



데이터 가공 및 분석 (3)
[컴퓨터월드]

| 1. 데이터 수집 - 크롤링 소개, Scrapy 및 BeautifulSoup 사용방법 2. 데이터 저장 - EFK 스택 사용방법 3. 데이터 가공 및 분석 (1) 4. 데이터 가공 및 분석 (2) 5. 데이터 가공 및 분석 (3) |
지금까지의 글에서는 Word2Vec을 이용한 군집화(Clustering) 일부와, 선형회귀분석(LinearRegression)을 이용한 예측(Regression)을 살펴봤다. 지난 글에서 잠깐 언급한 것처럼, 일반적인 서비스 운영에 기계학습을 적용할 경우 가장 많이 다루게 되는 범주는 분류(Classification)이다. 예로 서비스 운영 및 기획에서 흔히 사용하는 ‘예측’이라는 단어는 사실 기계학습에서는 ‘분류’로 다루는 경우가 많다.
사용자가 검색한 쿼리를 보고 남자인지 여자인지를 ‘예측한다’거나, 사용자의 행동패턴을 통해 사용자가 봇(Bot)인지 ‘예측한다’거나, 또는 상품의 상세정보로 상품의 카테고리를 ‘예측한다’고 표현한다. 하지만 실제 기계학습에서는 사용자를 남자와 여자로 ‘분류’하고, 봇과 사람으로 ‘분류’하며, 상품을 8개의 카테고리 중 어디에 속하는지 ‘분류’하게 된다.
이번 글에서는 서포트 벡터 분류기(Support Vector Classifier, 이하 SVC)를 통해 상품의 이름만으로 ‘가전/디지털’, ‘식품/건강’, ‘화장품/미용’, 3개의 카테고리를 ‘예측’해보는 분류(Classification) 문제를 해결해본다. 이 글에서 사용된 코드는 http://github.com/haandol/svc에서 확인할 수 있으며, 사용된 데이터는 국내 모든 홈쇼핑 상품을 한눈에 모아서 볼 수 있는 ‘홈쇼핑모아’의 검색 패턴을 반영한 데이터로 저장소의 ‘df.csv’ 파일에 CSV(Comma Separated Values) 형태로 포함돼 있다.
서포트 벡터 머신(Support Vector Machine)
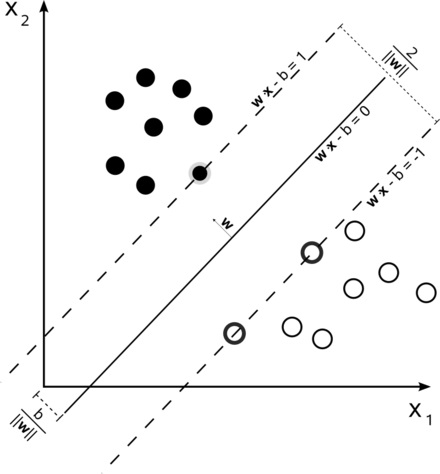
[그림 1]은 2차원으로 표현된 벡터공간이며, 각 분류의 경계선에 가장 가까이 있는 벡터(그림에서 굵은 테두리를 가진 벡터)를 서포트 벡터라고 부른다. 서포트 벡터 머신(Support Vector Machine, 이하 SVM)은 분류될 이런 서포트 벡터간의 거리(마진)를 최대화해 데이터들을 분류하는 모델로, 주로 분류와 회귀분석에 사용된다.
SVM은 최적의 분리경계면(maximum-margin hyperplane) 을 기반으로 분류하며, 특히 선형 SVM의 경우 긍정/부정 분류 등 2개의 그룹에 대한 분류작업 시 결정트리(Decision Tree)나 신경망(Nueral Network) 모델보다 분류율이 높은 것으로 알려졌다.
그뿐만 아니라 분류 결과에 대한 해석이 용이하고, 적은 학습자료만으로 신속하게 분류를 할 수 있는 장점도 갖고 있다. 선형 함수를 이용한 선형 SVM과 비선형 커널 함수를 이용한 비선형 SVM이 있으며, 본 글에서는 선형 SVM을 이용한 분류 문제를 풀어본다. SVM에 대한 더 자세한 내용은 위키백과와 이곳을 참고하길 바란다.
