의 의미별 군집을 얻을 수 있다.
이번 글에서는 나머지 두 개의 범주 중 하나인 예측을 선형회귀분석(Linear Regression) 모델을 이용해 사이트의 순수 방문자(Unique Visitor, 이하 UV)를 예측해보겠다. 이 글에서 사용된 코드는 http://github.com/haandol/regression 에서 확인할 수 있다. 사용된 데이터는 국내 모든 홈쇼핑 상품을 한눈에 볼 수 있는 ‘홈쇼핑모아’의 UV 트렌드를 반영한 데이터로, 저장소의 ‘df.csv’ 파일에 CSV(Comma Separated Values) 형태로 포함돼 있다.
선형회귀분석(Linear Regression)
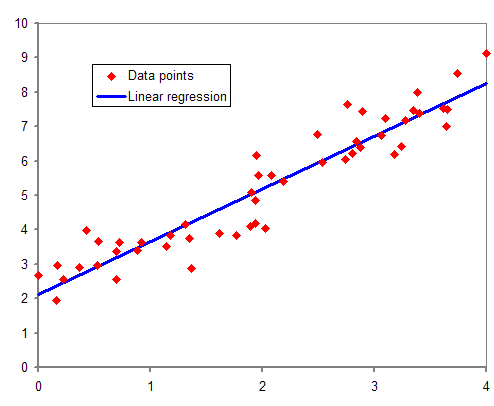
(출처: https://upload.wikimedia.org/wikipedia/commons/b/be/Normdist_regression.png)
선형회귀분석은 [그림 1]과 같이 주어진 데이터 집합(X)에 대해 가장 잘 설명할 수 있는 선형함수(H)를 구하는 것이다. 선형회귀분석의 알고리즘과 기계학습에서의 계산방법(Gradient Descent)은 코세라(Coursera)나 위키피디아 등 다양한 웹 문서에서 상세하게 설명하고 있으므로 이 글에서는 다루지 않겠다.
경험상 선형회귀분석은 다음의 2가지 경우에 주로 사용하게 된다.
1. 과거의 데이터를 바탕으로 미래의 데이터를 예측하고 싶은 경우
2. 주어진 여러 데이터들 중 어떠한 조합이 서로 관계있는지 확인하고 싶은 경우
경제학, 사회과학 등의 다양한 분야에서도 변수들 사이의 관계를 설명하고자 할 때 선형회귀분석을 사용하는데, 예를 들면 최저임금의 빅맥지수와 국민총행복지수와의 상관관계, 집에서 고압변전소까지의 거리와 기대수명의 상관관계, 키와 연봉의 상관관계 등을 알아보고 싶을 때 선형회귀분석을 통해 설명할 수 있다.
버즈니 활용사례 - 일일 UV 예측
그로스해킹(Growth Hacking)을 알고 있는가? △대행사를 통한 △감에 의한 △광범위한 전통적인 마케팅 방법이 아닌, △직접 △데이터에 기반을 둬 △효과적인 매체에 집중적으로 리소스를 투입하는 마케팅 기법을 그로스해킹이라고 한다.
국내 최대 모바일 홈쇼핑 포털 앱 ‘홈쇼핑모아’를 서비스 중인 버즈니도 그로스해킹을 통해 마케팅 전략을 수립해나가고 있다. ‘EFK’를 기반으로 거의 모든 사용자의 행동을 수집하고 있는 버즈니는 광고매체나 광고소재 등록, UI/UX 변경, 검색 랭킹 알고리즘 튜닝 등의 변경을 실시한 후 항상 사용자 클릭률, 이탈률 등을 모니터링하고 피드백을 얻어 다음 수정에 반영하고 있다.
특히 이탈률, 잔존율 그리고 UV는 회귀분석을 통해 어느 정도 예측 가능한 수치다. 특정 시간의 해당 수치가 평소 보이던 패턴과 크게 차이난다면, 수정한 기능 중 일부가 제대로 동작하지 않거나 사용자를 불편하게 만들었다는 것을 알 수 있게 된다. 예로 검색랭킹 알고리즘을 수정하고 얼마 안 있어 검색 클릭률 추이를 보면 직전 수정한 랭킹알고리즘의 문제점을 발견할 수 있다. 또 배너 문구를 바꾼 뒤 배너 클릭률 추이를 확인해 어떤 문구가 타깃 사용자에게 더 효과적인지 확인하기도 한다.