버즈니 활용사례 - 카테고리 분류
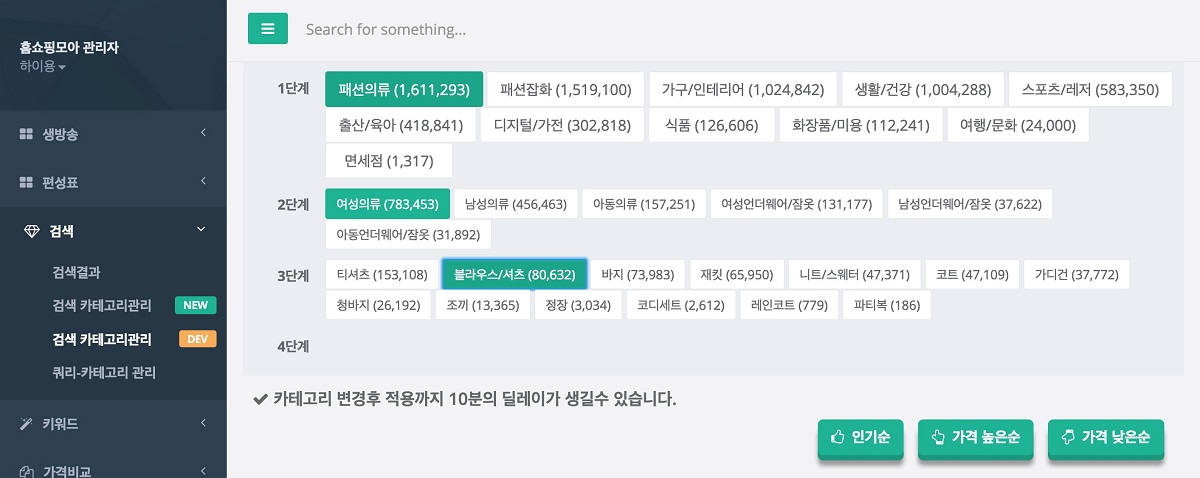
버즈니에서는 현재 국내 모든 홈쇼핑 상품을 한곳에 모아서 볼 수 있는 ‘홈쇼핑모아’를 서비스 중이다. ‘홈쇼핑모아’는 국내 6개 홈쇼핑사의 방송정보를 한데 모은 통합편성표 및 상품정보를 가져와 검색할 수 있는 검색서비스를 제공하고 있다. 카테고리 정보는 가장 중요한 데이터 중의 하나로, 검색품질과 편성표 검색 등 사용자의 행동들과 밀접한 관련이 있다.
홈쇼핑 업체별로 각기 다른 분류체계를 가지고 있으며, ‘홈쇼핑모아’는 사용자에게 통합된 정보를 제공하기 위해 자체적인 카테고리 체계로 재분류하는 작업을 처리하고 있다. 현재 ‘홈쇼핑모아’의 상품분류 카테고리 체계는 세 단계 깊이로 이뤄진 약 1,500개의 카테고리로 구성돼 있으며, 이를 재분류하는 작업을 SVM, 딥러닝 등의 다양한 기계학습 모델을 이용해 진행하고 있다.
Scikit-learn.LinearSVC
그럼, 상품의 이름만으로 ‘가전/디지털’, ‘식품/건강’, ‘화장품/미용’ 3개의 카테고리를 ‘예측’해보는 분류(Classification) 문제를 해결해보자. 이 글에서는 분류문제를 해결하기 위해서 SVM 모델을 선택했다.
한편, SVM은 그 범용성만큼이나 라이브러리 선택 폭도 상당히 넓다. scikit-learn, libsvm, svmlight, opencv 등의 오픈소스 라이브러리에서 SVM 모델을 지원하고 있다. 이 글에서는 scikit-learn에서 제공하는 선형 SVM 분류 모델인 LinearSVC를 사용한다. 해당 모델은 비선형 모델보다 학습속도가 빠르며, 적은 데이터에서도 괜찮은 성능을 얻을 수 있다.
데이터 가져오기
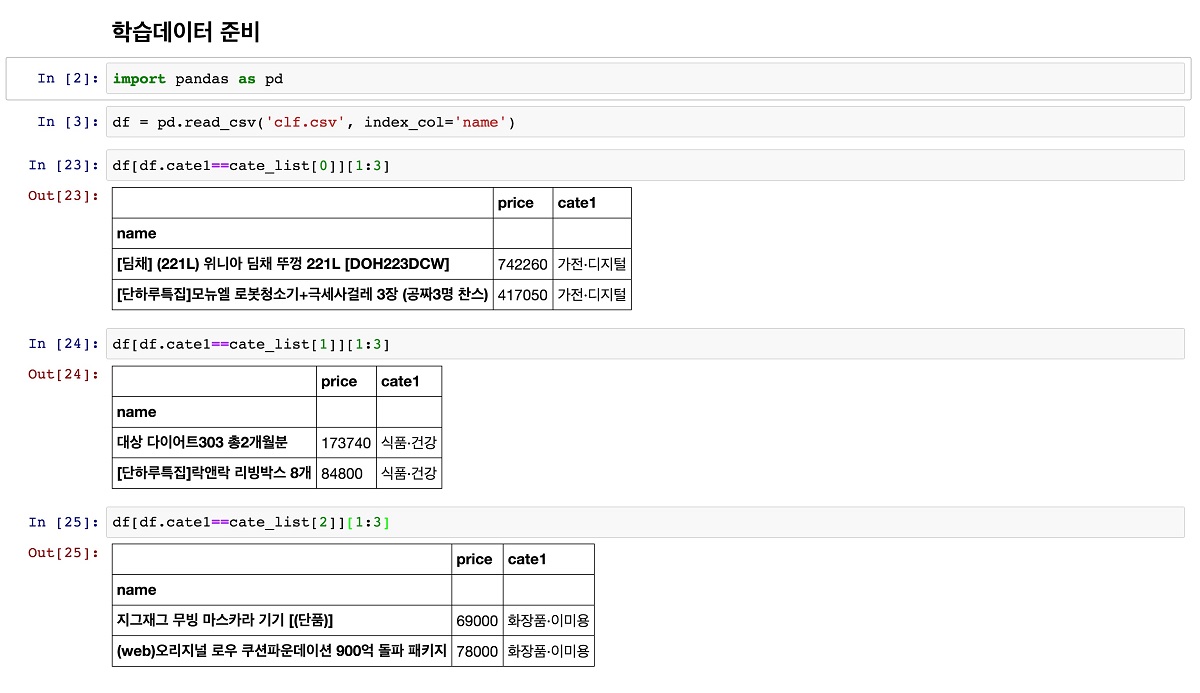
편의를 위해 ‘clf.csv’ 파일 안에 상품정보를 CSV 형태로 넣어뒀다. 이 파일에는 3개의 카테고리별로 500개씩 총 1,500개의 정보가 저장돼 있다. 상품정보를 가져오기 위해 pandas를 이용하겠다. pandas의 read_csv 함수를 이용하면 손쉽게 csv 파일 내용을 DataFrame 형태로 가져올 수 있으며, DataFrame은 DB의 테이블처럼 쉽게 데이터를 가공할 수 있게 도와준다.
데이터 가공 및 모델 학습
SVM은 ‘서포트 벡터’ 간의 여백(margin)을 최대화하는 분류 모델로, 우리가 가진 학습데이터들인 상품명은 벡터로 변환될 필요가 있다. 문자열을 벡터로 변환하는 가장 간단한 방법이자 일반적인 방법의 하나로 전체 상품명 크기의 매트릭스에 카운트를 채워 넣는 방법이 있다.
이 방법에서, ‘star wars’라는 단어가 있다면 벡터의 차원은 유일 글자(unique character, 여기서는 ‘star w’)의 개수인 6차원이 되며, 실제 모양은 ‘star w’ 글자의 각 등장 횟수인 [‘2’, ‘1’, ‘2’, ‘2’, ‘1’, ‘1’] 이 된다. scikit-learn에서는 문자열을 갖고 이 같은 매트릭스를 쉽게 만들어주는 모듈인 CountVectorizer를 제공하고 있다.