이처럼 그로스해킹은 스타트업의 소중한 리소스를 효과적으로 사용할 수 있도록 도와주는 유용한 도구이며, 이것을 잘 이용하기 위해서는 필요한 데이터를 구조화시켜 저장하고 분석할 수 있는 능력이 필요하다.
Scikit-learn.LinearRegression
시작하며 언급한대로 선형회귀분석 모델을 이용해 ‘오늘 15시의 UV가 [X]명이라면 23시의 UV는 어떻게 될까?’를 예측해보자. 선형회귀분석 모델은 주어진 데이터들을 가장 잘 설명하는 하나의 선형함수를 찾는 알고리즘으로, 가장 단순한 형태의 기계학습 모델 중 하나다.
가장 단순한 모델이라고 하더라도 모델을 구성하는 알고리즘을 이해하고 평가함수(Activation Function)를 선정하고 경사하강법(Gradient Descent)을 직접 구현하는 것은 적지 않은 노력을 요구하는 일이다. 하지만 다행스럽게도 대부분의 기계학습 모델은 이론적으로 거의 완성돼 있어 해당 모델을 미리 구현해둔 라이브러리들이 이미 존재한다. 그뿐만 아니라 해당 라이브러리들은 모델에 대한 개략적인 이해도만 있으면 손쉽게 사용할 수 있다.
이 글에서는 기계학습에서 가장 많이 사용하는 오픈소스 라이브러리 중 하나인 사이킷런(Scikit-learn, 이하 sklearn)을 사용해본다. 해당 라이브러리에는 다양한 기계학습 모델들뿐만 아니라 카운터벡터라이저(Counter-Vectorizer)와 같은 벡터화 도구, PCA(Principal Component Analysis)와 같은 차원축소(Dimensionality Reduction) 알고리즘 등 기계학습에 필요한 다양한 도구들도 함께 제공되고 있다.
데이터 가져오기
엘라스틱서치(ElasticSearch)를 통해 데이터를 가져와보자. 엘라스틱서치에서 데이터를 가져오는 방법은 다양하지만, 키바나(Kibana)를 통해 가져오는 것이 가장 쉽고 편리하다. 키바나를 통해 데이터를 가져오는 순서는 다음과 같다.
1. 키바나 쿼리를 이용해 원하는 데이터를 화면에 표시한다.
2. 화면에 표시된 데이터가 실시간일 필요가 없는 경우 CSV로 데이터를 내보낸다.
3. 실시간 데이터를 분석할 경우에는 현재 데이터를 볼 수 있는 쿼리(query DSL)를 생성해 엘라스틱서치에 직접 데이터를 요청한다.
‘최근 5분간 전체 사이트 접속로그 중 user_id 필드를 유니크 키로 계산한 UV’와 같은 데이터는 query DSL로 직접 만들기 복잡할 수 있다. 하지만 키바나를 이용하면 현재 내가 보고 있는 데이터를 가져올 수 있는 복잡한 query DSL을 자동으로 생성하거나 해당 데이터를 CSV 형태로 내려 받을 수 있다.
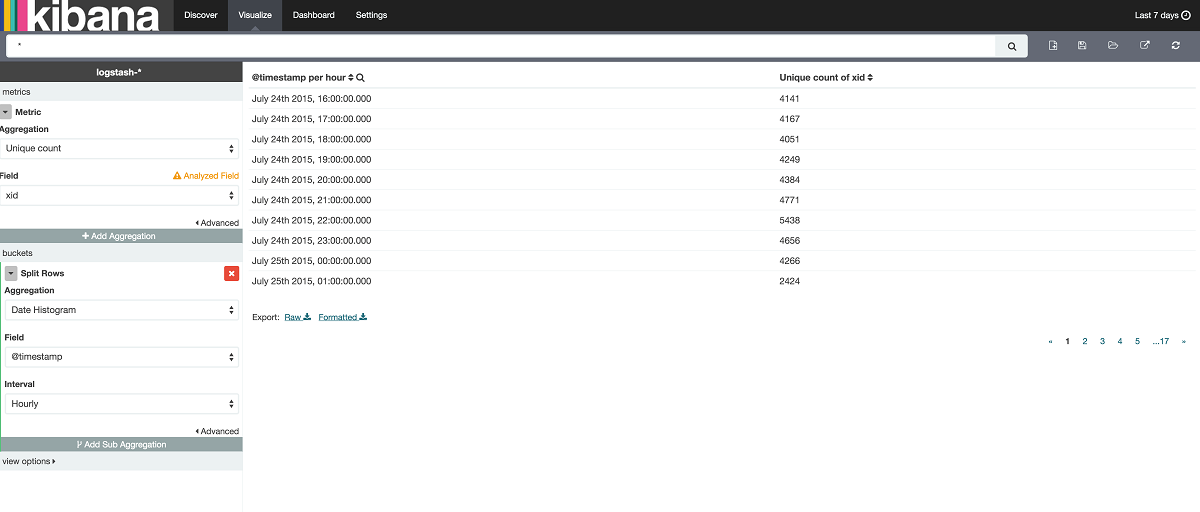
그럼 CSV로 내려 받은 일시별 UV 데이터를 사용할 수 있는 객체로 불러와보자. 지난 글에서 소개한대로 Pandas를 이용하면 DataFrame 객체로 손쉽게 데이터를 가져올 수 있다. 이렇게 가져온 데이터는 시작하며 언급한 깃허브(GitHub) 저장소에 ‘df.csv’ 파일로 공개해뒀다.
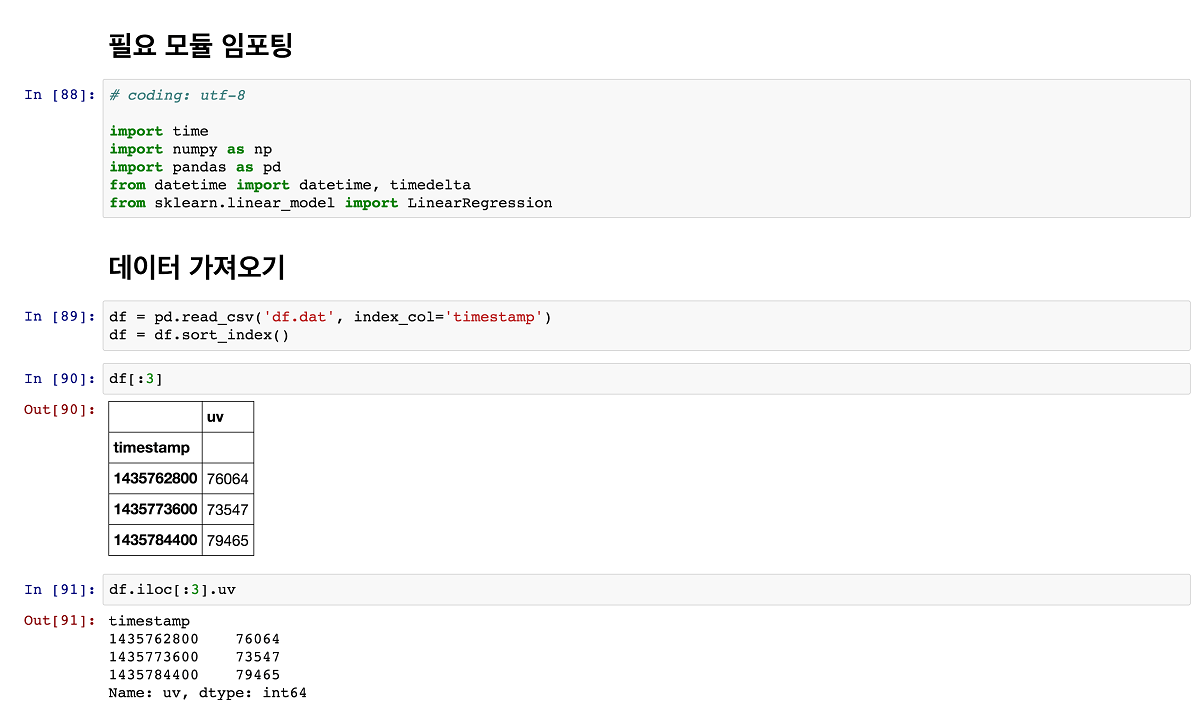
데이터 가공 및 모델 학습
데이터를 가져왔으니 모델에 맞게 가공해 학습을 시켜보자. 우리가 학습시킬 모델인 회귀분석 모델은 지도학습(Supervised Learning) 방법 중 하나다. 지도학습 방법이란 학습데이터에 원하는 결과를 포함시켜 모델을 학습시키는 방법으로, 유추된 함수의 결과값이 연속적(Continuous)이면 회귀분석(Regression)이라고 하고 이산적(Discrete)이면 분류(Classification)라고 한다.