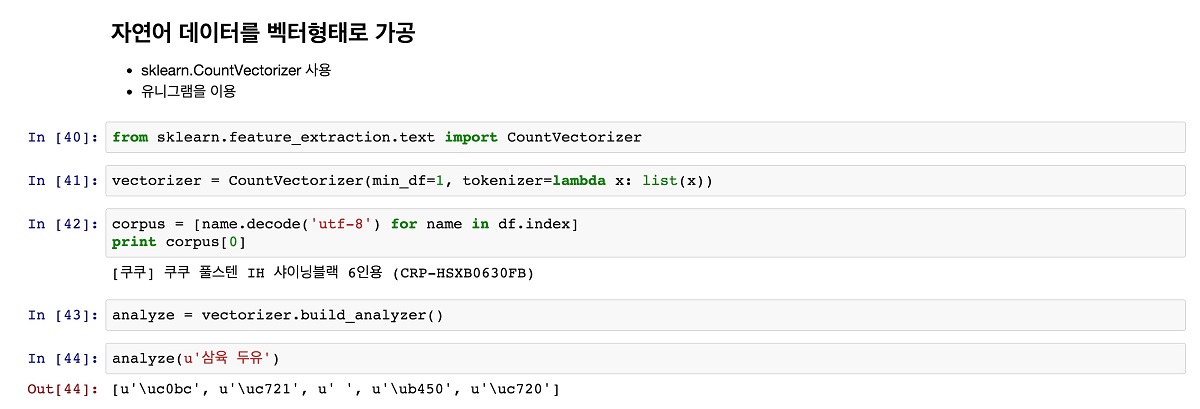
[그림 4]는 CountVectorizer를 이용해 매트릭스로 변환해 corpus라는 이름으로 저장하는 과정을 보인다. vectorzier가 입력하는 문자열을 잘 저장하는지 확인해보려면 vectorizer.build_analyzer() 모듈을 사용한다. 이를 이용해 샘플 문자열을 입력해보고 원하는 대로 문자가 분해(tokenize)되는지 확인해봐야 어떠한 기준으로 벡터가 생성될지 가늠해볼 수 있다.
문자의 분해 시 이 글에서는 코드의 단순화를 위해 입력문자를 한 글자씩 잘라서 사용하는 유니그램(uni-gram) 방식을 썼지만, 실제로는 두 글자(bi-gram)나 세 글자(tri-gram)씩 잘라서 사용하는 방식을 많이 사용한다.
모델을 이용해 사용자 분류
학습데이터는 크게 특징(feature)이라고 부르는 벡터화된 상품 이름들과 클래스라고 부르는 각 상품별 카테고리로 구분되며, 일반적으로 특징은 X, 클래스는 Y로 표현한다. 특징이 500개라면 클래스도 500개가 존재해야 하며, 특징과 클래스의 순서가 일치해야 한다.
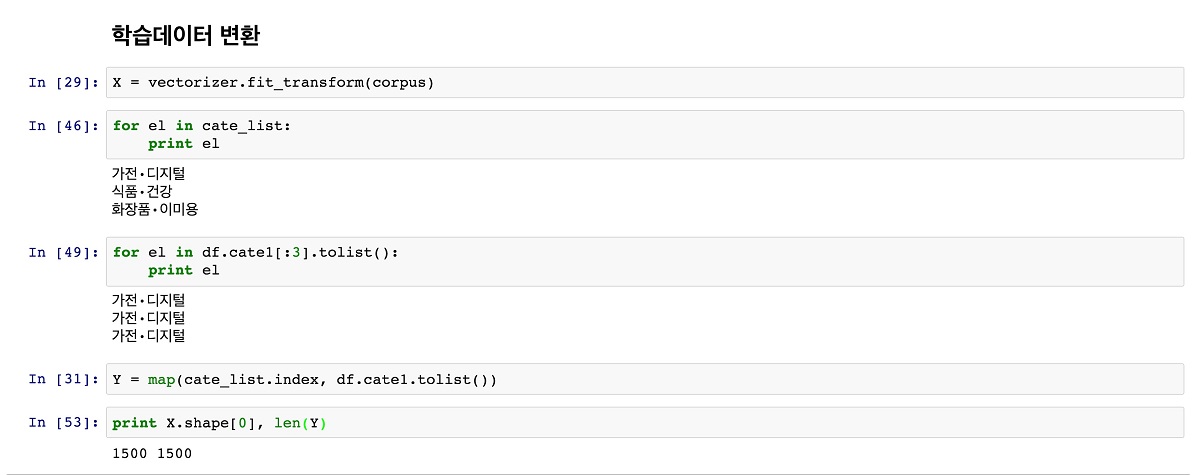
먼저 CountVectorizer의 fit_transform 함수를 호출해, 전에 만들어둔 상품명 목록인 corpus를 특징 매트릭스 X로 변환한다. 그리고 DataFrame에서 카테고리의 인덱스를 벡터(배열)로 변환해 Y에 저장한다.