우리의 목표는 특정 시간대까지의 누적 UV를 입력했을 때 하루 전체 UV를 예측하는 것이다. 이를 위해서는 ‘각 시간대별 누적 UV’를 구해 학습데이터로 전달해야 한다. 그리고 지도학습의 특성상 우리가 원하는 결과인 ‘해당 일자의 총 UV’도 학습데이터와 함께 제공돼야 한다.
현재 우리가 가진 데이터의 인덱스(Index)인 타임스탬프(TimeStamp)는 2015년 7월 2일부터 2015년 7월 24일까지의 날짜별 UV 데이터로, 각 날짜는 다시 0시부터 21시까지 3시간 간격으로 구성돼 있다. 따라서 날짜별로 각 시간대별 누적 UV 정보를 학습데이터로 가공해야 한다. 단, 편의를 위해 21시까지의 누적 UV를 하루 전체 UV로 가정하고 진행하겠다.
더 진행하기 전에 한 가지 생각해볼 점이 있다. 이 글에서는 설명의 편의를 위해 하나의 모델에서 모든 시간에 대한 UV를 처리하는 것이 아니라 각 시간대별 모델을 따로 만들고 있다. 하지만 학습데이터를 어떻게 구성하느냐에 따라 하나의 모델에서 모든 시간에 대한 처리를 할 수도 있고 또 다른 방식을 취할 수도 있다. 데이터를 분석하기 전에 분석 목적과 모델의 사용방법을 고려해 적절한 형태로 학습데이터를 가공하는 것이 상당히 중요하다.
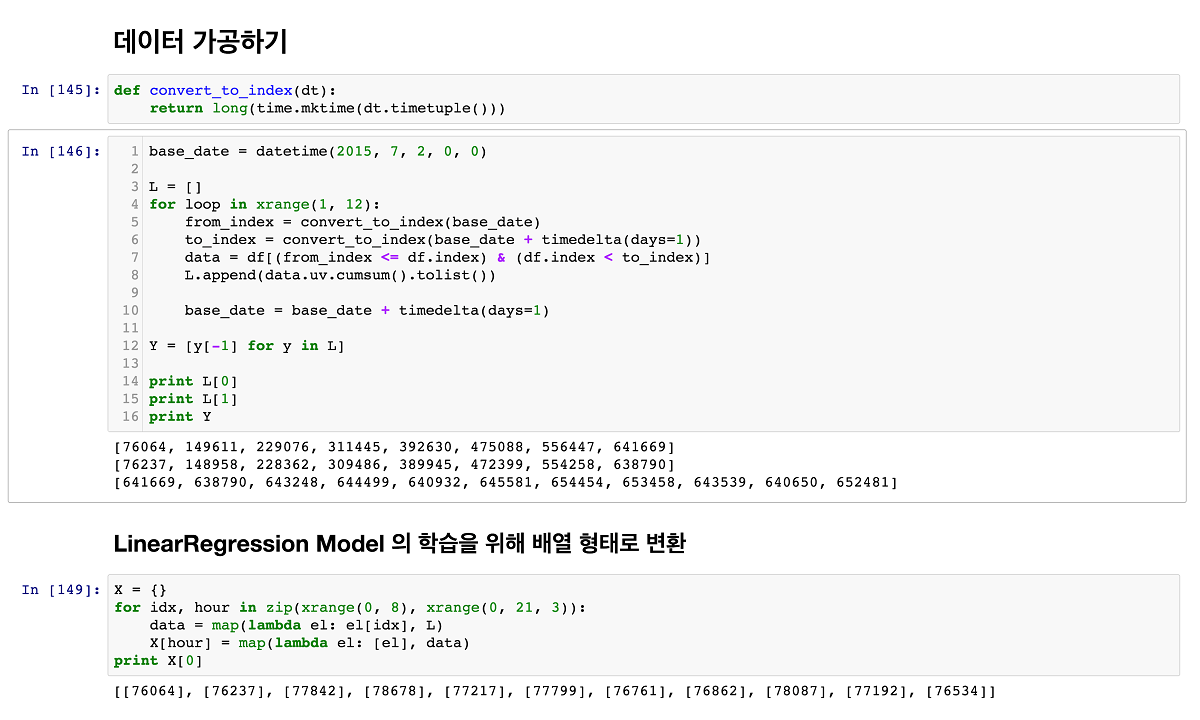
[그림 4]는 학습데이터를 가공하는 코드다. 코드에 어려운 기능이나 난해한 알고리즘을 사용한 부분은 없기 때문에 꼼꼼히 읽기만 하면 쉽게 이해할 수 있을 것이다. 절차는 다음과 같다.