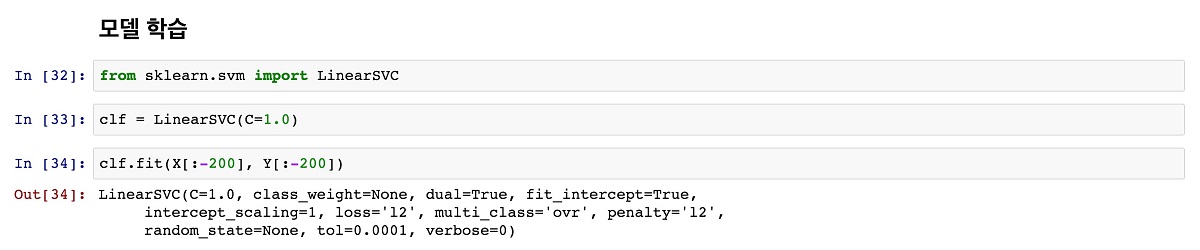
학습데이터 X와 Y가 구해졌으니 모델을 학습해보자. LinearSVC 모듈을 임포트해 fit() 함수를 호출하면 학습이 완료된다. 이때 전체 학습데이터인 1,500개를 다 사용하지 않고 1,300개만으로 학습을 한다. 남은 200개의 데이터는 우리가 학습시킨 분류기가 제대로 작동하는지 평가하는데 사용하기 위해서다.
마지막으로 우리가 학습시킨 분류기 모델이 어느 정도의 성능을 보이는지 평가해보자. 대부분의 경우 학습시킨 모델이 정상적으로 작동하는지 평가하는 과정이 더 중요하다고 말한다. 특정한 상품에 대해 성능이 충분히 나오지 않아서 학습데이터를 변경할 경우, 적절한 평가지표가 없다면 기존 정상 작동하던 다른 부분들이 망가지는 것을 확인하기가 힘들기 때문이다.
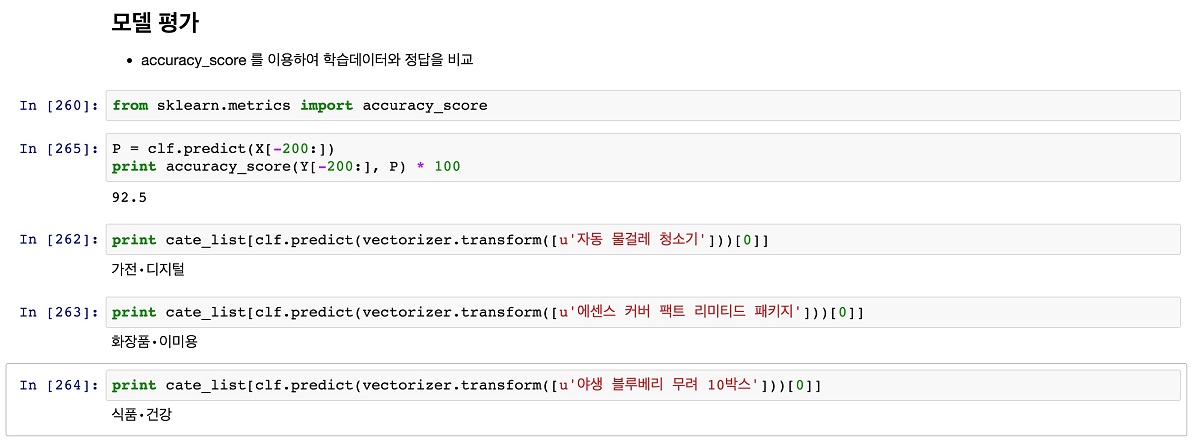
실제로 scikit-learn에서는 모델 평가를 위해 다양한 모듈들을 제공하고 있다. 이 글에서는 accuracy_score를 이용해 정확도를 간단히 평가하도록 해본다. 먼저 아까 남겨둔 200개의 평가용 X 데이터로 우리가 학습시킨 분류기 모델에 predict() 함수를 호출해 예측결과인 P를 얻는다. 이 데이터의 실제 카테고리인 200개의 평가용 Y 데이터와 모델 예측결과인 P를 이용해 accuracy_score 함수를 호출하면 정확도를 얻을 수 있다.