1. index를 필터링하기 위해 datetime 형태의 날짜를 timestamp 형태로 변경할 수 있는 convert_to_index 함수를 선언한다. (첫 번째 섹션)
2. 각 날짜별로 index를 필터링한다. (두 번째 섹션 5~7 라인)
3. pandas.DataFrame의 cumsum 명령을 통해 uv 필드의 각 시간별 누적 UV 리스트를 만든다. (8 라인)
4. 23시의 누적데이터를 우리가 원하는 데이터인 하루 전체 UV로 저장한다. (12 라인)
사실 여기까지만 하면 될 것 같지만, sklearn의 모델들은 배열(벡터) 형태의 데이터를 입력값으로 요구하는 경우가 많다. 여기서 사용할 LinearRegression 모델도 마찬가지다. 따라서 시간대별 학습데이터를 기본형(primitive)인 Integer형에서 배열(List)형으로 변경해줘야 한다. [그림 4]의 세 번째 섹션에서 해당 처리를 하고 있다.
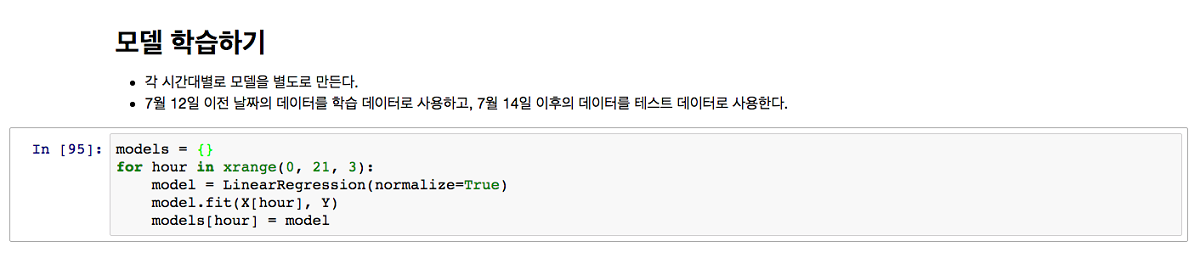
데이터가 준비됐으면 학습은 정말 쉽다. LinearRegression.fit() 함수에 학습데이터를 입력해주면 모든 학습이 시작된다. 본 예제의 경우에는 학습데이터가 수백 개 내외이기 때문에 거의 즉시 완료된다.
모델을 이용해 UV 예측
우리는 잘 학습된 각 시간대별 모델을 갖게 됐다. 그런데 각 모델이 잘 학습됐는지 어떻게 확인할 수 있을까? 선형모형이 주어진 자료에 적합한지 확인하는 일반적인 방법으로 결정계수(Coefficient of determination)가 있다. LinearRegression 모델의 경우에는 score라는 함수를 통해 결정계수를 구할 수 있다. 즉, score 결과가 낮을수록 유효하지 않으며, 1에 가까울수록 유효한 모델이라고 볼 수 있다.