우리가 학습한 모델의 정확도는 대략 92.5%이며, 데이터가 적다는 것을 고려했을 때 나쁘지 않은 수치라고 볼 수 있다. 실제로 데이터에는 없지만, 존재하는 상품인 ‘자동 물걸레 청소기’, ‘에센스 커버 팩트 리미티드 패키지’, ‘야생 블루베리 무려 10박스’ 등을 입력했을 때 각각 ‘가전·디지털’, ‘화장품·미용’, ‘식품·건강’으로 정확하게 분류하는 것을 확인할 수 있다.
연재를 마치며
이번 글에서는 상품의 이름만으로 ‘가전/디지털’, ‘식품/건강’, ‘화장품/미용’, 3개의 카테고리를 ‘예측’해보는 분류 문제를 SVM 모델을 이용해 해결해봤다.
(출처: http://scikit-learn.org/stable/tutorial/machine_learning_map/index.html)
지금까지의 글을 통해 기계학습을 이용해 대규모 데이터 분석에 필요한 기본기를 갖추게 됐다. 기계학습을 이용해 데이터를 분석할 때 얻을 수 있는 가장 큰 장점은 데이터 자체에 집중할 수 있다는 점이다. 데이터의 어떤 부분을 특징으로 삼을 것인가와 해당 특징을 어떤 형태로 구성해 학습시킬 것인가만 결정하면 기계가 알아서 최적의 방법을 찾아준다. 최근 떠오르고 있는 딥러닝에서는 한발 더 나아가 어떠한 특징을 추출해야 하는지조차 기계가 찾아내기도 한다.
버즈니에 입사한 뒤 가장 놀랐던 점은 정말 다양한 곳에 기계학습이 활용되고 있다는 점과, 이러한 기계학습을 활용한 데이터 분석이 생각만큼 어렵지 않다는 사실이었다. 얼마 전까지만 해도 일부 전문가들의 전유물이었던 기계학습 모델들이 성숙하고 풍부한 오픈소스 덕분에 글쓴이와 같은 평범한 개발자들도 손쉽게 사용할 수 있으며, 최근엔 최신 기술이라고 불리는 딥러닝도 간편하게 쓸 수 있게 됐다.
이렇듯 누구나 기계학습을 사용할 수 있게 되면서 가장 중요한 것은 경험과 평가방법이 됐다. 어떠한 모델을 사용할 것인가와 어떤 특징을 어떤 형태로 구성할 것인가는 경험을 통해서만 얻을 수 있는 지식이며, 이렇게 얻은 경험이 올바른 것인가를 판단하는 기준은 평가방법이기 때문이다. 현재 버즈니에서도 다양한 모델과 데이터를 갖고 실험을 거듭하고 있으며, 노하우가 축적될수록 서비스의 품질이 향상되는 것을 평가를 통해 확인하고 있다.
모쪼록 이 연재가 기계학습을 통한 데이터 분석에 첫발을 내딛는 사람들에게 작은 도움이 되길 바란다.