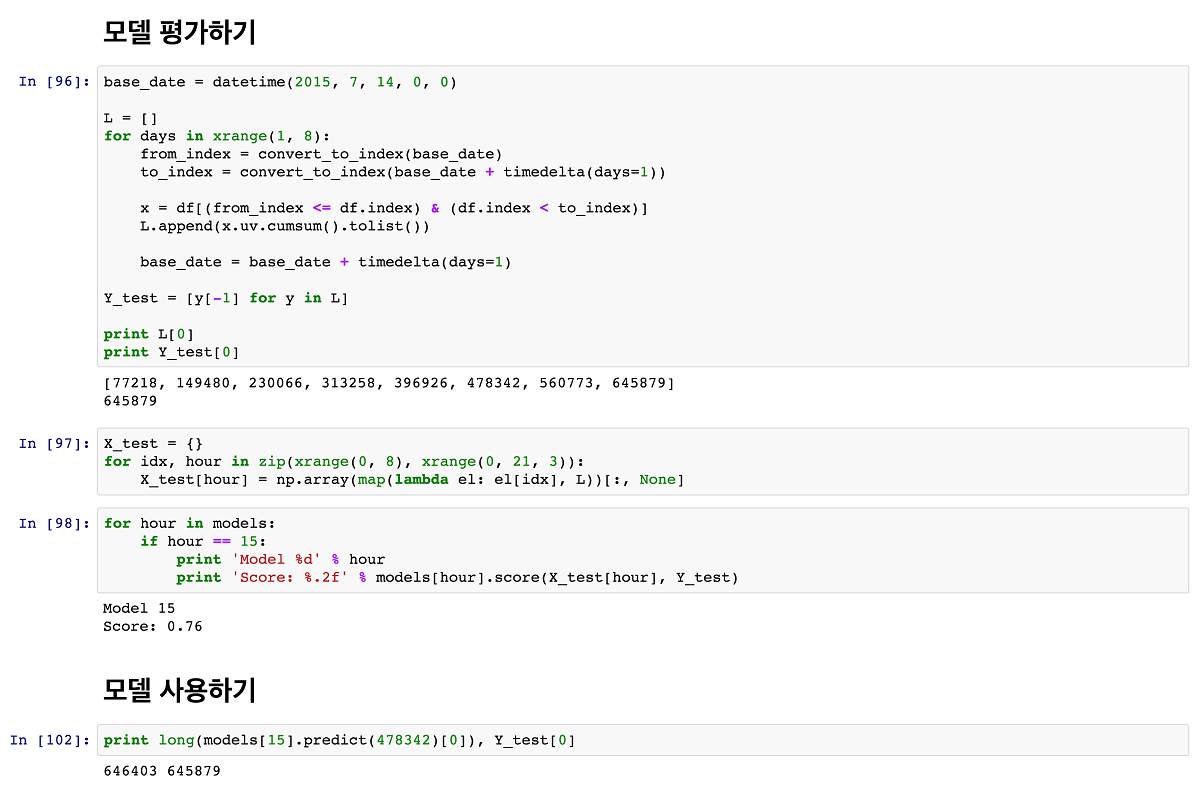
이제 학습도 끝났으니 해당 모델과 테스트 데이터를 갖고 일일 UV를 예측해보자. 오늘 15시의 UV가 478,342명이라면, 23시의 UV는 어떻게 될까?
모델을 학습시켰으면 [그림 6]과 같이 predict 명령을 통해 예측결과를 확인할 수 있다. 15시 데이터를 학습시킨 모델에 15시까지의 누적 UV인 ‘478,342’를 입력하면 그날 전체 UV를 예측해준다. 모델이 예측한 하루 UV는 646,403명이며, 실제로 해당 날짜의 UV는 645,879명이었다. 시간대별 누적 UV를 통해 예측한 결과값이 실제 하루 UV 값과 거의 일치한다는 것을 알 수 있다.
이번 글에서는 선형회귀분석 모델을 통해 일일 UV를 예측해봤다. 예측방법은 실제 서비스 운영에서 서비스의 일/주/월 단위 UV를 예측하거나, 데이터의 비정상패턴(Anormal)을 분석하는 등 유용하게 사용할 수 있다.
‘망치든 사람 눈에는 못만 보인다’고 했던가? 개인적으로는 처음 회귀분석을 알게 됐을 때는 눈에 보이는 모든 데이터를 회귀분석으로 분석해보고 싶어 이것저것 시도해봤으나 잘 되지 않았다. 우리가 실제로 겪는 문제는 선형적인 예측결과가 아니라, 비선형적이고 이산적인 결과가 필요한 경우가 훨씬 많기 때문이다.
예를 들면 ‘사용자의 행동 A, B, C에 대해 B-C-A라는 행동패턴을 가진 사용자는 남자일까 여자일까?’, ‘홈쇼핑사에서 가져온 X라는 상품은 [여성속옷]과 [남성속옷] 중 어떤 카테고리에 속하는가?’와 같은 문제들은 연속적인 결과를 얻을 수 있는 회귀분석으로 해결하기 상당히 난해하다. [남자 or 여자] 또는 [남자속옷 or 여성속옷]과 같은 이산적인 결과가 필요하기 때문이다.
이렇게 이산적인 결과를 얻어야 할 경우에 주로 사용되는 방법이 바로 분류(Classification) 방법이다. 다음 글에서는 비선형 함수를 이용한 SVM(Support Vector Machine) 모델을 사용해 간단한 분류문제를 해결해보도록 하겠다.